recaptchav2-dataset
收藏Hugging Face2025-04-20 更新2025-04-21 收录
下载链接:
https://huggingface.co/datasets/nobodyPerfecZ/recaptchav2-dataset
下载链接
链接失效反馈官方服务:
资源简介:
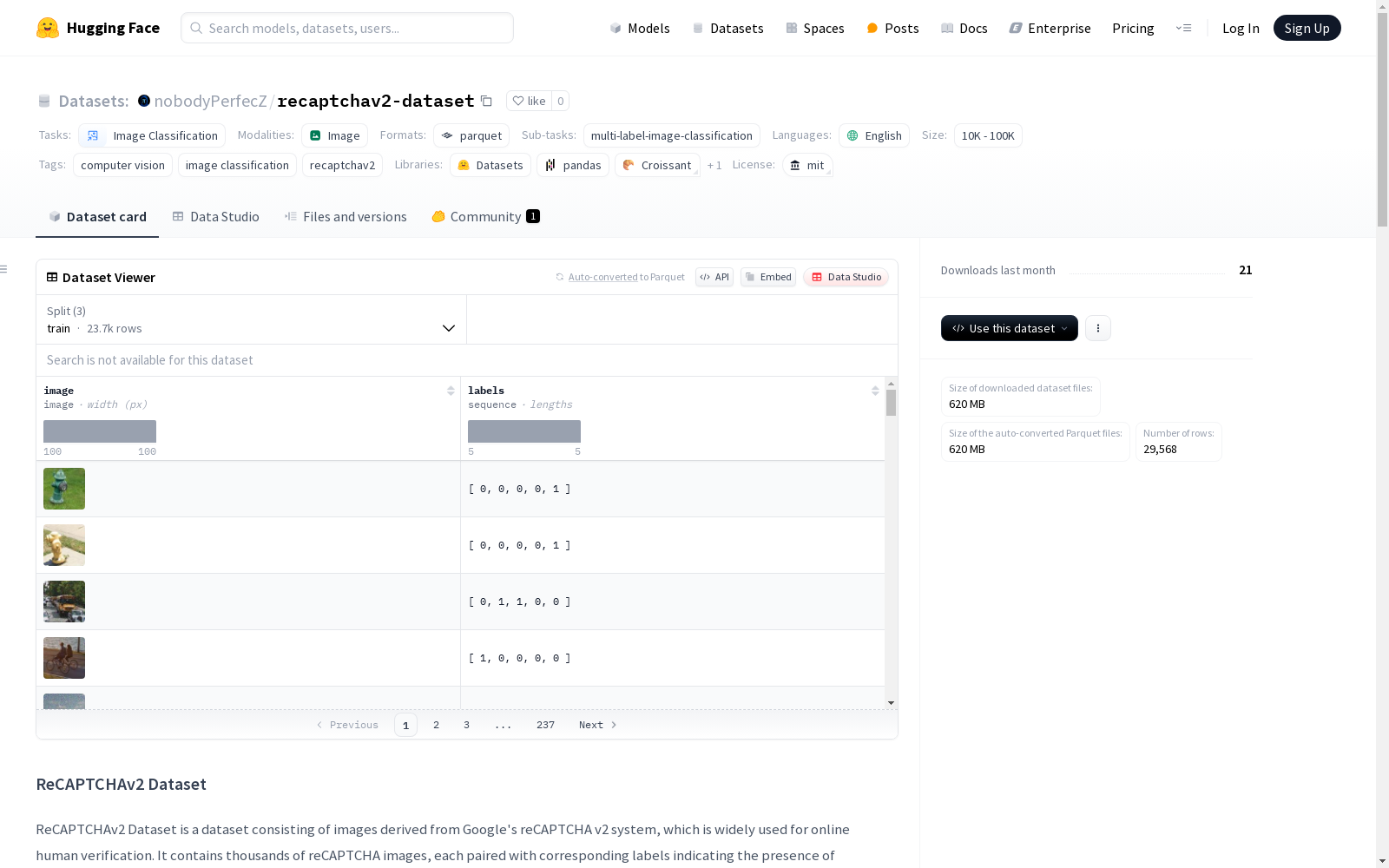
ReCAPTCHAv2数据集是一个专注于图像分类的计算机视觉数据集,包含大量图像,用于训练模型进行多标签图像分类。数据集规模适中,采用MIT许可证开源。
创建时间:
2025-04-17
搜集汇总
数据集介绍
构建方式
在计算机视觉领域,ReCAPTCHAv2数据集的构建体现了对真实世界验证系统的逆向工程研究。该数据集通过系统化爬取Google reCAPTCHAv2演示页面的验证图像,采用人工标注方式构建多标签分类体系。数据采集过程保留了原始验证机制中的视觉噪声和干扰元素,确保数据真实性。构建者采用类别分层抽样策略,将29,568张100x100像素图像按23,637:2,957:2,957的比例划分为训练集、验证集和测试集,维持了各类别在数据划分中的均衡分布。
使用方法
该数据集主要服务于多标签图像分类任务的算法研发,使用前需通过HuggingFace平台完成620MB数据的下载。典型应用流程包括:加载预处理后的PIL格式RGB图像,解析对应的五维标签向量。研究者可采用PyTorch或TensorFlow框架构建分类模型,建议利用内置的类别分层划分方案进行模型训练与验证。鉴于数据固有的地理和文化偏置,跨域测试时应谨慎评估模型泛化能力。为遵守使用规范,所有衍生研究必须明确声明非谷歌官方授权的性质,并严格限定于教育科研用途。
背景与挑战
背景概述
ReCAPTCHAv2数据集源于谷歌reCAPTCHA v2验证系统,该系统广泛应用于在线人类验证领域。该数据集由数千张验证码图像构成,每张图像均标注了特定物体或特征的存在情况(如自行车、公交车、汽车等)。作为计算机视觉领域的重要资源,该数据集为多标签图像分类和特征提取等任务提供了真实世界中的噪声数据,反映了验证码系统所面临的视觉识别挑战。数据集由研究人员通过网页爬取技术从谷歌reCAPTCHA v2演示页面收集,并经过人工标注处理,其构建旨在促进教育科研发展,而非商业用途。
