renumics/cifar100-enriched
收藏Hugging Face2023-06-06 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/renumics/cifar100-enriched
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
task_categories:
- image-classification
pretty_name: CIFAR-100
source_datasets:
- extended|other-80-Million-Tiny-Images
paperswithcode_id: cifar-100
size_categories:
- 10K<n<100K
tags:
- image classification
- cifar-100
- cifar-100-enriched
- embeddings
- enhanced
- spotlight
- renumics
language:
- en
multilinguality:
- monolingual
annotations_creators:
- crowdsourced
language_creators:
- found
---
# Dataset Card for CIFAR-100-Enriched (Enhanced by Renumics)
## Dataset Description
- **Homepage:** [Renumics Homepage](https://renumics.com/?hf-dataset-card=cifar100-enriched)
- **GitHub** [Spotlight](https://github.com/Renumics/spotlight)
- **Dataset Homepage** [CS Toronto Homepage](https://www.cs.toronto.edu/~kriz/cifar.html#:~:text=The%20CIFAR%2D100%20dataset)
- **Paper:** [Learning Multiple Layers of Features from Tiny Images](https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf)
### Dataset Summary
📊 [Data-centric AI](https://datacentricai.org) principles have become increasingly important for real-world use cases.
At [Renumics](https://renumics.com/?hf-dataset-card=cifar100-enriched) we believe that classical benchmark datasets and competitions should be extended to reflect this development.
🔍 This is why we are publishing benchmark datasets with application-specific enrichments (e.g. embeddings, baseline results, uncertainties, label error scores). We hope this helps the ML community in the following ways:
1. Enable new researchers to quickly develop a profound understanding of the dataset.
2. Popularize data-centric AI principles and tooling in the ML community.
3. Encourage the sharing of meaningful qualitative insights in addition to traditional quantitative metrics.
📚 This dataset is an enriched version of the [CIFAR-100 Dataset](https://www.cs.toronto.edu/~kriz/cifar.html).
### Explore the Dataset
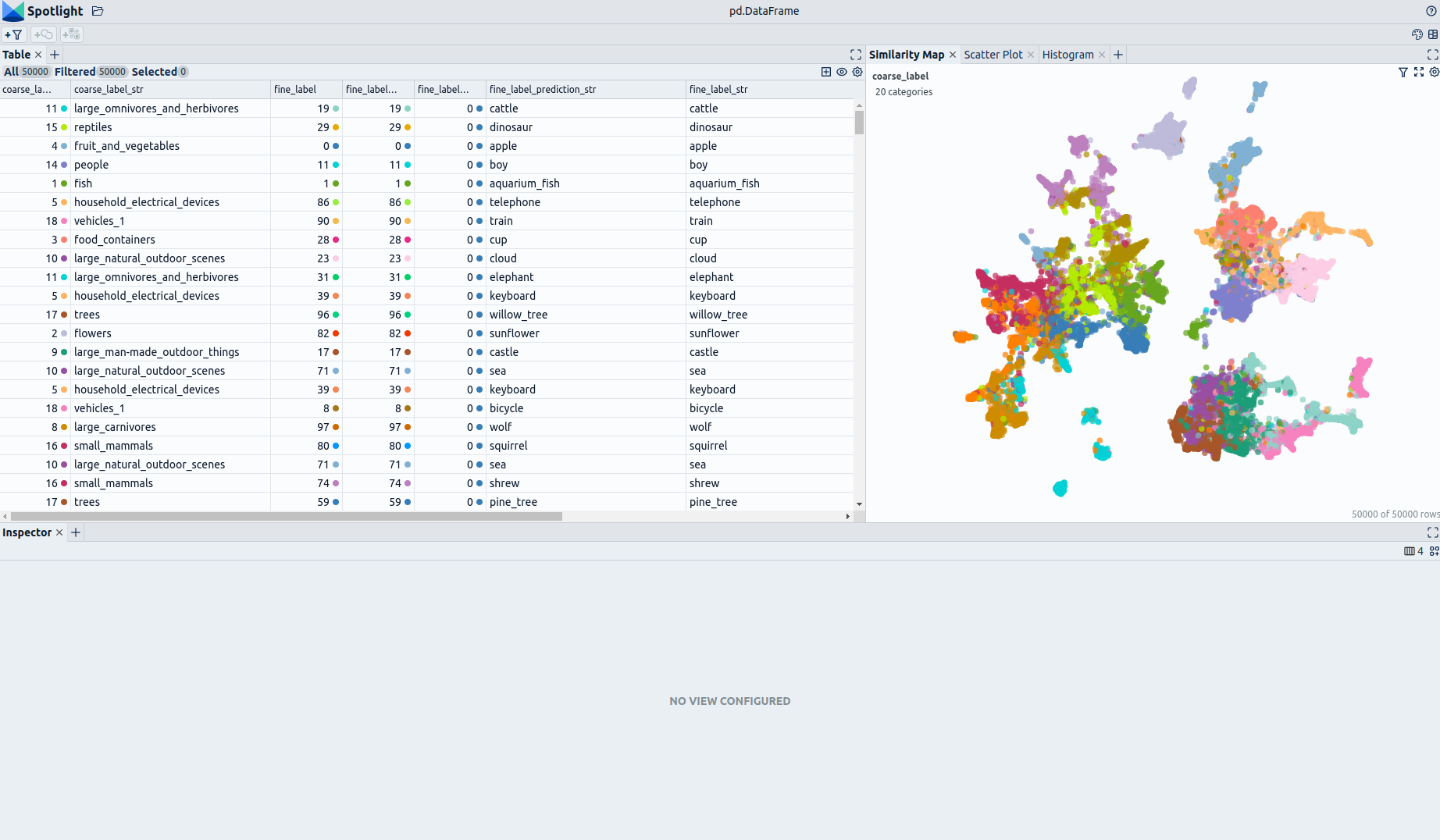
The enrichments allow you to quickly gain insights into the dataset. The open source data curation tool [Renumics Spotlight](https://github.com/Renumics/spotlight) enables that with just a few lines of code:
Install datasets and Spotlight via [pip](https://packaging.python.org/en/latest/key_projects/#pip):
```python
!pip install renumics-spotlight datasets
```
Load the dataset from huggingface in your notebook:
```python
import datasets
dataset = datasets.load_dataset("renumics/cifar100-enriched", split="train")
```
Start exploring with a simple view that leverages embeddings to identify relevant data segments:
```python
