drone_fsd_dataset
收藏Hugging Face2026-01-21 更新2026-01-22 收录
下载链接:
https://huggingface.co/datasets/webxos/drone_fsd_dataset
下载链接
链接失效反馈官方服务:
资源简介:
这是一个无人机导航的强化学习数据集,描述了无人机在一个60×60的房间内导航的训练过程,房间内有15个静态和12个浮动障碍物。数据集包含了一次训练运行的详细信息,包括性能指标(如最佳时间、成功率、碰撞次数等)、网络架构(MLP策略/价值头)、文件列表(如策略权重、训练摘要、遥测数据等)和环境设置(如房间大小、难度、障碍物属性等)。数据集的预期用途包括分析早期PPO行为、研究探索与利用的权衡、可视化无人机轨迹以及作为未来无人机竞速/避障模型的基线。
创建时间:
2026-01-17
原始信息汇总
DRONE FSD DATASET 概述
数据集基本信息
- 许可证:MIT
- 任务类别:强化学习、机器人学
- 语言:英语
- 标签:无人机导航、强化学习数据集、threejs、PPO、遥测、路径规划
数据集描述
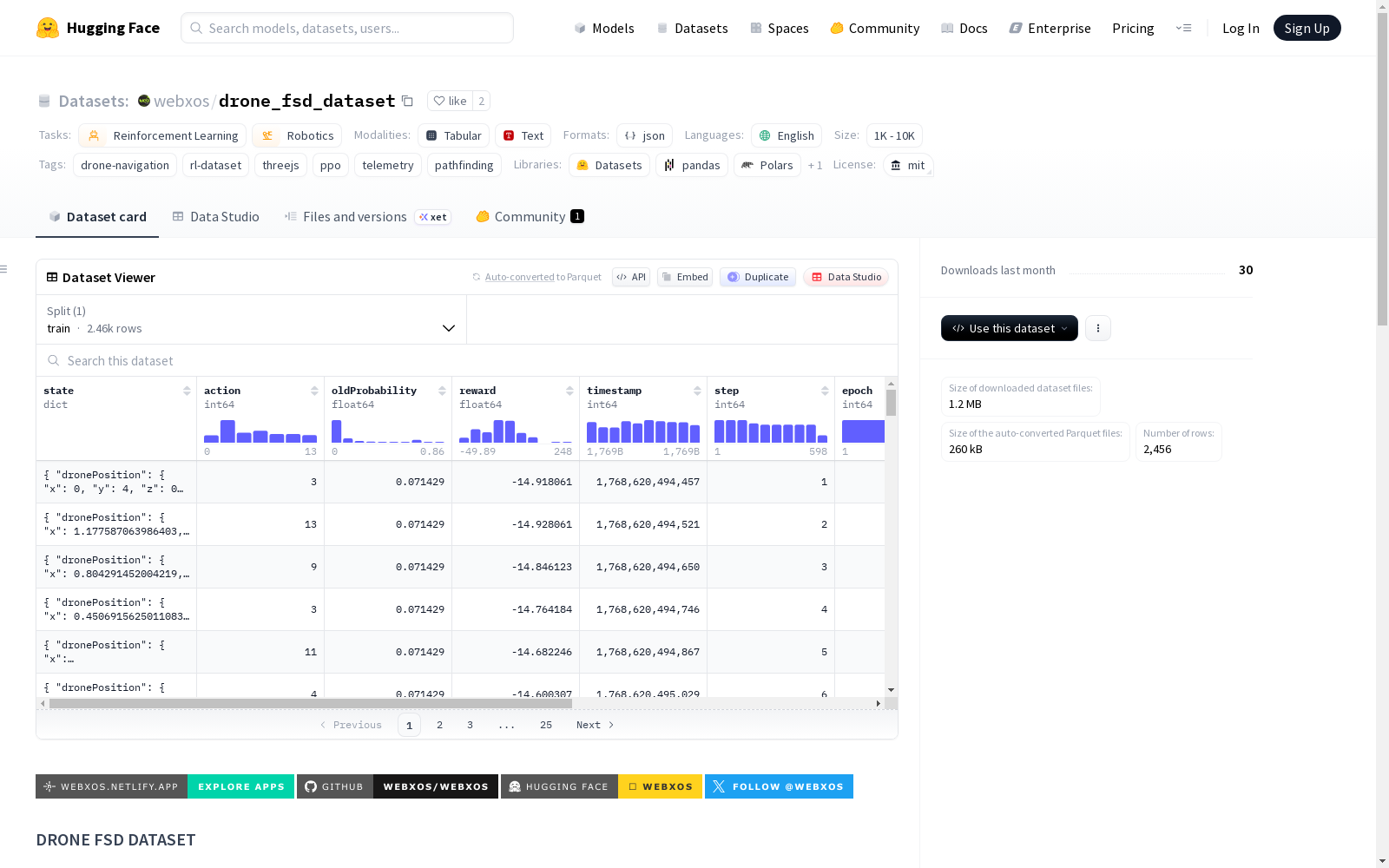
该数据集记录了无人机在60×60单位房间内进行单次训练运行(1个周期,4次迭代,198步)的导航数据。房间中包含15个静态障碍物和12个浮动障碍物。数据集由webXOS的MIRROR IDE生成。
最终性能指标(2456帧后)
- 最佳时间:43.821秒
- 成功率:0.0%(在最佳运行中到达东南角但未完成完整模式)
- 碰撞次数:最终记录路径中为0次
- 平均奖励:0.0732
- 累计奖励:49.24
- 最终探索率:0.784
- 最终学习率:5.40e-4
网络架构
- 架构:
[256 → 128 → 64 → 32](MLP策略/价值头) - 导出时间:2026-01-17 03:32 UTC
文件列表
| 文件 | 描述 | 大小 |
|---|---|---|
enhanced_network.json |
最终策略权重、形状及学习率 | ~small |
metadata.json |
训练摘要与配置 | ~small |
successful_paths.json |
最佳的3个部分成功路径(时间、路径) | ~small |
enhanced_telemetry.jsonl |
完整的每帧遥测数据(2456行) | ~2.4 MB |
enhanced_telemetry.csv |
CSV格式的相同数据 | ~1.8 MB |
