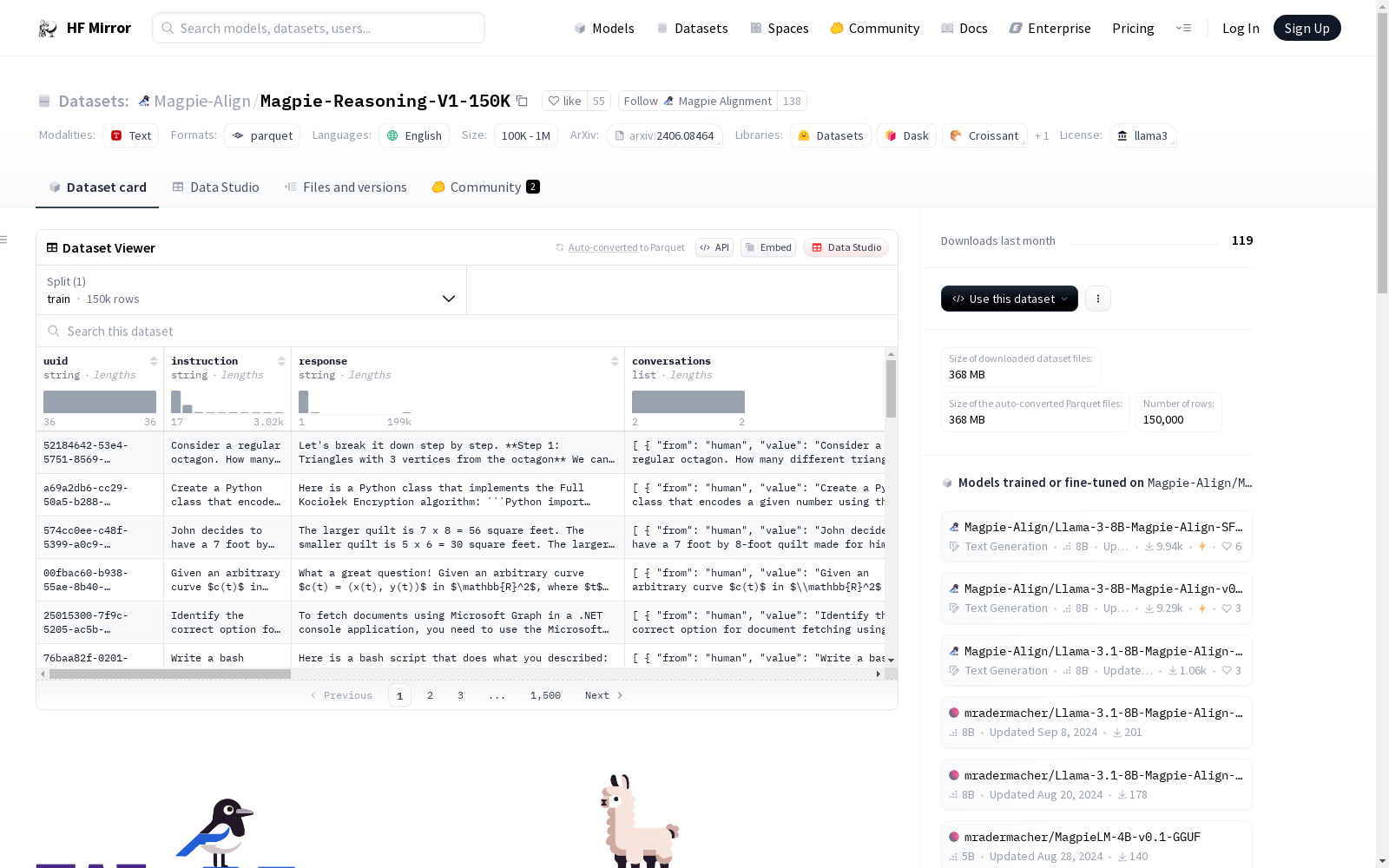
Magpie-Align/Magpie-Reasoning-150K
收藏Hugging Face2024-07-22 更新2024-07-22 收录
下载链接:
https://hf-mirror.com/datasets/Magpie-Align/Magpie-Reasoning-150K
下载链接
链接失效反馈官方服务:
资源简介:
该数据集由Qwen2-72B-Instruct和Llama 3 70B Instruct模型通过Magpie方法生成,旨在通过高质量的指令-响应对增强模型的推理能力。数据集包含150,000个训练样本,主要涉及推理、数学、编码和调试等任务类别,且所有数据均为英文。数据集的生成和选择过程中,考虑了输入质量、难度、任务类别、指令奖励等多个因素,并去除了重复和不完整的指令。
This dataset is generated by Qwen2-72B-Instruct and Llama 3 70B Instruct using the Magpie method, aiming to enhance the reasoning capabilities of models through high-quality instruction-response pairs. The dataset contains 150,000 training samples, primarily involving task categories such as reasoning, math, coding, and debugging, with all data in English. The generation and selection process of the dataset considered multiple factors including input quality, difficulty, task category, instruction reward, and removed repetitive and incomplete instructions.
