mevol/protein_structure_NER_model_v1.4
收藏Hugging Face2023-11-01 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/mevol/protein_structure_NER_model_v1.4
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
language:
- en
tags:
- biology
- protein structure
- token classification
configs:
- config_name: protein_structure_NER_model_v1.4
data_files:
- split: train
path: "annotation_IOB/train.tsv"
- split: dev
path: "annotation_IOB/dev.tsv"
- split: test
path: "annotation_IOB/test.tsv"
---
## Overview
This data was used to train model:
https://huggingface.co/mevol/BiomedNLP-PubMedBERT-ProteinStructure-NER-v1.4
There are 19 different entity types in this dataset:
"chemical", "complex_assembly", "evidence", "experimental_method", "gene", "mutant",
"oligomeric_state", "protein", "protein_state", "protein_type", "ptm", "residue_name",
"residue_name_number","residue_number", "residue_range", "site", "species", "structure_element",
"taxonomy_domain"
The data prepared as IOB formated input has been used during training, develiopment
and testing. Additional data formats such as JSON and XML as well as CSV files are
also available and are described below.
Annotation was carried out with the free annotation tool TeamTat (https://www.teamtat.org/) and
documents were downloaded as BioC XML before converting them to IOB, annotation only JSON and CSV format.
The number of annotations and sentences in each file is given below:
| document ID | number of annotations in BioC XML | number of annotations in IOB/JSON/CSV | number of sentences |
| --- | --- | --- | --- |
| PMC4850273 | 1121 | 1121 | 204 |
| PMC4784909 | 865 | 865 | 204 |
| PMC4850288 | 716 | 708 | 146 |
| PMC4887326 | 933 | 933 | 152 |
| PMC4833862 | 1044 | 1044 | 192 |
| PMC4832331 | 739 | 718 | 134 |
| PMC4852598 | 1229 | 1218 | 250 |
| PMC4786784 | 1549 | 1549 | 232 |
| PMC4848090 | 987 | 985 | 191 |
| PMC4792962 | 1268 | 1268 | 256 |
| PMC4841544 | 1434 | 1433 | 273 |
| PMC4772114 | 825 | 825 | 166 |
| PMC4872110 | 1276 | 1276 | 253 |
| PMC4848761 | 887 | 883 | 252 |
| PMC4919469 | 1628 | 1616 | 336 |
| PMC4880283 | 771 | 771 | 166 |
| PMC4937829 | 625 | 625 | 181 |
| PMC4968113 | 1238 | 1238 | 292 |
| PMC4854314 | 481 | 471 | 139 |
| PMC4871749 | 383 | 383 | 76 |
| total | 19999 | 19930 | 4095 |
Documents and annotations are easiest viewed by using the BioC XML files and opening
them in free annotation tool TeamTat. More about the BioC
format can be found here: https://bioc.sourceforge.net/
## Raw BioC XML files
These are the raw, un-annotated XML files for the publications in the dataset in BioC format.
The files are found in the directory: "raw_BioC_XML".
There is one file for each document and they follow standard naming
"unique PubMedCentral ID"_raw.xml.
## Annotations in IOB format
The IOB formated files can be found in the directory: "annotation_IOB"
The four files are as follows:
* all.tsv --> all sentences and annotations used to create model
"mevol/BiomedNLP-PubMedBERT-ProteinStructure-NER-v1.4"; 4095 sentences
* train.tsv --> training subset of the data; 2866 sentences
* dev.tsv --> development subset of the data; 614 sentences
* test.tsv --> testing subset of the data; 615 sentences
The total number of annotations is: 19930
## Annotations in BioC JSON
The BioC formated JSON files of the publications have been downloaded from the annotation
tool TeamTat. The files are found in the directory: "annotated_BioC_JSON"
There is one file for each document and they follow standard naming
"unique PubMedCentral ID"_ann.json
Each document JSON contains the following relevant keys:
* "sourceid" --> giving the numerical part of the unique PubMedCentral ID
* "text" --> containing the complete raw text of the publication as a string
* "denotations" --> containing a list of all the annotations for the text
Each annotation is a dictionary with the following keys:
* "span" --> gives the start and end of the annotatiom span defined by sub keys:
* "begin" --> character start position of annotation
* "end" --> character end position of annotation
* "obj" --> a string containing a number of terms that can be separated by ","; the order
of the terms gives the following: entity type, reference to ontology, annotator,
time stamp
* "id" --> unique annotation ID
Here an example:
```json
[{"sourceid":"4784909",
"sourcedb":"",
"project":"",
"target":"",
"text":"",
"denotations":[{"span":{"begin":24,
"end":34},
"obj":"chemical,CHEBI:,melaniev@ebi.ac.uk,2023-03-21T15:19:42Z",
"id":"4500"},
{"span":{"begin":50,
"end":59},
"obj":"taxonomy_domain,DUMMY:,melaniev@ebi.ac.uk,2023-03-21T15:15:03Z",
"id":"1281"}]
}
]
```
## Annotations in BioC XML
The BioC formated XML files of the publications have been downloaded from the annotation
tool TeamTat. The files are found in the directory: "annotated_BioC_XML"
There is one file for each document and they follow standard naming
"unique PubMedCentral ID_ann.xml
The key XML tags to be able to visualise the annotations in TeamTat as well as extracting
them to create the training data are "passage" and "offset". The "passage" tag encloses a
text passage or paragraph to which the annotations are linked. "Offset" gives the passage/
paragraph offset and allows to determine the character starting and ending postions of the
annotations. The tag "text" encloses the raw text of the passage.
