google-research-datasets/tydiqa
收藏Hugging Face2024-08-08 更新2024-06-15 收录
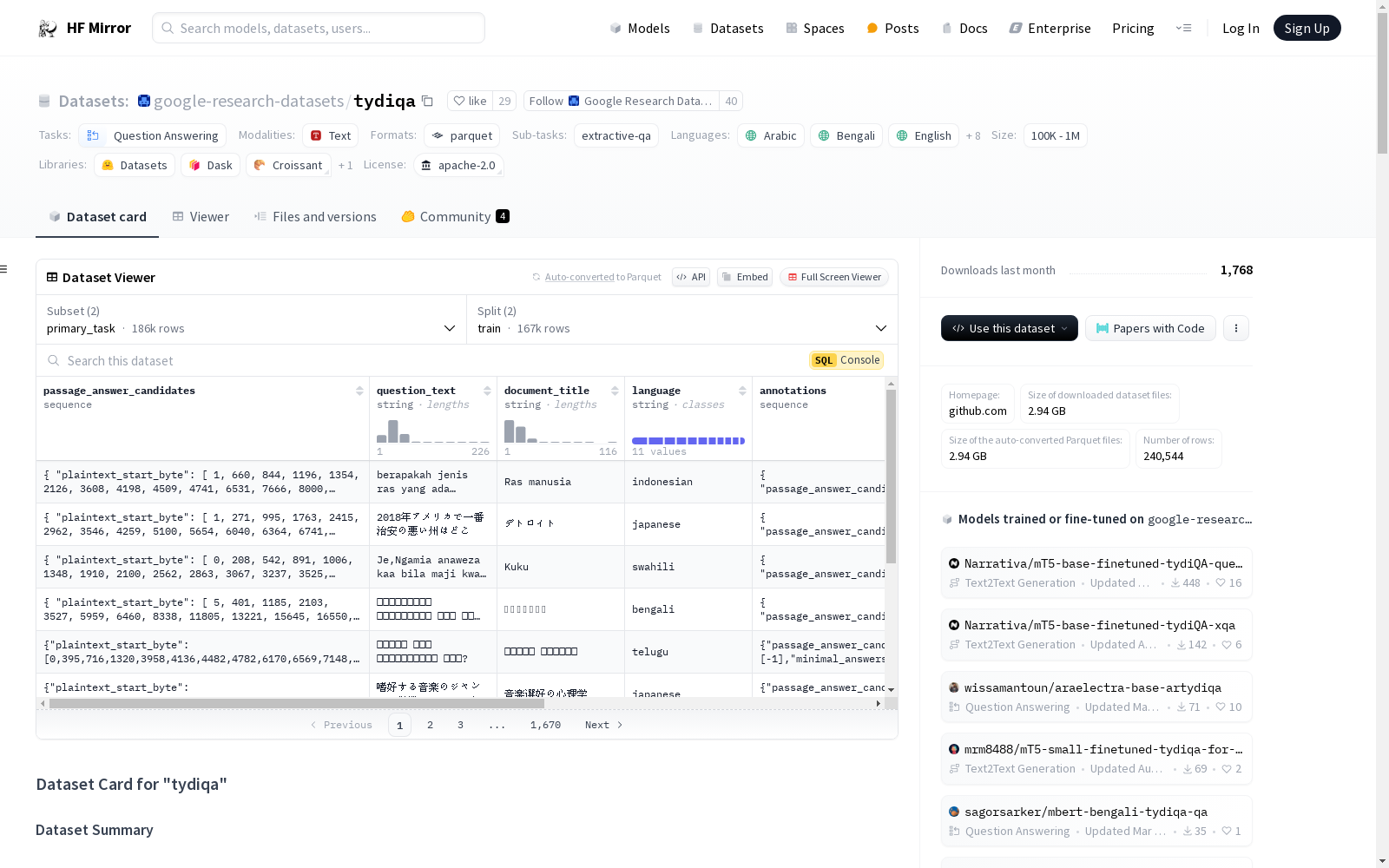
下载链接:
https://hf-mirror.com/datasets/google-research-datasets/tydiqa
下载链接
链接失效反馈资源简介:
---
annotations_creators:
- crowdsourced
language_creators:
- crowdsourced
language:
- ar
- bn
- en
- fi
- id
- ja
- ko
- ru
- sw
- te
- th
license:
- apache-2.0
multilinguality:
- multilingual
size_categories:
- unknown
source_datasets:
- extended|wikipedia
task_categories:
- question-answering
task_ids:
- extractive-qa
paperswithcode_id: tydi-qa
pretty_name: TyDi QA
dataset_info:
- config_name: primary_task
features:
- name: passage_answer_candidates
sequence:
- name: plaintext_start_byte
dtype: int32
- name: plaintext_end_byte
dtype: int32
- name: question_text
dtype: string
- name: document_title
dtype: string
- name: language
dtype: string
- name: annotations
sequence:
- name: passage_answer_candidate_index
dtype: int32
- name: minimal_answers_start_byte
dtype: int32
- name: minimal_answers_end_byte
dtype: int32
- name: yes_no_answer
dtype: string
- name: document_plaintext
dtype: string
- name: document_url
dtype: string
splits:
- name: train
num_bytes: 5550573801
num_examples: 166916
- name: validation
num_bytes: 484380347
num_examples: 18670
download_size: 2912112378
dataset_size: 6034954148
- config_name: secondary_task
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: text
dtype: string
- name: answer_start
dtype: int32
splits:
- name: train
num_bytes: 52948467
num_examples: 49881
- name: validation
num_bytes: 5006433
num_examples: 5077
download_size: 29402238
dataset_size: 57954900
configs:
- config_name: primary_task
data_files:
- split: train
path: primary_task/train-*
- split: validation
path: primary_task/validation-*
- config_name: secondary_task
data_files:
- split: train
path: secondary_task/train-*
- split: validation
path: secondary_task/validation-*
---
# Dataset Card for "tydiqa"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://github.com/google-research-datasets/tydiqa](https://github.com/google-research-datasets/tydiqa)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 3.91 GB
- **Size of the generated dataset:** 6.10 GB