当前挑战
该数据集面临多重挑战:在领域问题层面,验证码图像固有的视觉噪声和人为干扰因素对模型鲁棒性提出严峻考验,多标签分类任务需克服类别不平衡和语义模糊等难题;在构建过程中,数据采集受限于验证码系统的动态更新机制,标注工作需应对图像质量参差不齐的困境。地理与文化偏见问题尤为突出,数据过度代表欧美城市环境特征,可能影响模型在全球场景的泛化能力。此外,数据集潜在的安全风险不容忽视,需防范其被滥用于破解验证系统的可能性。
常用场景
经典使用场景
在计算机视觉领域,ReCAPTCHAv2数据集为多标签图像分类任务提供了丰富的实验素材。该数据集源自谷歌reCAPTCHA v2系统,包含大量带有噪声的真实世界图像,涵盖自行车、公交车、汽车等多种常见物体类别。研究者可利用该数据集训练模型识别复杂场景中的多类物体,特别适合探索在噪声干扰下的鲁棒性图像识别算法。
解决学术问题
该数据集有效解决了计算机视觉领域的关键挑战——如何在真实噪声环境下实现准确的多标签分类。通过提供带有视觉干扰的CAPTCHA图像,它填补了干净实验室数据与复杂现实场景之间的鸿沟。其标注体系支持细粒度物体识别研究,为提升模型在对抗性条件下的泛化能力提供了基准测试平台。
实际应用
在实际应用中,该数据集训练的模型可增强网络服务的安全验证系统,优化自动驾驶的环境感知模块。教育机构将其用于机器学习课程实践,帮助学生理解真实数据处理的复杂性。网络安全领域则通过分析CAPTCHA破解技术,持续改进人机验证机制的防御能力。
数据集最近研究
最新研究方向
在计算机视觉领域,ReCAPTCHAv2数据集因其独特的真实世界噪声特征和多标签分类挑战,正成为对抗性样本生成和鲁棒性模型训练的热点研究对象。随着网络安全需求的升级,该数据集被广泛应用于验证码识别防御机制的研究,尤其在对抗攻击与防御的博弈中展现出重要价值。其蕴含的地理文化偏差特性,也推动了跨域泛化与公平性学习等新兴方向的发展,为构建更具包容性的视觉系统提供了基准测试平台。
以上内容由遇见数据集搜集并总结生成