Each annotation in the XML file is tagged as below:
* "annotation id=" --> giving the unique ID of the annotation
* "infon key="type"" --> giving the entity type of the annotation
* "infon key="identifier"" --> giving a reference to an ontology for the annotation
* "infon key="annotator"" --> giving the annotator
* "infon key="updated_at"" --> providing a time stamp for annotation creation/update
* "location" --> start and end character positions for the annotated text span
* "offset" --> start character position as defined by offset value
* "length" --> length of the annotation span; sum of "offset" and "length" creates
the end character position
Here is a basic example of what the BioC XML looks like. Additional tags for document
management are not given. Please refer to the documenttation to find out more.
```xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE collection SYSTEM "BioC.dtd">
<collection>
<source>PMC</source>
<date>20140719</date>
<key>pmc.key</key>
<document>
<id>4784909</id>
<passage>
<offset>0</offset>
<text>The Structural Basis of Coenzyme A Recycling in a Bacterial Organelle</text>
<annotation id="4500">
<infon key="type">chemical</infon>
<infon key="identifier">CHEBI:</infon>
<infon key="annotator">melaniev@ebi.ac.uk</infon>
<infon key="updated_at">2023-03-21T15:19:42Z</infon>
<location offset="24" length="10"/>
<text>Coenzyme A</text>
</annotation>
</passage>
</document>
</collection>
```
## Annotations in CSV
The annotations and the relevant sentences they have been found in have also been made
available as tab-separated CSV files, one for each publication in the dataset. The files can
be found in directory "annotation_CSV". Each file is named as "unique PubMedCentral ID".csv.
The column labels in the CSV files are as follows:
* "anno_start" --> character start position of the annotation
* "anno_end" --> character end position of the annotation
* "anno_text" --> text covered by the annotation
* "entity_type" --> entity type of the annotation
* "sentence" --> sentence text in which the annotation was found
* "section" --> publication section in which the annotation was found
## Annotations in JSON
A combined JSON file was created only containing the relevant sentences and associated
annotations for each publication in the dataset. The file can be found in directory
"annotation_JSON" under the name "annotations.json".