- **Total amount of disk used:** 10.00 GB
### Dataset Summary
TyDi QA is a question answering dataset covering 11 typologically diverse languages with 204K question-answer pairs.
The languages of TyDi QA are diverse with regard to their typology -- the set of linguistic features that each language
expresses -- such that we expect models performing well on this set to generalize across a large number of the languages
in the world. It contains language phenomena that would not be found in English-only corpora. To provide a realistic
information-seeking task and avoid priming effects, questions are written by people who want to know the answer, but
don’t know the answer yet, (unlike SQuAD and its descendents) and the data is collected directly in each language without
the use of translation (unlike MLQA and XQuAD).
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### primary_task
- **Size of downloaded dataset files:** 1.95 GB
- **Size of the generated dataset:** 6.04 GB
- **Total amount of disk used:** 7.99 GB
An example of 'validation' looks as follows.
```
This example was too long and was cropped:
{
"annotations": {
"minimal_answers_end_byte": [-1, -1, -1],
"minimal_answers_start_byte": [-1, -1, -1],
"passage_answer_candidate_index": [-1, -1, -1],
"yes_no_answer": ["NONE", "NONE", "NONE"]
},
"document_plaintext": "\"\\nรองศาสตราจารย์[1] หม่อมราชวงศ์สุขุมพันธุ์ บริพัตร (22 กันยายน 2495 -) ผู้ว่าราชการกรุงเทพมหานครคนที่ 15 อดีตรองหัวหน้าพรรคปร...",
"document_title": "หม่อมราชวงศ์สุขุมพันธุ์ บริพัตร",
"document_url": "\"https://th.wikipedia.org/wiki/%E0%B8%AB%E0%B8%A1%E0%B9%88%E0%B8%AD%E0%B8%A1%E0%B8%A3%E0%B8%B2%E0%B8%8A%E0%B8%A7%E0%B8%87%E0%B8%...",
"language": "thai",
"passage_answer_candidates": "{\"plaintext_end_byte\": [494, 1779, 2931, 3904, 4506, 5588, 6383, 7122, 8224, 9375, 10473, 12563, 15134, 17765, 19863, 21902, 229...",
"question_text": "\"หม่อมราชวงศ์สุขุมพันธุ์ บริพัตร เรียนจบจากที่ไหน ?\"..."
}
```
#### secondary_task
- **Size of downloaded dataset files:** 1.95 GB
- **Size of the generated dataset:** 58.03 MB
- **Total amount of disk used:** 2.01 GB
An example of 'validation' looks as follows.
