35,608 materials with topological properties
收藏arXiv2025-03-21 更新2025-03-25 收录
下载链接:
https://topoclass.modl-uclouvain.org/
下载链接
链接失效反馈官方服务:
资源简介:
该数据集由比利时鲁汶大学和北京国家实验室等机构合作构建,总计包含35,608个具有不同拓扑性质的材料。这些材料是通过结合Materiae数据库和拓扑材料数据库中的密度泛函理论(DFT)结果得到的。数据集覆盖了五种不同的拓扑类型,旨在利用机器学习技术对材料进行分类,并探索影响材料拓扑性质的关键特征。
This dataset was collaboratively constructed by institutions including KU Leuven (Belgium) and Beijing National Laboratory, among others, with a total of 35,608 materials featuring distinct topological properties. These materials were derived by combining density functional theory (DFT) results from the Materiae database and the Topological Materials Database. The dataset covers five distinct topological categories, and is designed to enable material classification via machine learning techniques, as well as to explore the key features that influence the topological properties of materials.
提供机构:
UCLouvain, 比利时鲁汶大学
创建时间:
2025-03-21
搜集汇总
数据集介绍
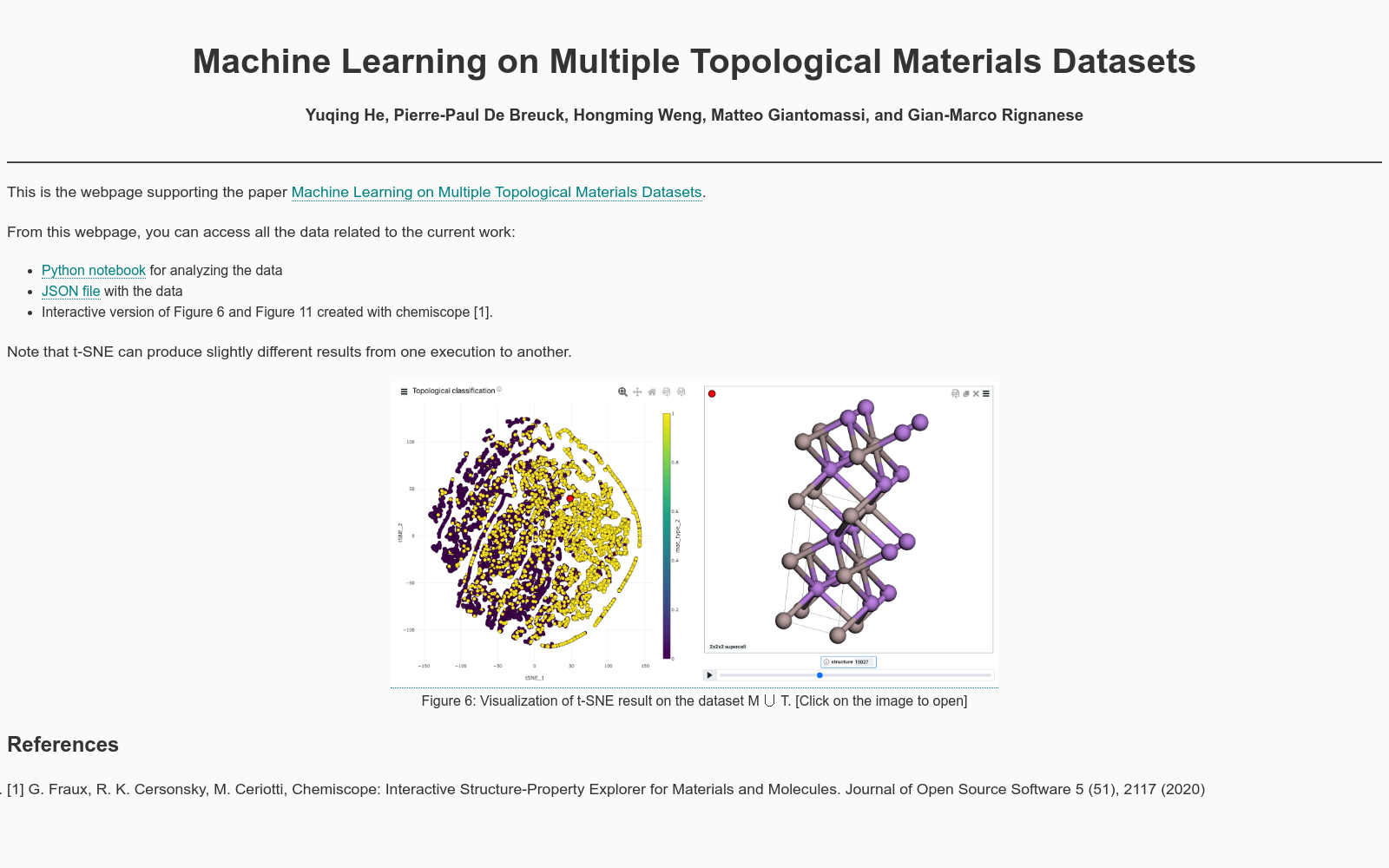
构建方式
该数据集通过整合Materiae和拓扑材料数据库(Topological Materials Database)的密度泛函理论(DFT)计算结果构建而成,共包含35,608种材料的拓扑性质。数据构建过程包括严格的清洗和标准化步骤,确保数据的一致性和可靠性。具体而言,数据集M从Materiae中提取25,683种化合物,数据集T则从拓扑材料数据库中提取24,156种化合物,并通过结构匹配和MP-ID分配确保数据的准确性。最终,通过去除重复和冲突的拓扑类型标签,形成统一的数据集。
特点
该数据集的特点在于其全面性和多样性。它不仅覆盖了多种拓扑类型(如TrI、HSPSM、HSLSM、TI和TCI),还包含了丰富的化学元素和晶体结构信息。数据集中的材料通过对称性指标理论和拓扑量子化学理论进行分类,具有明确的物理意义。此外,数据集还提供了材料的最大堆积效率(MPE)和p价电子分数(FPV)等关键特征,为机器学习模型提供了丰富的输入信息。
