malaysia-ai/Malaysian-NSFW
收藏Hugging Face2024-07-09 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/malaysia-ai/Malaysian-NSFW
下载链接
链接失效反馈官方服务:
资源简介:
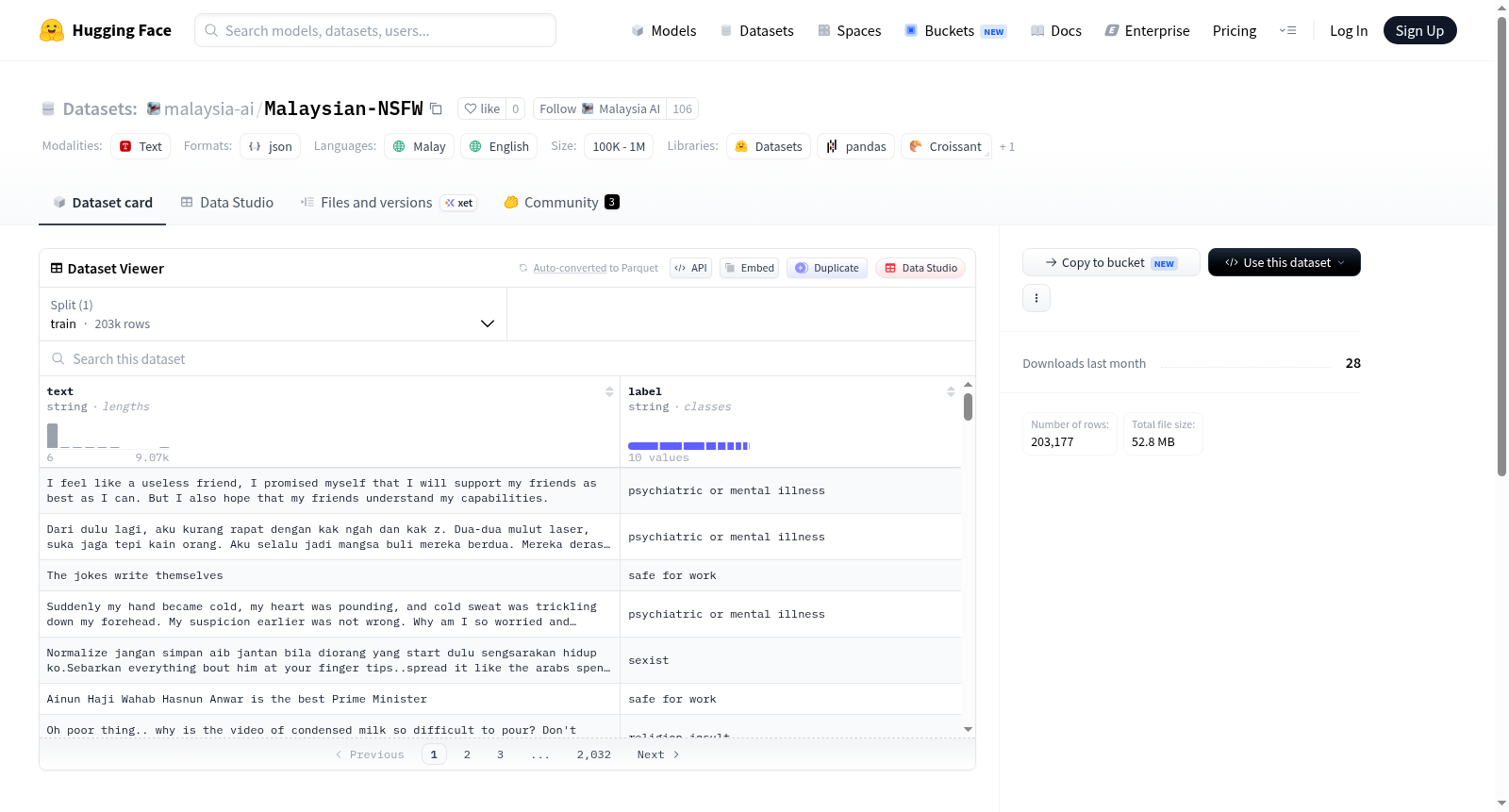
该数据集用于SFW(适合工作场所)分类器,支持马来语和英语。数据集包含多种标签,如宗教侮辱、性别歧视、种族歧视、精神病或精神疾病、骚扰、适合工作场所、色情、自残和暴力,旨在帮助识别和分类文本内容是否适合工作环境。
This dataset is for an SFW (Safe For Work) classifier, supporting Malay and English. It includes various labels such as religion insult, sexist, racist, psychiatric or mental illness, harassment, safe for work, porn, self-harm, and violence, aiming to help identify and classify whether text content is suitable for the workplace.
