Neural-MedBench
收藏arXiv2025-09-26 更新2025-09-30 收录
下载链接:
https://neuromedbench.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
Neural-MedBench是一个专注于神经学的推理密集型基准数据集,它整合了多序列MRI扫描、结构化电子健康记录和临床笔记,涵盖了三个核心任务家族:鉴别诊断、病变识别和理由生成。数据集包含120个专家注释的多模态案例,共200个推理密集型任务。该数据集旨在评估和测试医学视觉语言模型在深度推理方面的能力,并为未来的基准测试提供指导。
Neural-MedBench is a reasoning-intensive benchmark dataset focused on neurology. It integrates multi-sequence MRI scans, structured electronic health records (EHRs), and clinical notes, covering three core task families: differential diagnosis, lesion detection, and rationale generation. The dataset contains 120 expert-annotated multimodal cases, totaling 200 reasoning-intensive tasks. This dataset aims to evaluate and test the capabilities of medical vision-language models in deep reasoning, and provide guidance for future benchmark studies.
提供机构:
广东智能科学与技术研究院,珠海,广东,中国
创建时间:
2025-09-26
原始信息汇总
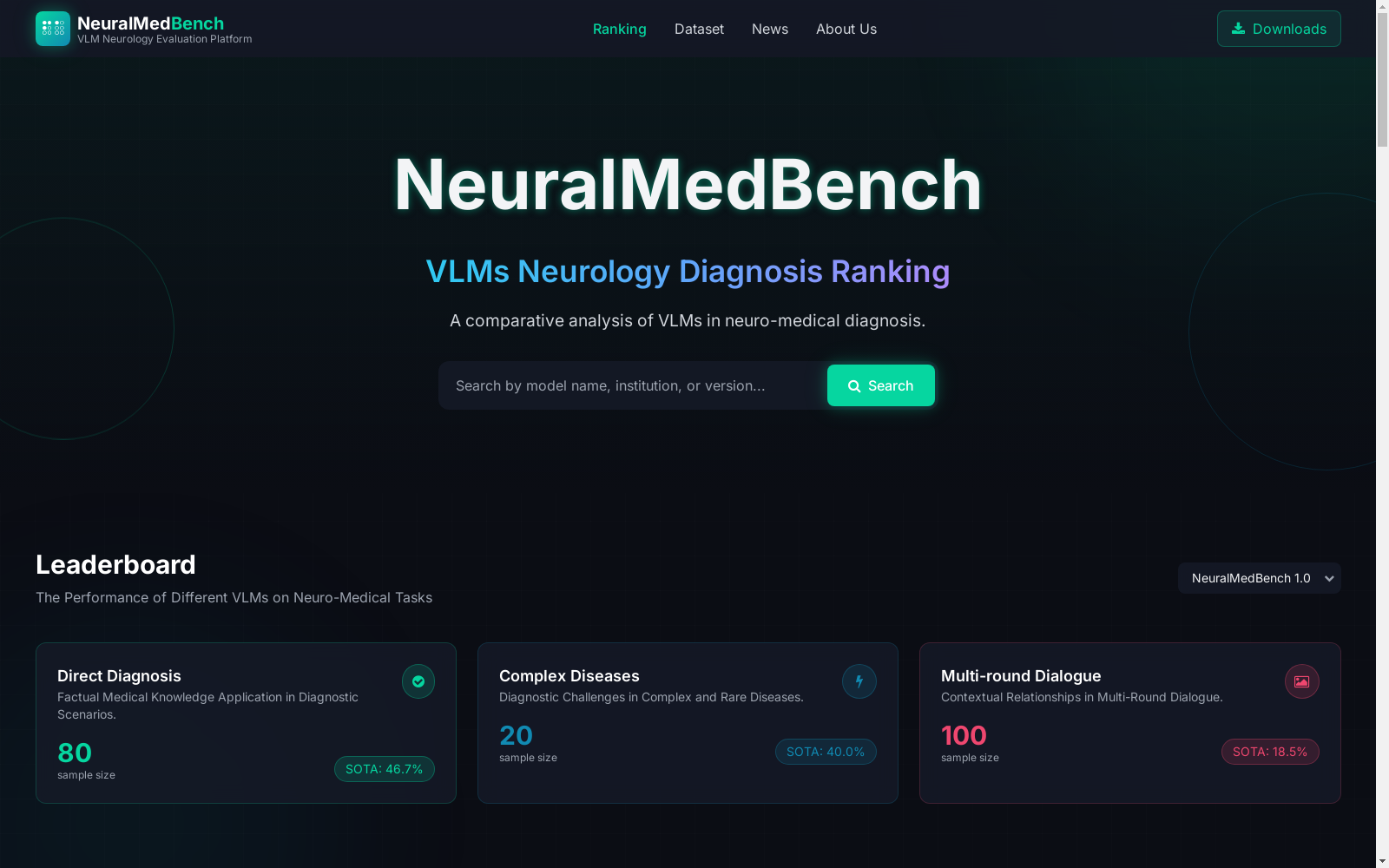
NeuralMedBench 数据集概述
数据集简介
- 名称: NeuralMedBench
- 定位: VLM神经学评估平台
- 用途: 神经医学诊断中视觉语言模型的比较分析
数据集版本
NeuralMedBench 1.0
任务类型
-
直接诊断
- 样本量: 80
- 特点: 在诊断场景中应用事实医学知识
- SOTA性能: 46.7%
-
复杂疾病
- 样本量: 20
- 特点: 复杂和罕见疾病的诊断挑战
- SOTA性能: 40.0%
-
多轮对话
- 样本量: 100
- 特点: 多轮对话中的上下文关系
- SOTA性能: 18.5%
NeuralMedBench 2.0
- 状态: 开发中
- 特点: 扩展的任务集和指标,专为神经医学多模态推理设计
排行榜性能