from renumics import spotlight
df = dataset.to_pandas()
df_show = df.drop(columns=['embedding', 'probabilities'])
spotlight.show(df_show, port=8000, dtype={"image": spotlight.Image, "embedding_reduced": spotlight.Embedding})
```
You can use the UI to interactively configure the view on the data. Depending on the concrete tasks (e.g. model comparison, debugging, outlier detection) you might want to leverage different enrichments and metadata.
### CIFAR-100 Dataset
The CIFAR-100 dataset consists of 60000 32x32 colour images in 100 classes, with 600 images per class. There are 50000 training images and 10000 test images.
The 100 classes in the CIFAR-100 are grouped into 20 superclasses. Each image comes with a "fine" label (the class to which it belongs) and a "coarse" label (the superclass to which it belongs).
The classes are completely mutually exclusive.
We have enriched the dataset by adding **image embeddings** generated with a [Vision Transformer](https://huggingface.co/google/vit-base-patch16-224).
Here is the list of classes in the CIFAR-100:
| Superclass | Classes |
|---------------------------------|----------------------------------------------------|
| aquatic mammals | beaver, dolphin, otter, seal, whale |
| fish | aquarium fish, flatfish, ray, shark, trout |
| flowers | orchids, poppies, roses, sunflowers, tulips |
| food containers | bottles, bowls, cans, cups, plates |
| fruit and vegetables | apples, mushrooms, oranges, pears, sweet peppers |
| household electrical devices | clock, computer keyboard, lamp, telephone, television|
| household furniture | bed, chair, couch, table, wardrobe |
| insects | bee, beetle, butterfly, caterpillar, cockroach |
| large carnivores | bear, leopard, lion, tiger, wolf |
| large man-made outdoor things | bridge, castle, house, road, skyscraper |
| large natural outdoor scenes | cloud, forest, mountain, plain, sea |
| large omnivores and herbivores | camel, cattle, chimpanzee, elephant, kangaroo |
| medium-sized mammals | fox, porcupine, possum, raccoon, skunk |
| non-insect invertebrates | crab, lobster, snail, spider, worm |
| people | baby, boy, girl, man, woman |
| reptiles | crocodile, dinosaur, lizard, snake, turtle |
| small mammals | hamster, mouse, rabbit, shrew, squirrel |
| trees | maple, oak, palm, pine, willow |
| vehicles 1 | bicycle, bus, motorcycle, pickup truck, train |
| vehicles 2 | lawn-mower, rocket, streetcar, tank, tractor |
### Supported Tasks and Leaderboards
- `image-classification`: The goal of this task is to classify a given image into one of 100 classes. The leaderboard is available [here](https://paperswithcode.com/sota/image-classification-on-cifar-100).
### Languages
English class labels.