The following keys are used:
* "PMC4850273" --> unique PubMedCentral of the publication
* "annotations" --> list of dictionaries for the relevant, annotated sentences of the
document; each dictionary has the following sub keys
* "sid" --> unique sentence ID
* "sent" --> sentence text as string
* "section" --> publication section the sentence is in
* "ner" --> nested list of annotations; each sublist contains the following items:
start character position, end character position, annotation text,
entity type
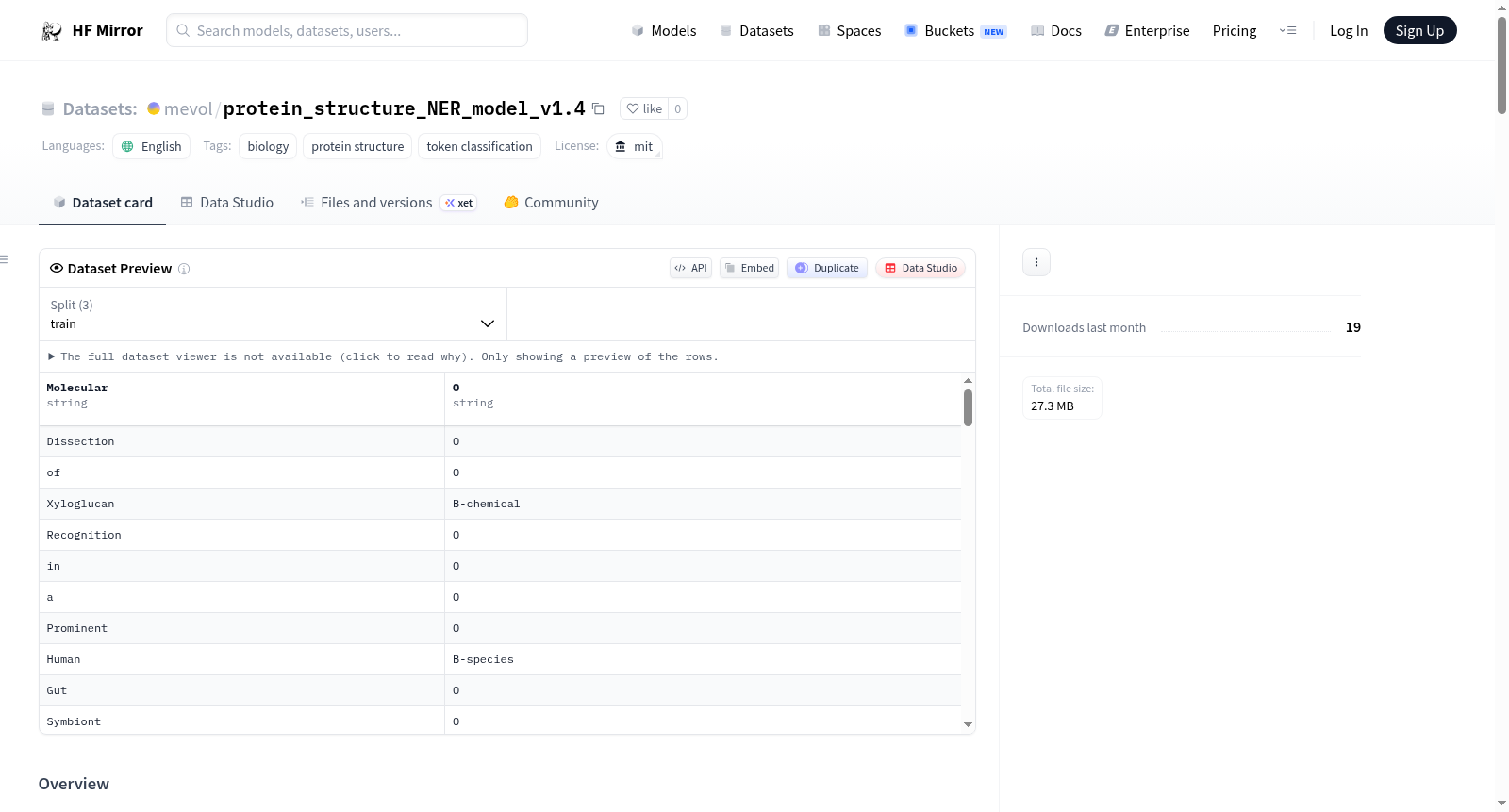
Here is an example of a sentence and its annotations:
```json
{"PMC4850273": {"annotations":
[{"sid": 0,
"sent": "Molecular Dissection of Xyloglucan Recognition in a Prominent Human Gut Symbiont",
"section": "TITLE",
"ner": [
[24,34,"Xyloglucan","chemical"],
[62,67,"Human","species"],]
},]
}}
```
提供机构:
mevol
原始信息汇总
数据集概述
数据集用途
该数据集用于训练蛋白质结构命名实体识别(NER)模型。
实体类型
数据集中包含19种不同的实体类型:
- chemical
- complex_assembly
- evidence
- experimental_method
- gene
- mutant
- oligomeric_state
- protein
- protein_state
- protein_type
- ptm
- residue_name
- residue_name_number
- residue_number
- residue_range
- site
- species
- structure_element
- taxonomy_domain
数据格式
数据以IOB格式准备,用于训练、开发和测试。此外,还提供JSON、XML和CSV格式的数据。
数据文件配置
- 配置名称: protein_structure_NER_model_v1.4
- 数据文件:
- 训练集:
annotation_IOB/train.tsv - 开发集:
annotation_IOB/dev.tsv - 测试集:
annotation_IOB/test.tsv
- 训练集:
数据统计
| document ID | 注释数量(BioC XML) | 注释数量(IOB/JSON/CSV) | 句子数量 |
|---|---|---|---|
| PMC4850273 | 1121 | 1121 | 204 |
| PMC4784909 | 865 | 865 | 204 |
| PMC4850288 | 716 | 708 | 146 |
| PMC4887326 | 933 | 933 | 152 |
| PMC4833862 | 1044 | 1044 | 192 |
| PMC4832331 | 739 | 718 | 134 |
| PMC4852598 | 1229 | 1218 | 250 |
| PMC4786784 | 1549 | 1549 | 232 |
| PMC4848090 | 987 | 985 | 191 |