使用方法
该数据集可用于训练和评估机器学习模型,以分类材料的拓扑性质。具体而言,用户可以通过嵌套交叉验证(NCV)方法评估模型的性能,或在不同子数据集(如M\T、M∩T和T\M)上进行泛化测试。数据集还支持二进制分类任务(如区分TrI和NTM),并提供了多种特征(如MPE和FPV)用于模型训练。此外,用户可以通过Materials Cloud Archive访问数据,并利用chemiscope工具进行交互式可视化分析。
背景与挑战
背景概述
数据集“35,608 materials with topological properties”由比利时鲁汶大学凝聚态与纳米科学研究所、中国科学院物理研究所等机构的研究团队于2025年构建,整合了Materiae和Topological Materials Database的密度泛函理论计算结果。该数据集聚焦拓扑电子材料领域,旨在通过机器学习方法解决材料拓扑性质分类的核心科学问题,将材料划分为五种拓扑类型(平凡绝缘体、高对称点半金属、高对称线半金属、拓扑绝缘体和拓扑晶体绝缘体)。作为目前规模最大的拓扑材料数据库之一,其通过融合不同数据源实现了数据广度的突破,为拓扑量子化学与对称性指标理论的验证提供了重要平台,并推动了基于机器学习的材料设计范式发展。
当前挑战
该数据集面临双重挑战:在科学问题层面,需解决拓扑材料分类中局部化学环境与全局对称性特征的权衡问题,例如最大堆积效率(MPE)和p价电子分数(FPV)等关键描述符的识别;在构建过程中,需克服数据异构性难题,包括两个原始数据库间1%的拓扑类型冲突、磁序化合物标注缺失(占T\M数据集50%)、以及稀土元素因赝势差异导致的计算结果不一致。此外,特征空间覆盖不均衡导致模型在T\M子集的泛化性能下降13.9%,需通过严格的材料筛选和特征工程来提升数据一致性。
常用场景
经典使用场景
在凝聚态物理和材料科学领域,35,608种拓扑性质材料数据集为研究拓扑电子材料的分类和预测提供了重要资源。该数据集通过结合密度泛函理论(DFT)计算结果和拓扑材料数据库,为机器学习模型训练提供了丰富的数据支持。XGBoost模型在该数据集上实现了85.2%的分类准确率,能够将材料分为五种不同的拓扑类型,包括拓扑绝缘体(TI)、拓扑晶体绝缘体(TCI)等。
解决学术问题
该数据集解决了拓扑材料研究中的关键问题,包括如何高效分类材料的拓扑性质以及识别影响材料拓扑特性的主要特征。通过机器学习方法,研究者能够在不依赖复杂计算的情况下,快速预测材料的拓扑性质。数据集还揭示了最大堆积效率(MPE)和p价电子分数(FPV)是区分拓扑材料与非拓扑材料的关键特征,为后续研究提供了重要线索。
衍生相关工作
该数据集衍生了一系列经典研究工作,包括基于XGBoost的拓扑材料分类模型、基于topogivity的启发式分类方法以及基于t-SNE的无监督学习框架。这些工作不仅验证了数据集的可靠性,还进一步拓展了其在材料科学中的应用范围。例如,Claussen等人利用类似数据集开发了基于对称性和化学成分的拓扑材料预测模型,而Andrejevic等人则探索了X射线吸收近边结构(XANES)在拓扑材料识别中的潜力。
以上内容由遇见数据集搜集并总结生成