```
This example was too long and was cropped:
{
"answers": {
"answer_start": [394],
"text": ["بطولتين"]
},
"context": "\"أقيمت البطولة 21 مرة، شارك في النهائيات 78 دولة، وعدد الفرق التي فازت بالبطولة حتى الآن 8 فرق، ويعد المنتخب البرازيلي الأكثر تت...",
"id": "arabic-2387335860751143628-1",
"question": "\"كم عدد مرات فوز الأوروغواي ببطولة كاس العالم لكرو القدم؟\"...",
"title": "قائمة نهائيات كأس العالم"
}
```
### Data Fields
The data fields are the same among all splits.
#### primary_task
- `passage_answer_candidates`: a dictionary feature containing:
- `plaintext_start_byte`: a `int32` feature.
- `plaintext_end_byte`: a `int32` feature.
- `question_text`: a `string` feature.
- `document_title`: a `string` feature.
- `language`: a `string` feature.
- `annotations`: a dictionary feature containing:
- `passage_answer_candidate_index`: a `int32` feature.
- `minimal_answers_start_byte`: a `int32` feature.
- `minimal_answers_end_byte`: a `int32` feature.
- `yes_no_answer`: a `string` feature.
- `document_plaintext`: a `string` feature.
- `document_url`: a `string` feature.
#### secondary_task
- `id`: a `string` feature.
- `title`: a `string` feature.
- `context`: a `string` feature.
- `question`: a `string` feature.
- `answers`: a dictionary feature containing:
- `text`: a `string` feature.
- `answer_start`: a `int32` feature.
### Data Splits
| name | train | validation |
| -------------- | -----: | ---------: |
| primary_task | 166916 | 18670 |
| secondary_task | 49881 | 5077 |
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@article{tydiqa,
title = {TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages},
author = {Jonathan H. Clark and Eunsol Choi and Michael Collins and Dan Garrette and Tom Kwiatkowski and Vitaly Nikolaev and Jennimaria Palomaki}
year = {2020},
journal = {Transactions of the Association for Computational Linguistics}
}
```
### Contributions
Thanks to [@thomwolf](https://github.com/thomwolf), [@albertvillanova](https://github.com/albertvillanova), [@lewtun](https://github.com/lewtun), [@patrickvonplaten](https://github.com/patrickvonplaten) for adding this dataset.
annotations_creators:
- 众包(crowdsourced)
language_creators:
- 众包(crowdsourced)
language:
- 阿拉伯语(ar)
- 孟加拉语(bn)
- 英语(en)
- 芬兰语(fi)
- 印尼语(id)
- 日语(ja)
- 韩语(ko)
- 俄语(ru)
- 斯瓦希里语(sw)
- 泰卢固语(te)
- 泰语(th)
license:
- Apache许可证2.0(Apache-2.0)
multilinguality:
- 多语言(multilingual)
size_categories:
- 未知(unknown)
source_datasets:
- 扩展自维基百科(extended|wikipedia)
task_categories:
- 问答(question-answering)
task_ids:
- 抽取式问答(extractive-qa)
paperswithcode_id: tydi-qa
pretty_name: TyDi QA
dataset_info:
- config_name: primary_task
features:
- name: passage_answer_candidates
sequence:
- name: plaintext_start_byte
dtype: 32位整数(int32)
- name: plaintext_end_byte
dtype: 32位整数(int32)
- name: question_text
dtype: 字符串(string)
- name: document_title
dtype: 字符串(string)
- name: language
dtype: 字符串(string)
- name: annotations
sequence:
- name: passage_answer_candidate_index
dtype: 32位整数(int32)
- name: minimal_answers_start_byte
dtype: 32位整数(int32)
- name: minimal_answers_end_byte
dtype: 32位整数(int32)
- name: yes_no_answer
dtype: 字符串(string)
- name: document_plaintext
dtype: 字符串(string)
- name: document_url
dtype: 字符串(string)
splits:
- name: train
num_bytes: 5550573801
num_examples: 166916
- name: validation
num_bytes: 484380347
num_examples: 18670
download_size: 2912112378
dataset_size: 6034954148
- config_name: secondary_task
features:
- name: id
dtype: 字符串(string)
- name: title
dtype: 字符串(string)
- name: context
dtype: 字符串(string)
- name: question
dtype: 字符串(string)
- name: answers
sequence:
- name: text
dtype: 字符串(string)
- name: answer_start
dtype: 32位整数(int32)
splits:
- name: train
num_bytes: 52948467
num_examples: 49881
- name: validation
num_bytes: 5006433
num_examples: 5077
download_size: 29402238
dataset_size: 57954900
configs:
- config_name: primary_task
data_files:
- split: train
path: primary_task/train-*
- split: validation
path: primary_task/validation-*
- config_name: secondary_task
data_files:
- split: train
path: secondary_task/train-*
- split: validation
path: secondary_task/validation-*
# "TyDi QA" 数据集卡片
## 目录
- [数据集描述](#dataset-description)
- [数据集概述](#dataset-summary)
- [支持任务与基准榜单](#supported-tasks-and-leaderboards)
- [语言覆盖](#languages)
- [数据集结构](#dataset-structure)
- [数据实例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集构建](#dataset-creation)
- [构建初衷](#curation-rationale)
- [源数据](#source-data)
- [标注流程](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据集使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏差讨论](#discussion-of-biases)
- [其他已知局限](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集维护者](#dataset-curators)
- [许可信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献致谢](#contributions)
## 数据集描述
- **主页**:[https://github.com/google-research-datasets/tydiqa](https://github.com/google-research-datasets/tydiqa)
- **仓库**:[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **论文**:[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **联系人**:[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **下载数据集文件大小**:3.91 GB
- **生成后数据集大小**:6.10 GB
- **总磁盘占用**:10.00 GB
### 数据集概述
TyDi QA是一个覆盖11种类型学特征各异语言的问答数据集,共包含20.4万个问答对。该数据集所覆盖的语言在类型学——即每种语言所体现的语言特征集合——上具有高度多样性,因此我们期望在该数据集上表现优异的模型能够泛化至全球绝大多数语言。数据集包含仅英语语料库中无法见到的语言现象。为构建贴合实际的信息检索任务并避免启动效应(priming effects),问题由那些想要知晓答案但本身并不知情的人群撰写(与SQuAD及其衍生数据集不同),且数据直接以各语言原生方式收集,未经过翻译环节(与MLQA和XQuAD不同)。
### 支持任务与基准榜单
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 语言覆盖
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据集结构
### 数据实例
#### primary_task(主任务配置)
- **下载数据集文件大小**:1.95 GB
- **生成后数据集大小**:6.04 GB
- **总磁盘占用**:7.99 GB
验证集(validation)的一个示例如下(示例内容过长已截断):
{
"annotations": {
"minimal_answers_end_byte": [-1, -1, -1],
"minimal_answers_start_byte": [-1, -1, -1],
"passage_answer_candidate_index": [-1, -1, -1],
"yes_no_answer": ["NONE", "NONE", "NONE"]
},
"document_plaintext": ""\nรองศาสตราจารย์[1] หม่อมราชวงศ์สุขุมพันธุ์ บริพัตร (22 กันยายน 2495 -) ผู้ว่าราชการกรุงเทพมหานครคนที่ 15 อดีตรองหัวหน้าพรรคปร...",
"document_title": "หม่อมราชวงศ์สุขุมพันธุ์ บริพัตร",
"document_url": ""https://th.wikipedia.org/wiki/%E0%B8%AB%E0%B8%A1%E0%B9%88%E0%B8%AD%E0%B8%A1%E0%B8%A3%E0%B8%B2%E0%B8%8A%E0%B8%A7%E0%B8%87%E0%B8%...",
"language": "thai",
"passage_answer_candidates": "{"plaintext_end_byte": [494, 1779, 2931, 3904, 4506, 5588, 6383, 7122, 8224, 9375, 10473, 12563, 15134, 17765, 19863, 21902, 229...",
"question_text": ""หม่อมราชวงศ์สุขุมพันธุ์ บริพัตร เรียนจบจากที่ไหน ?"..."