模型排名(基于准确率@Pass1)
| 排名 | 模型 | 模型大小(B) | 准确率(@Pass1) | 准确率(@Pass5) |
|---|---|---|---|---|
| 1 | Claude 4 Sonnet | 75B | 30% | 36.7% |
| 2 | Gemini 2.5-Flash | 180B | 26.7% | 46.7% |
| 3 | GPT-4o 2025-03-26 | 180B | 20% | 36.7% |
| 4 | Gemini 2.0-Flash | 120B | 20% | 30% |
| 5 | Claude 3.7 Sonnet | 80B | 16.7% | 26.7% |
| 6 | MedGemma-27B-it | 75B | 16.7% | 43.3% |
| 7 | Qwen-VL-2.5-32B | 110B | 10% | 30% |
| 8 | LLaVA-Med-7B | 90B | 10% | 16.7% |
| 9 | HuatuoGPT-7B | 75B | 10% | 20% |
| 10 | Claude 3.5 Sonnet | 150B | 6.7% | 16.7% |
| 11 | Doubao-1.5-vision-pro | 130B | 6.7% | 40% |
| 12 | RadFM-14B | 60B | 0% | 20% |
| 13 | Med-Flamingo-9B | 75B | 0% | 16.7% |
数据集特点
- 精心策划和标注的神经医学数据集
- 支持VLM模型的训练和评估
- 设计目标: 探索神经病学中多模态临床推理的极限
使用声明
- 用途: 仅限研究目的
- 许可证: MIT License
- 免责声明: 不承担因使用NeuralMedBench造成的任何损害责任
搜集汇总
数据集介绍
构建方式
在神经医学领域,精准的临床推理评估对诊断可信度至关重要。Neural-MedBench通过漏斗式四阶段流程构建:首先从ADNI、OASIS、Radiopaedia和JAMA Neurology等权威来源汇集2000余例候选病例,筛选具备完整多模态数据的案例;随后由资深神经科医生团队进行临床合理性与诊断复杂性评估;进而系统标注包含最终诊断、鉴别诊断和解释性推理链的结构化标准答案;最后通过共识评审与基线模型验证,过滤简单病例,确保最终120例病例均具备高密度推理价值。
特点
该数据集以深度推理为核心特征,突破传统医学基准对分类准确率的单一关注。其设计融合多序列MRI扫描、结构化电子健康记录和临床叙事文本,形成200项推理密集型任务,涵盖鉴别诊断、病灶识别和原理生成三大任务族。病例按难度分为三个层级:直接诊断案例呈现明确线索,复杂疾病案例需处理罕见病症与模糊临床表现,多轮对话案例模拟会诊式迭代推理。这种分层设计能精准探测模型从事实回忆到高阶临床推理的认知边界。
使用方法
