FoundationStereo Dataset (FSD)
收藏资源简介:
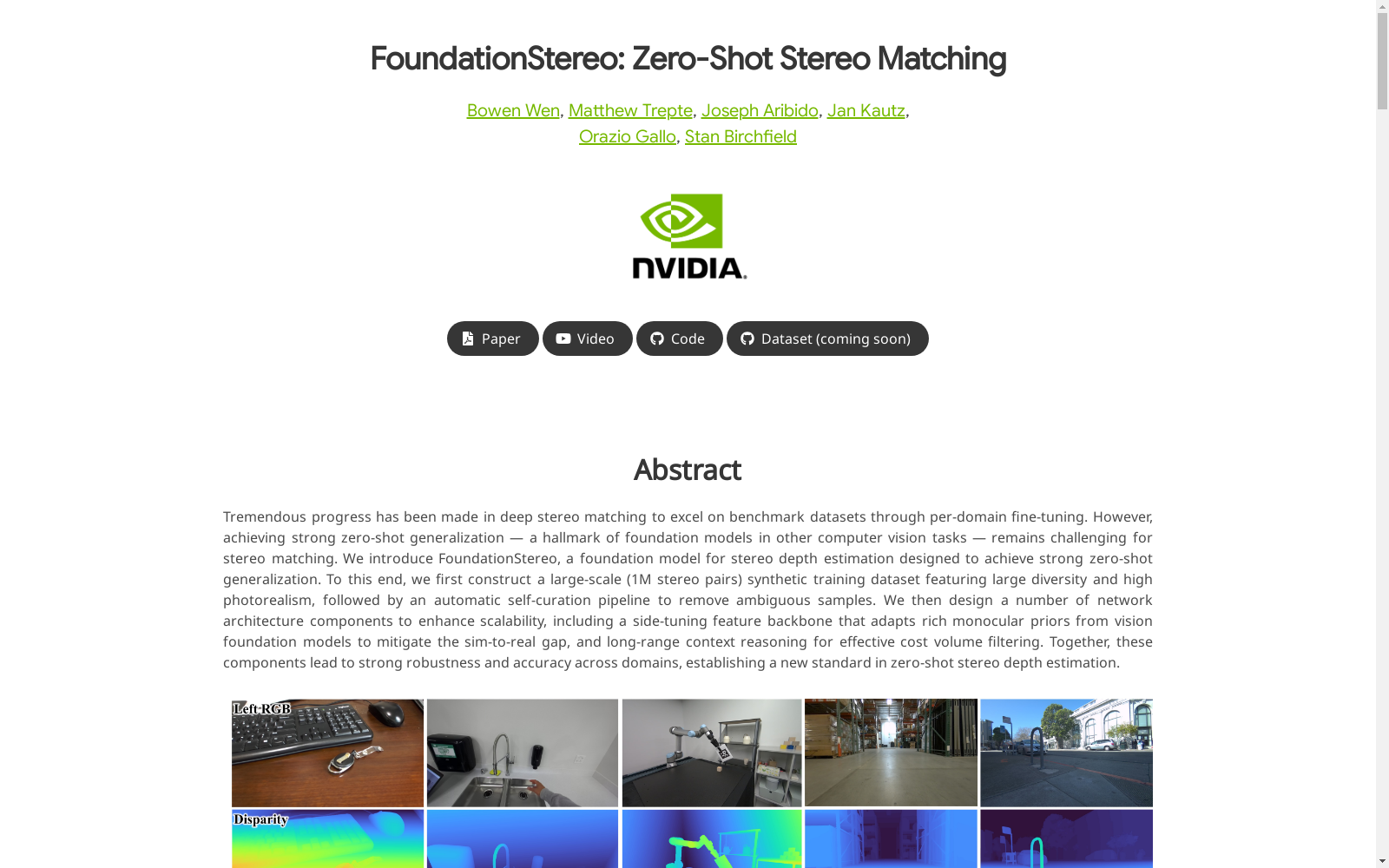
FoundationStereo数据集(FSD)是由英伟达创建的一个大规模合成数据集,包含100万对立体图像,具有高度的多样性和真实感。该数据集通过自动自筛选管道去除模糊样本,确保数据质量。数据集涵盖了多种场景,包括室内、室外、驾驶等,并具有高保真的渲染效果和空间布局。该数据集旨在解决立体深度估计中的零样本泛化问题,适用于计算机视觉领域中的立体匹配任务。
The FoundationStereo Dataset (FSD) is a large-scale synthetic dataset created by NVIDIA, which contains 1 million pairs of stereo images with high diversity and realism. It adopts an automated self-filtering pipeline to remove blurry samples and ensure data quality. The dataset covers various scenarios including indoor, outdoor, driving scenarios and more, and features high-fidelity rendering effects and spatial layouts. This dataset aims to address the zero-shot generalization problem in stereo depth estimation, and is applicable to stereo matching tasks in the field of computer vision.
- 1FoundationStereo: Zero-Shot Stereo Matching英伟达 · 2025年