}
#### secondary_task(副任务配置)
- **下载数据集文件大小**:1.95 GB
- **生成后数据集大小**:58.03 MB
- **总磁盘占用**:2.01 GB
验证集(validation)的一个示例如下(示例内容过长已截断):
{
"answers": {
"answer_start": [394],
"text": ["بطولتين"]
},
"context": ""أقيمت البطولة 21 مرة، شارك في النهائيات 78 دولة، وعدد الفرق التي فازت بالبطولة حتى الآن 8 فرق، ويعد المنتخب البرازيلي الأكثر تت...",
"id": "arabic-2387335860751143628-1",
"question": ""كم عدد مرات فوز الأوروغواي ببطولة كاس العالم لكرو القدم؟"...",
"title": "قائمة نهائيات كأس العالم"
}
### 数据字段
所有数据划分的数据字段保持一致。
#### primary_task(主任务配置)
- `passage_answer_candidates`:字典类型特征,包含:
- `plaintext_start_byte`:32位整数(int32)类型特征,表示候选答案段落的明文起始字节位置
- `plaintext_end_byte`:32位整数(int32)类型特征,表示候选答案段落的明文结束字节位置
- `question_text`:字符串(string)类型特征,即问题文本
- `document_title`:字符串(string)类型特征,即来源文档标题
- `language`:字符串(string)类型特征,即数据所属语言
- `annotations`:字典类型特征,包含:
- `passage_answer_candidate_index`:32位整数(int32)类型特征,即候选答案段落的索引
- `minimal_answers_start_byte`:32位整数(int32)类型特征,表示最小答案的起始字节位置
- `minimal_answers_end_byte`:32位整数(int32)类型特征,表示最小答案的结束字节位置
- `yes_no_answer`:字符串(string)类型特征,即是否类答案字段
- `document_plaintext`:字符串(string)类型特征,即来源文档的明文内容
- `document_url`:字符串(string)类型特征,即来源文档的URL地址
#### secondary_task(副任务配置)
- `id`:字符串(string)类型特征,即数据实例唯一标识符
- `title`:字符串(string)类型特征,即上下文所属标题
- `context`:字符串(string)类型特征,即问答上下文文本
- `question`:字符串(string)类型特征,即问题文本
- `answers`:字典类型特征,包含:
- `text`:字符串(string)类型特征,即答案文本
- `answer_start`:32位整数(int32)类型特征,表示答案在上下文中的起始字节位置
### 数据划分
| 配置名称 | 训练集样本数 | 验证集样本数 |
| ------------------ | -----------: | -----------: |
| primary_task | 166916 | 18670 |
| secondary_task | 49881 | 5077 |
## 数据集构建
### 构建初衷
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 源数据
#### 初始数据收集与标准化
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 源语言数据生产者
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 标注流程
#### 标注过程
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 标注人员
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 个人与敏感信息
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据集使用注意事项
### 数据集的社会影响
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 偏差讨论
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 其他已知局限
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 附加信息
### 数据集维护者
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 许可信息
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 引用信息
@article{tydiqa,
title = {TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages},
author = {Jonathan H. Clark and Eunsol Choi and Michael Collins and Dan Garrette and Tom Kwiatkowski and Vitaly Nikolaev and Jennimaria Palomaki}
year = {2020},
journal = {Transactions of the Association for Computational Linguistics}
}
### 贡献致谢
感谢 [@thomwolf](https://github.com/thomwolf)、[@albertvillanova](https://github.com/albertvillanova)、[@lewtun](https://github.com/lewtun)、[@patrickvonplaten](https://github.com/patrickvonplaten) 为本数据集的收录提供支持。