training_experiences.jsonl |
PPO风格的状态转移数据(状态、动作、奖励、下一状态) | ~1.2 MB |
环境配置
- 房间尺寸:60单位
- 难度:1
- 障碍物:15个静态障碍物 + 12个浮动障碍物(速度0.2–0.5,反弹能量0.8)
- 目标模式:西北角 → 东南角 → 东北角 → 西南角 → 中心
- 奖励机制:主要基于距离,辅以少量塑形奖励
预期用途
- 分析PPO在3D连续控制任务中的早期行为
- 研究探索与利用的权衡(结束时探索率ε仍约为78%)
- 在Three.js、Unity或类似环境中可视化无人机轨迹
- 作为未来无人机竞速或避障模型的基线
搜集汇总
数据集介绍
构建方式
在无人机自主导航研究领域,数据集的构建方法直接影响算法的训练效果。drone_fsd_dataset通过MIRROR IDE工具生成,模拟了一个60×60单位尺寸的复杂三维空间,其中包含15个静态障碍物与12个以0.2至0.5速度浮动且具有0.8反弹能量的动态障碍物。数据集记录了一次完整的近端策略优化训练过程,涵盖一个训练周期内的四次迭代与198个步骤,最终采集了2456帧的详细遥测数据。其构建核心在于利用基于距离的奖励函数与少量塑形奖励,引导无人机按预设的西北至东南、再至东北、西南最终抵达中心的路径模式进行探索,从而在连续控制任务中捕获智能体在探索与利用之间的权衡行为。
特点
该数据集在机器人强化学习领域展现出鲜明的技术特征。其采用多层感知机构建的策略与价值网络,结构为256→128→64→32,专为三维连续控制任务设计。数据集不仅包含最终的网络权重与训练配置元数据,还提供了完整的每帧遥测记录以及符合近端策略优化格式的状态-动作-奖励转移序列。尤为突出的是,数据集明确记录了训练结束时尚有78.4%的探索率与5.40e-4的学习率,这为研究早期训练阶段智能体行为、分析碰撞规避策略以及评估部分成功路径提供了高保真、多模态的基准数据,特别适用于无人机竞速与动态避障模型的开发与验证。
使用方法
对于致力于无人机导航算法研发的研究者,该数据集提供了多维度的应用途径。用户可直接加载enhanced_telemetry.jsonl或CSV文件,对2456帧的飞行轨迹、奖励信号及传感器数据进行时序分析,以可视化手段在Three.js或Unity等三维引擎中重构飞行过程。同时,training_experiences.jsonl中的转移样本可用于行为克隆或离线强化学习算法的训练。研究者可进一步利用successful_paths.json中记录的最佳局部成功路径,分析智能体在复杂动态环境中的决策瓶颈,或将enhanced_network.json中的策略权重作为基线模型,进行迁移学习或性能比较研究,从而深入探索连续控制任务中探索与利用的平衡机制。