该数据集采用混合评估协议实现临床严谨性与可扩展性的平衡。研究阶段通过临床医生闭环验证,确保基于LLM的评分器与专家判断高度相关;社区应用阶段则释放经过临床校准的自动化评分器,支持研究者无需医疗专家参与即可获得可靠评估结果。评估指标融合诊断准确率(pass@k)、语义保真度(BERTScore)和推理保真度(LLM评分器),同时建立人类医师性能基线,为模型性能提供现实参照系。这种设计使该数据集既能作为高分辨率压力测试工具,又能以低成本支持学术实验室的稳健性分析。
背景与挑战
背景概述
神经医学领域正面临多模态人工智能评估的深刻变革。Neural-MedBench由广东智能科学与技术研究院联合多家医疗机构于2025年提出,旨在解决现有医学视觉语言模型在临床推理能力评估中的局限性。该数据集聚焦神经病学诊断场景,整合多序列MRI扫描、结构化电子健康记录和临床笔记,通过120个专家标注的多模态病例构建了200个推理密集型任务。其核心研究问题在于突破传统分类准确率的评估范式,建立能够真实反映模型临床推理深度的双轴评估框架,对推动可信赖医疗人工智能发展具有里程碑意义。
当前挑战
该数据集致力于解决神经病学诊断推理的深度评估挑战,传统医学基准过度依赖分类准确率而忽视临床推理的真实性。构建过程中面临三大核心挑战:多模态数据融合的复杂性要求精确对齐影像学特征与临床文本信息;专家标注的高标准需要资深神经科医生对每个病例进行诊断复杂性评估和推理链标注;评估体系的设计需平衡自动化效率与临床可信度,开发出经过临床验证的混合评分流程。这些挑战共同塑造了该数据集在医学人工智能评估领域的独特价值。
常用场景
经典使用场景
在神经医学人工智能研究领域,Neural-MedBench作为深度推理基准测试的核心工具,主要用于评估多模态视觉语言模型在复杂临床场景下的诊断推理能力。该数据集通过整合多序列MRI扫描、结构化电子健康记录和临床笔记,构建了包含鉴别诊断、病灶识别和原理生成三大任务家族的评估体系。研究者通常采用其混合评分流程,结合基于大语言模型的评分器与临床医生验证,系统性地揭示模型在高压诊断环境中的真实推理局限。
实际应用
在临床实践与医学教育中,Neural-MedBench可作为神经科医师培训的高保真模拟平台,其案例设计借鉴了客观结构化临床考试模式,能够有效评估受训者在复杂病情中的诊断思维过程。医疗机构可借助该基准对部署的辅助诊断系统进行压力测试,确保其在面对罕见病征或不典型临床表现时仍能保持可靠的推理链条。医学教育机构则可通过分析模型在分级任务中的表现,优化临床推理课程的教学重点与方法。
衍生相关工作
该数据集的发布催生了多个重要研究方向,包括基于诊断竞技场的对抗性评估框架和医学智能体基准测试系统的演进。其双轴评估理论启发了后续研究对医学人工智能评估体系的重新审视,促使社区开发更多专注于推理深度的紧凑型基准。在方法论层面,Neural-MedBench的混合评估协议为后续工作提供了可复现的临床校准自动化评估范式,其错误分类体系也为模型失败模式的归因分析建立了标准框架。
以上内容由遇见数据集搜集并总结生成