提供机构:
google-research-datasets
原始信息汇总
数据集概述
基本信息
- 数据集名称: TyDi QA
- 标注创建者: 众包
- 语言创建者: 众包
- 语言: 阿拉伯语, 孟加拉语, 英语, 芬兰语, 印度尼西亚语, 日语, 韩语, 俄语, 斯瓦希里语, 泰卢固语, 泰语
- 许可证: Apache 2.0
- 多语言性: 多语言
- 源数据集: 扩展自 Wikipedia
- 任务类别: 问答
- 任务ID: 抽取式问答
- PapersWithCode ID: tydi-qa
数据集结构
配置信息
-
primary_task
- 特征:
passage_answer_candidates: 包含plaintext_start_byte和plaintext_end_bytequestion_text: 字符串document_title: 字符串language: 字符串annotations: 包含passage_answer_candidate_index,minimal_answers_start_byte,minimal_answers_end_byte,yes_no_answerdocument_plaintext: 字符串document_url: 字符串
- 分割:
train: 166916 个样本, 5550574617 字节validation: 18670 个样本, 484380443 字节
- 下载大小: 1953887429 字节
- 数据集大小: 6034955060 字节
- 特征:
-
secondary_task
- 特征:
id: 字符串title: 字符串context: 字符串question: 字符串answers: 包含text和answer_start
- 分割:
train: 49881 个样本, 52948607 字节validation: 5077 个样本, 5006461 字节
- 下载大小: 1953887429 字节
- 数据集大小: 57955068 字节
- 特征:
引用信息
@article{tydiqa, title = {TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages}, author = {Jonathan H. Clark and Eunsol Choi and Michael Collins and Dan Garrette and Tom Kwiatkowski and Vitaly Nikolaev and Jennimaria Palomaki} year = {2020}, journal = {Transactions of the Association for Computational Linguistics} }
搜集汇总
数据集介绍
构建方式
TyDi QA数据集通过众包方式构建,涵盖了11种语言,包括阿拉伯语、孟加拉语、英语、芬兰语、印度尼西亚语、日语、韩语、俄语、斯瓦希里语、泰卢固语和泰语。数据集的构建旨在提供一个多语言的问答基准,避免翻译带来的偏差,确保问题和答案的真实性。数据来源于扩展的维基百科,通过直接在每种语言中收集数据,而非翻译,以捕捉不同语言的独特语言现象。
特点
TyDi QA数据集的主要特点在于其多语言性和语言多样性。它包含了204,000个问题-答案对,覆盖了11种语言,这些语言在语言学特征上具有显著的多样性。数据集的设计旨在测试模型在不同语言间的泛化能力,特别是那些在英语语料库中不常见的语言现象。此外,数据集避免了翻译带来的偏差,确保了问题的真实性和答案的准确性。
使用方法
TyDi QA数据集适用于多种自然语言处理任务,特别是问答系统。用户可以通过HuggingFace的datasets库加载该数据集,并根据需要选择不同的配置(如primary_task和secondary_task)。数据集提供了丰富的字段,包括问题文本、文档标题、语言标识、答案候选者及其位置信息等。用户可以根据这些字段进行模型训练和验证,以提升多语言问答系统的性能。
背景与挑战
背景概述
TyDi QA数据集由Google Research团队创建,旨在推动多语言问答系统的研究。该数据集涵盖了11种类型学上多样化的语言,包括阿拉伯语、孟加拉语、英语、芬兰语、印度尼西亚语、日语、韩语、俄语、斯瓦希里语、泰卢固语和泰语,共包含204,000个问答对。其核心研究问题是如何在多语言环境下实现高效的信息检索和问答系统,特别是如何处理非英语语言中的复杂语言现象。TyDi QA的创建旨在提供一个真实的信息检索任务,避免翻译带来的偏差,并促进模型在多语言环境下的泛化能力。该数据集的发布对多语言自然语言处理领域产生了深远影响,为研究人员提供了一个评估和改进多语言问答系统的重要基准。
当前挑战
TyDi QA数据集面临的主要挑战包括:1) 多语言环境的复杂性,不同语言的语法、词汇和表达方式差异巨大,导致模型在跨语言迁移时面临困难;2) 数据收集和标注的难度,由于涉及多种语言,数据的质量和一致性难以保证;3) 语言现象的多样性,某些语言特有的现象在其他语言中不存在,增加了模型理解和处理的复杂性。此外,构建过程中还需克服语言资源不均衡的问题,确保每种语言的数据量和质量都能满足研究需求。这些挑战使得TyDi QA成为多语言问答系统研究中的重要里程碑,同时也为未来的研究提供了丰富的探索空间。
常用场景
经典使用场景
TyDi QA数据集在多语言问答任务中展现了其经典应用场景。该数据集涵盖了11种语言,旨在评估模型在不同语言环境下的问答能力。通过提供多语言的问答对,TyDi QA允许研究者开发和测试能够跨语言泛化的问答系统,尤其是在非英语语言中的表现。
解决学术问题
TyDi QA数据集解决了多语言问答系统中的关键学术问题,特别是在非英语语言中的问答能力。通过提供多语言的问答对,该数据集帮助研究者评估和改进模型在不同语言中的泛化能力,从而推动了多语言自然语言处理领域的发展。
衍生相关工作
TyDi QA数据集的发布激发了大量相关研究工作,特别是在多语言问答和跨语言模型泛化方面。许多研究者基于该数据集开发了新的模型和方法,以提升多语言问答的准确性和效率,推动了多语言自然语言处理技术的进步。
以上内容由遇见数据集搜集并总结生成