提供机构:
Magpie-Align
原始信息汇总
数据集概述
数据集信息
-
特征字段:
uuid: 字符串instruction: 字符串response: 字符串conversations: 列表,包含from和value,均为字符串gen_input_configs: 结构体,包含temperature(浮点数)、top_p(浮点数)、input_generator(字符串)、seed(空值)、extract_input(字符串)gen_response_configs: 结构体,包含prompt(字符串)、temperature(整数)、top_p(浮点数)、repetition_penalty(浮点数)、max_tokens(整数)、stop_tokens(字符串序列)、output_generator(字符串)intent: 字符串knowledge: 字符串difficulty: 字符串difficulty_generator: 字符串input_quality: 字符串quality_explanation: 字符串quality_generator: 字符串task_category: 字符串other_task_category: 字符串序列task_category_generator: 字符串language: 字符串
-
数据分割:
train: 包含 150,000 个样本,大小为 833,223,418 字节
-
下载大小: 368,443,556 字节
-
数据集大小: 833,223,418 字节
-
配置:
default: 数据文件路径为data/train-*
-
许可证: llama3
-
语言: 英语
-
数据集规模: 100K < n < 1M
数据集生成
- 生成模型: 使用 Qwen2-72B-Instruct 生成指令,使用 Llama 3 70B Instruct 生成响应。
- 生成方法: 使用 Magpie 方法。
数据集过滤
- 输入质量: ≥ good
- 输入难度: ≥ easy
- 任务类别: Reasoning, Math, Coding & Debugging
- 指令奖励: ≥ -10
- 语言: 英语
- 其他过滤条件: 去除重复和未完成的指令(例如以
:结尾的指令),选择 150K 个响应最长的数据。
许可证
搜集汇总
数据集介绍
构建方式
Magpie-Align/Magpie-Reasoning-150K数据集的构建,是通过利用Qwen2-72B-Instruct和Llama 3 70B Instruct模型生成指令与响应对的方式进行的。具体而言,指令由Qwen2-72B-Instruct生成,而响应则由Llama 3 70B Instruct生成。该过程依据模型的自动回归特性,从预训练的语言模型中直接合成大规模的指令数据,进而筛选出300K高质量的数据实例,用于后续的模型训练与评估。
特点
该数据集的特点在于,它通过一种自合成的方法,从预训练的、对齐的语言模型中提取高质量指令数据。数据集覆盖了推理、数学、编码与调试等多个任务类别,且数据质量筛选标准严格,确保了指令难度不低于简单级别,输入质量良好,语言为英语。此外,数据集的构建还注重了响应的长度,选择了最长响应的数据实例,以增强模型在处理复杂任务时的表现。
使用方法
使用Magpie-Align/Magpie-Reasoning-150K数据集时,用户可以将其应用于大规模语言模型的指令对齐训练。该数据集提供了详细的配置信息,包括生成输入和响应的各种参数设置。用户可以根据具体任务需求,调整这些参数,以优化模型的性能。此外,数据集遵循特定的许可协议,用户在使用时需遵守相应的规定。
背景与挑战
背景概述
Magpie-Align/Magpie-Reasoning-150K数据集,是在人工智能领域对齐大型语言模型(LLM)的研究背景下产生的。该数据集由Qwen2-72B-Instruct和Llama 3 70B Instruct模型生成,旨在通过利用高质量指令-响应对来增强模型的推理能力。该数据集的创建,源于对现有开源数据创建方法在规模化和多样性方面的局限性的认识。研究团队通过自我合成方法,从对齐的LLM中提取数据,生成了大规模的指令数据集。这一创新方法不仅促进了AI技术的民主化,也为相关领域的研究提供了重要的数据资源。
当前挑战
该数据集在构建过程中面临的挑战主要包括:如何从对齐的LLM中高效地合成高质量指令数据;如何在保持数据质量的同时,确保数据的多样性和规模;以及如何在现有的开源数据创建方法中克服高人力成本和预定义提示范围限制等问题。此外,该数据集在解决领域问题,如提高模型在推理任务中的性能方面,也面临着如何与现有数据集竞争,以及如何通过监督微调(SFT)和反馈学习等手段进一步提升模型性能的挑战。
常用场景
经典使用场景
在自然语言处理领域,Magpie-Align/Magpie-Reasoning-150K数据集的显著应用场景在于为大型语言模型(LLM)的指令对齐提供高质量的数据支撑。该数据集通过提取自对齐LLM的指令数据,生成大规模的指令-响应对,进而促进模型在理解和执行复杂任务方面的性能提升。
衍生相关工作
基于Magpie-Align/Magpie-Reasoning-150K,研究者们进一步衍生出多个具有不同cot风格的推理数据集,这些数据集为模型提供了更加丰富和多样化的训练素材,推动了相关领域的研究进展,如AlpacaEval、ArenaHard和WildBench等对齐基准测试中的性能提升。
数据集最近研究
最新研究方向
Magpie-Align/Magpie-Reasoning-150K数据集是近期自然语言处理领域的重要成果,其研究方向主要集中在通过自我合成方法生成大规模的对齐数据。该方法利用已对齐的大语言模型(LLM)自动生成用户查询,从而合成高质量的指令数据。研究结果表明,使用Magpie数据集进行监督微调(SFT)的模型性能在某些任务上可媲美官方的Llama-3-8B-Instruct模型。此外,该数据集在推理能力方面进行了增强,为提升模型在推理、数学、编码与调试等任务类别上的表现提供了重要资源。
以上内容由遇见数据集搜集并总结生成