提供机构:
malaysia-ai
原始信息汇总
数据集概述
数据集名称
Dataset for SFW Classifier
支持语言
- 马来语 (ms)
- 英语 (en)
当前可用标签
- 宗教侮辱
- 性别歧视
- 种族歧视
- 精神或心理疾病
- 骚扰
- 适合工作场合
- 色情内容
- 自残行为
搜集汇总
数据集介绍
构建方式
在自然语言处理与内容安全领域,构建面向特定语言与文化背景的NSFW(Not Safe For Work)数据集至关重要。malaysia-ai/Malaysian-NSFW数据集由马来西亚人工智能社区精心构建,旨在为马来语及英语混合语境下的不当内容检测提供标注资源。该数据集采用多标签分类体系,通过人工标注方式对文本进行精细归类,涵盖宗教侮辱、性别歧视、种族歧视、精神疾病攻击、骚扰、色情内容、自残行为及暴力等八大类别,同时包含安全内容作为基准参照。
特点
该数据集的核心特色在于其针对马来西亚多元文化社会的敏感性设计,不仅覆盖了常见的NSFW类别如色情与暴力,还特别纳入宗教侮辱、种族歧视等地域性敏感话题,体现了对当地社会规范与文化语境的深度理解。此外,数据集采用双语标注(马来语与英语),增强了模型在跨语言场景下的泛化能力。其多标签分类体系允许单条文本同时归属多个不当类别,更贴合真实世界中复杂的内容审核需求。
使用方法
使用该数据集时,研究者可将其加载为训练集或评估集,用于微调或评估文本分类模型。推荐采用多标签分类框架,如基于Transformer的预训练模型(如BERT、XLM-R),通过调整输出层为多标签Sigmoid激活函数进行训练。数据应按照8:1:1比例划分为训练、验证与测试集,以平衡类别分布。评估指标可选用宏平均F1分数与精确率-召回率曲线,以全面衡量模型在各类别上的表现。
背景与挑战
背景概述
在数字内容审核领域,马来西亚语与英语混合的多语言环境对有害内容检测提出了独特挑战。由马来西亚人工智能社区(malaysia-ai)创建的Malaysian-NSFW数据集,旨在填补东南亚语言文化背景下安全内容分类的空白。该数据集聚焦于宗教侮辱、性别歧视、种族主义、精神疾病攻击、骚扰、色情、自残与暴力等敏感类别,为训练适用于马来西亚社会文化语境的NSFW分类器提供基础。其核心研究问题在于如何精准识别并过滤具有本土文化特征的有害内容,从而推动内容审核系统在多元文化环境中的公平性与有效性。
当前挑战
该数据集面临的核心挑战包括:其一,多语言混杂与本土化表达使得传统基于关键词或单一语言模型的分类器难以准确捕捉隐晦的歧视性或暴力性语言,例如宗教侮辱与种族主义常嵌入文化隐喻;其二,自残与精神疾病相关标签涉及高度敏感内容,标注过程需兼顾医学伦理与主观判断,数据构建中标注者偏差与隐私保护成为技术难点;其三,数据类别间边界模糊,如骚扰与性别歧视可能重叠,导致模型在细粒度分类中易产生混淆,影响实际部署的鲁棒性。
常用场景
经典使用场景
在内容审核与网络治理领域,马来西亚语与英语混合的社交媒体内容常因文化语境复杂而难以精准识别不当信息。Malaysian-NSFW数据集专为训练安全内容分类器而设计,其经典使用场景是构建多标签分类模型,以自动检测宗教侮辱、性别歧视、种族主义、精神疾病歧视、骚扰、色情、自残及暴力等九类有害内容,并区分安全与不安全信息。该数据集通过对马来语和英语文本的联合标注,填补了低资源语言环境下NSFW分类数据的空白,为东南亚地区的内容过滤系统提供了关键的训练基础。
解决学术问题
该数据集有效解决了跨语言内容审核中标注数据稀缺的结构性难题,尤其是在马来语主导的社交媒体生态下,现有模型常因语言特异性与文化敏感性不足而误判。学术研究中,它助力探索多标签文本分类、小样本学习及领域自适应等前沿问题,例如如何平衡类别不平衡、如何融合双语特征以提升泛化能力。其意义在于推动了低资源语言的自然语言处理研究,为构建公平且文化包容的审核算法提供了实证基准,并引发了关于言论自由与内容监管边界的社会技术讨论。
衍生相关工作
基于Malaysian-NSFW数据集,学术界衍生出一系列经典工作,包括针对马来语-英语混合文本的多任务学习框架,以及融合文化先验知识的少样本NSFW分类器。研究者还提出了类别平衡采样算法与对抗性去偏方法,以缓解宗教与种族标签中的潜在偏见。此外,该数据集被用于评估大型语言模型在多语言有害内容检测中的鲁棒性,并催生了面向东南亚语种的NSFW分类基准排行榜,推动了跨文化内容审核技术的标准化进程。
以上内容由遇见数据集搜集并总结生成


