Word-level controlled scene text dataset
收藏arXiv2025-06-26 更新2025-06-28 收录
下载链接:
https://wendashi.github.io/WordCon-Page/
下载链接
链接失效反馈官方服务:
资源简介:
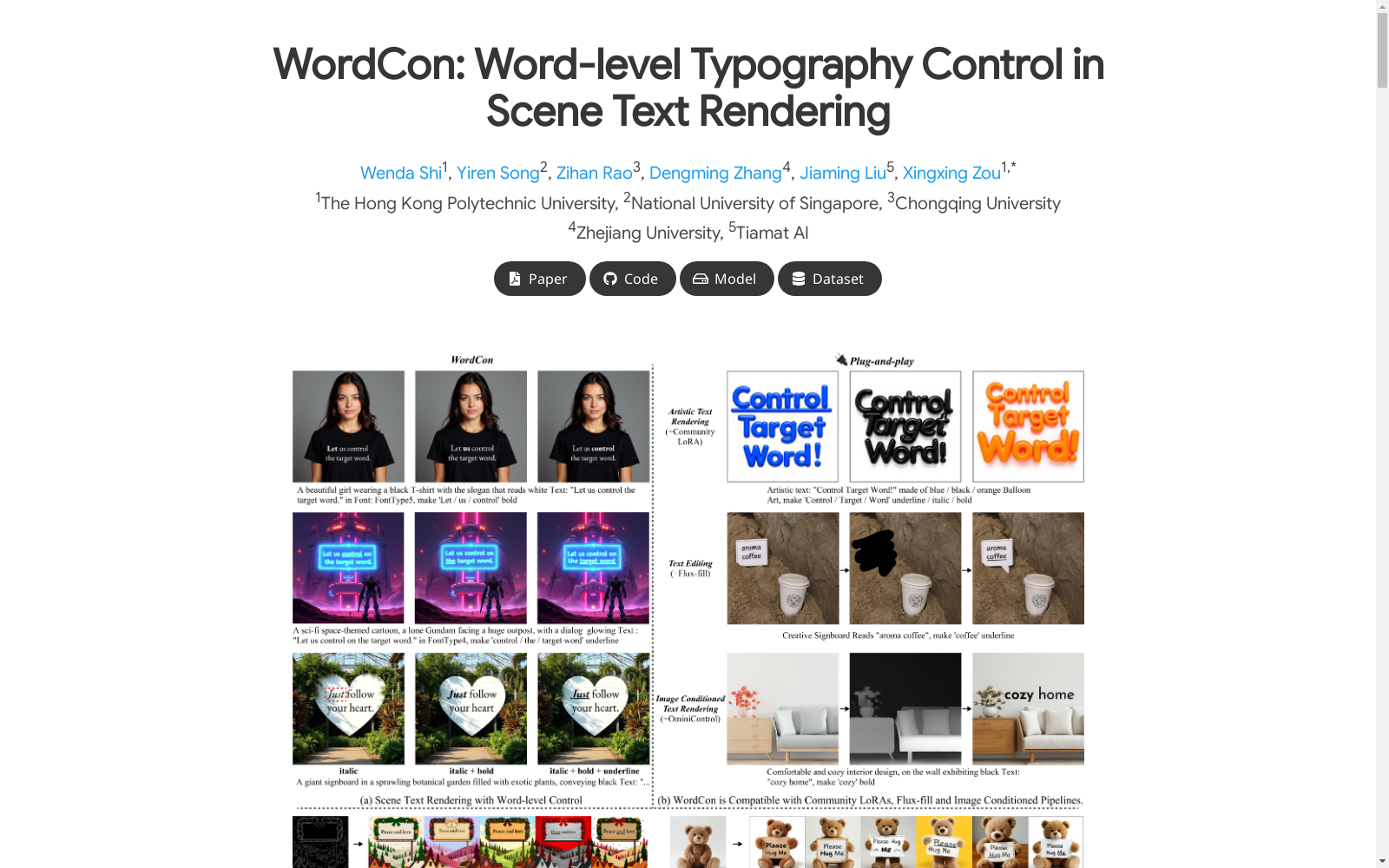
WordCon数据集是一个用于场景文本渲染的词汇级控制数据集,由香港理工大学、新加坡国立大学、重庆大学、浙江大学和Tiamat AI的研究人员构建。该数据集旨在解决场景文本渲染中单词级别的字体样式控制问题。数据集包含场景文本渲染所需的词汇级控制数据,以及每个单词的分割掩码。数据集的创建过程涉及文本-图像对齐框架(TIA),它利用了 grounding 模型的跨模态对应关系来增强文本到图像模型的训练。WordCon数据集的应用领域包括艺术文本渲染、文本编辑和条件图像文本渲染,旨在解决文本渲染中单词级别的样式控制问题。
The WordCon dataset is a vocabulary-level controlled dataset for scene text rendering, constructed by researchers from The Hong Kong Polytechnic University, National University of Singapore, Chongqing University, Zhejiang University, and Tiamat AI. This dataset aims to address the problem of word-level font style control in scene text rendering. The dataset includes vocabulary-level control data required for scene text rendering, as well as segmentation masks for each individual word. The creation of this dataset involves the Text-Image Alignment (TIA) framework, which leverages the cross-modal correspondence of grounding models to enhance the training of text-to-image models. The application scenarios of the WordCon dataset cover artistic text rendering, text editing, and conditional image text rendering, with the goal of solving the problem of word-level style control in text rendering.