背景与挑战
背景概述
无人机自主导航作为机器人学与强化学习交叉领域的前沿课题,旨在实现智能体在复杂三维空间中的安全高效运动。drone_fsd_dataset由webXOS团队于2026年创建,聚焦于无人机在动态障碍环境中的路径规划问题。该数据集通过MIRROR IDE生成,记录了无人机在60×60单位空间内遵循特定航点序列的导航过程,其中包含静态与浮动障碍物。其核心研究价值在于为连续控制策略的早期训练阶段提供实证数据,尤其关注近端策略优化算法在三维环境中的探索与利用权衡,为无人机竞速与避障模型的开发奠定了基准。
当前挑战
该数据集致力于解决无人机在密集动态障碍环境中的自主导航挑战,其核心难点在于如何在连续动作空间中实现精确的航点追踪与实时避障。构建过程中的挑战主要体现在环境建模的复杂性上:需协调15个静态障碍与12个具有随机运动特性的浮动障碍,同时设计兼顾距离奖励与形态塑造的奖励函数以引导智能体学习。此外,数据集生成时探索率始终维持在较高水平,反映出智能体在训练早期尚未能稳定收敛至最优策略,这为研究探索与利用的平衡机制提供了典型样本。
常用场景
经典使用场景
在无人机导航与强化学习领域,drone_fsd_dataset为研究者提供了一个经典的仿真环境,用于探索连续控制任务中的智能体行为。该数据集记录了无人机在复杂三维空间中的完整训练历程,包括状态、动作、奖励及下一状态的序列,使得研究人员能够深入分析近端策略优化算法在早期训练阶段的表现。通过可视化无人机在静态与动态障碍物环境中的轨迹,该数据集成为评估路径规划与避障策略的基准平台。
解决学术问题
该数据集主要针对强化学习中的探索与利用权衡问题,提供了实证数据以剖析智能体在稀疏奖励环境下的学习动态。其解决了无人机导航研究中算法收敛性分析、奖励函数设计优化以及连续动作空间策略评估等核心学术挑战。通过公开训练过程中的完整遥测数据,该数据集促进了算法透明性与可复现性研究,为改进深度强化学习模型的样本效率与泛化能力提供了关键见解。
衍生相关工作
围绕该数据集,已衍生出一系列专注于无人机导航的经典研究工作。这些工作通常基于其提供的PPO训练经验数据,开发更高效的策略梯度算法或改进探索机制。部分研究利用数据集中包含的部分成功路径,设计分层强化学习框架以提升任务完成率。同时,该数据集也催生了针对多智能体协同导航与动态环境适应性的扩展研究,推动了无人机自主控制领域的算法创新与基准测试标准化。
以上内容由遇见数据集搜集并总结生成