| PMC4792962 | 1268 | 1268 | 256 |
| PMC4841544 | 1434 | 1433 | 273 |
| PMC4772114 | 825 | 825 | 166 |
| PMC4872110 | 1276 | 1276 | 253 |
| PMC4848761 | 887 | 883 | 252 |
| PMC4919469 | 1628 | 1616 | 336 |
| PMC4880283 | 771 | 771 | 166 |
| PMC4937829 | 625 | 625 | 181 |
| PMC4968113 | 1238 | 1238 | 292 |
| PMC4854314 | 481 | 471 | 139 |
| PMC4871749 | 383 | 383 | 76 |
| 总计 | 19999 | 19930 | 4095 |
数据文件目录
- 原始BioC XML文件:
raw_BioC_XML - IOB格式文件:
annotation_IOB - BioC JSON文件:
annotated_BioC_JSON - BioC XML文件:
annotated_BioC_XML - CSV文件:
annotation_CSV - JSON文件:
annotation_JSON
数据文件详情
-
IOB格式文件:
all.tsv: 包含所有用于创建模型的句子和注释,共4095个句子。train.tsv: 训练数据子集,共2866个句子。dev.tsv: 开发数据子集,共614个句子。test.tsv: 测试数据子集,共615个句子。- 注释总数: 19930
-
BioC JSON文件:
- 每个文档一个文件,命名格式为
unique PubMedCentral ID_ann.json。 - 包含以下键:
sourceid: 唯一PubMedCentral ID的数值部分。text: 出版物的完整原始文本。denotations: 文本的所有注释列表。
- 每个文档一个文件,命名格式为
-
BioC XML文件:
- 每个文档一个文件,命名格式为
unique PubMedCentral ID_ann.xml。 - 包含以下标签:
annotation id: 唯一注释ID。infon key="type": 注释的实体类型。infon key="identifier": 注释的参考本体。infon key="annotator": 注释者。infon key="updated_at": 注释创建/更新时间戳。location: 注释文本的起始和结束字符位置。
- 每个文档一个文件,命名格式为
-
CSV文件:
- 每个文档一个文件,命名格式为
unique PubMedCentral ID.csv。 - 包含以下列:
anno_start: 注释的起始字符位置。anno_end: 注释的结束字符位置。anno_text: 注释覆盖的文本。entity_type: 注释的实体类型。sentence: 包含注释的句子文本。section: 注释所在的出版物部分。
- 每个文档一个文件,命名格式为
-
JSON文件:
- 包含所有出版物的相关句子和关联注释的组合JSON文件,位于
annotation_JSON目录下,命名为annotations.json。 - 包含以下键:
PMC4850273: 出版物的唯一PubMedCentral ID。annotations: 文档的相关注释句子列表,每个句子包含以下子键:sid: 唯一句子ID。sent: 句子文本。section: 句子所在的出版物部分。ner: 嵌套的注释列表,每个子列表包含起始字符位置、结束字符位置、注释文本和实体类型。
- 包含所有出版物的相关句子和关联注释的组合JSON文件,位于
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个专注于蛋白质结构命名实体识别的生物医学数据集,包含19种不同的实体类型和多种注释格式,总注释数达19930个,覆盖4095个句子。尽管存在数据生成时的列不匹配问题,但数据集仍提供了丰富的生物医学文本注释资源。
以上内容由遇见数据集搜集并总结生成