提供机构:
The Hong Kong Polytechnic University, National University of Singapore, Chongqing Univesity, Zhejiang University, Tiamat AI
创建时间:
2025-06-26
搜集汇总
数据集介绍
构建方式
Word-level controlled scene text dataset的构建采用了多阶段协同的合成策略,通过HTML渲染引擎生成透明背景的文本图层,同时利用Flux.1模型生成多样化场景背景。文本内容从包含3-70字符的语料库中采样,覆盖五种标准字体类型,经质量筛选后通过图层叠加技术将文本精准嵌入场景。该流程特别设计了词级标注机制,对每个单词的字体样式(如加粗/斜体/下划线)进行细粒度标注,并配合分割掩模实现空间定位,为模型提供像素级的监督信号。
特点
该数据集的核心价值在于其细粒度的词级排版控制能力,包含28,000个512×512分辨率的样本,每个样本均具备精确的词级样式标注和分割掩模。区别于传统文本渲染数据集,其创新性体现在三方面:多尺度文本嵌入使模型适应不同场景需求;动态背景合成增强了视觉泛化能力;复合样式标注支持对同一文本中不同单词施加差异化排版属性。特别设计的字体类型分布(衬线/无衬线/等宽等)与场景背景的强耦合性,为模型学习文本-场景交互提供了丰富素材。
使用方法
使用该数据集需结合TIA(Text-Image Alignment)框架进行模型训练,通过 grounding model 提供的词级分割掩模建立文本-图像对齐。具体流程包含双路监督:潜在空间的掩模损失(L_mask)强化文本区域学习,联合注意力损失(L_attn)实现单词-图像区域的精确映射。训练时建议采用混合参数高效微调策略(WordCon),选择性重参数化DiT模型中的文本注意力参数。推理阶段可无缝接入图像条件管道(如OminiControl)或艺术风格LoRA,通过自然语言指令实现'对指定单词应用特定样式'的细粒度控制。
背景与挑战
背景概述
Word-level controlled scene text dataset(WordCon)是由香港理工大学、新加坡国立大学、重庆大学、浙江大学以及Tiamat AI的研究团队于2025年提出的创新性数据集,旨在解决场景文本渲染中的细粒度排版控制问题。该数据集通过融合HTML渲染技术与扩散模型生成的场景背景,构建了包含28,000个样本的多样化文本图像集合,覆盖5种字体类型及3-70字符长度的文本。其核心研究问题聚焦于突破传统文本到图像(T2I)模型在单词级排版属性(如加粗、斜体、下划线)精准控制的技术瓶颈,为广告设计、品牌视觉生成等应用场景提供了关键技术支持。该数据集的创新性体现于其首次实现了文本内容、字体样式与场景背景的三元解耦标注,推动了跨模态对齐理论在生成式AI领域的发展。
当前挑战
WordCon数据集面临的核心挑战主要体现在两个方面:其一,在领域问题层面,现有T2I模型(如Stable Diffusion、Flux等)存在单词级注意力错位现象,导致无法精准定位特定单词的视觉区域以实现独立排版控制,实验表明基线模型的总控制准确率不足50%;其二,在构建过程中,需克服文本-图像多尺度对齐的工程难题,包括透明图层合成时的光照一致性保持、复杂背景下文本区域的分割精度提升,以及跨字体风格的语义连贯性保障。此外,数据标注需平衡人工校验效率与细粒度标注质量,针对重复单词的歧义控制问题仍需进一步优化。
常用场景
经典使用场景
WordCon数据集在场景文本渲染领域展现了卓越的适用性,尤其在需要精确控制单词级排版属性的场景中表现突出。该数据集通过整合HTML渲染器生成的文本与多样化场景背景,支持对特定单词应用加粗、斜体或下划线等排版属性,同时保持与周围视觉元素的自然融合。其典型应用包括广告设计中的标语定制、电影场景中的动态文字生成,以及教育材料中关键术语的视觉强化,为设计师提供了前所未有的排版控制精度。
衍生相关工作
该数据集催生了多项创新性研究,包括基于文本-图像对齐框架的DIVAVLM增强方法、采用联合注意力损失的EasyControl扩散控制器等。在产业界,其技术路线被Recraftv3等商业设计平台采纳,启发了Gemini2.0的图像生成模块改进。相关衍生工作主要集中在三个方向:跨模态对齐机制的优化、参数高效微调方法的创新,以及基于注意力解耦的细粒度控制研究,持续推动着视觉文本生成领域的技术演进。
数据集最近研究
最新研究方向
近年来,Word-level controlled scene text dataset在计算机视觉和文本生成领域引起了广泛关注。该数据集通过细粒度的文本图像对齐框架(TIA)和高效的参数微调方法(WordCon),显著提升了场景文本渲染中单词级排版控制的精度。前沿研究主要集中在如何利用跨模态对齐技术优化文本到图像生成模型,特别是在广告设计、品牌营销等实际应用中,对特定单词的加粗、斜体或下划线等排版属性的精确控制。此外,该数据集与社区LoRAs、Flux-fill和图像条件管道的兼容性,进一步拓展了其在艺术文本渲染、文本编辑等多样化场景中的应用潜力。这些进展不仅解决了传统模型在单词级控制上的局限性,还为生成高质量视觉文本提供了新的技术路径。
相关研究论文
- 1WordCon: Word-level Typography Control in Scene Text RenderingThe Hong Kong Polytechnic University, National University of Singapore, Chongqing Univesity, Zhejiang University, Tiamat AI · 2025年
以上内容由遇见数据集搜集并总结生成