## Dataset Structure
### Data Instances
A sample from the training set is provided below:
```python
{
'image': '/huggingface/datasets/downloads/extracted/f57c1a3fbca36f348d4549e820debf6cc2fe24f5f6b4ec1b0d1308a80f4d7ade/0/0.png',
'full_image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=32x32 at 0x7F15737C9C50>,
'fine_label': 19,
'coarse_label': 11,
'fine_label_str': 'cattle',
'coarse_label_str': 'large_omnivores_and_herbivores',
'fine_label_prediction': 19,
'fine_label_prediction_str': 'cattle',
'fine_label_prediction_error': 0,
'split': 'train',
'embedding': [-1.2482988834381104,
0.7280710339546204, ...,
0.5312759280204773],
'probabilities': [4.505949982558377e-05,
7.286163599928841e-05, ...,
6.577593012480065e-05],
'embedding_reduced': [1.9439491033554077, -5.35720682144165]
}
```
### Data Fields
| Feature | Data Type |
|---------------------------------|------------------------------------------------|
| image | Value(dtype='string', id=None) |
| full_image | Image(decode=True, id=None) |
| fine_label | ClassLabel(names=[...], id=None) |
| coarse_label | ClassLabel(names=[...], id=None) |
| fine_label_str | Value(dtype='string', id=None) |
| coarse_label_str | Value(dtype='string', id=None) |
| fine_label_prediction | ClassLabel(names=[...], id=None) |
| fine_label_prediction_str | Value(dtype='string', id=None) |
| fine_label_prediction_error | Value(dtype='int32', id=None) |
| split | Value(dtype='string', id=None) |
| embedding | Sequence(feature=Value(dtype='float32', id=None), length=768, id=None) |
| probabilities | Sequence(feature=Value(dtype='float32', id=None), length=100, id=None) |
| embedding_reduced | Sequence(feature=Value(dtype='float32', id=None), length=2, id=None) |
### Data Splits
| Dataset Split | Number of Images in Split | Samples per Class (fine) |
| ------------- |---------------------------| -------------------------|
| Train | 50000 | 500 |
| Test | 10000 | 100 |
## Dataset Creation
### Curation Rationale
The CIFAR-10 and CIFAR-100 are labeled subsets of the [80 million tiny images](http://people.csail.mit.edu/torralba/tinyimages/) dataset.
They were collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton.
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
If you use this dataset, please cite the following paper:
```
@article{krizhevsky2009learning,
added-at = {2021-01-21T03:01:11.000+0100},
author = {Krizhevsky, Alex},
biburl = {https://www.bibsonomy.org/bibtex/2fe5248afe57647d9c85c50a98a12145c/s364315},
interhash = {cc2d42f2b7ef6a4e76e47d1a50c8cd86},
intrahash = {fe5248afe57647d9c85c50a98a12145c},
keywords = {},
pages = {32--33},
timestamp = {2021-01-21T03:01:11.000+0100},
title = {Learning Multiple Layers of Features from Tiny Images},
url = {https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf},
year = 2009
}
```
### Contributions
Alex Krizhevsky, Vinod Nair, Geoffrey Hinton, and Renumics GmbH.
---
许可证: MIT协议
任务类别:
- 图像分类
展示名称: CIFAR-100
源数据集:
- 扩展|其他-8000万微小图像数据集
PapersWithCode标识: cifar-100
规模类别:
- 10000<样本数<100000
标签:
- 图像分类
- cifar-100
- cifar-100-enriched
- 嵌入(embeddings)
- 增强版
- Spotlight
- Renumics
语言:
- 英语
多语言属性:
- 单语言
标注创建者:
- 众包
语言创建方式:
- 现有文本
---
# CIFAR-100增强版数据集卡片(由Renumics增强)
## 数据集描述
- **官方主页:** [Renumics官方网站](https://renumics.com/?hf-dataset-card=cifar100-enriched)
- **GitHub仓库:** [Spotlight](https://github.com/Renumics/spotlight)
- **数据集官方主页:** [多伦多大学计算机科学系页面](https://www.cs.toronto.edu/~kriz/cifar.html#:~:text=The%20CIFAR%2D100%20dataset)
- **相关论文:** [从微小图像中学习多层特征](https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf)
### 数据集概述
📊 以数据为中心的人工智能(Data-centric AI)理念在实际业务场景中的重要性与日俱增。
在[Renumics](https://renumics.com/?hf-dataset-card=cifar100-enriched),我们认为应当对经典基准数据集与竞赛进行扩展,以契合这一发展趋势。
🔍 基于此,我们发布了带有应用场景专属增强内容的基准数据集(例如嵌入(embeddings)、基准结果、不确定性估计、标签错误评分等)。我们希望此举能从以下方面助力机器学习社区:
1. 帮助新手研究人员快速深入理解该数据集。
2. 在机器学习社区中推广以数据为中心的人工智能理念与工具链。
3. 鼓励除传统量化指标之外,分享更具价值的定性分析结论。
📚 本数据集是[CIFAR-100数据集](https://www.cs.toronto.edu/~kriz/cifar.html)的增强版本。
### 数据集探索

这些增强内容可帮助您快速洞悉数据集全貌。开源数据管理工具[Renumics Spotlight](https://github.com/Renumics/spotlight)仅需数行代码即可实现该功能:
通过[pip](https://packaging.python.org/en/latest/key_projects/#pip)安装依赖包与Spotlight:
python
!pip install renumics-spotlight datasets
在Notebook中从Hugging Face加载数据集:
python
import datasets
dataset = datasets.load_dataset("renumics/cifar100-enriched", split="train")
通过基于嵌入(embeddings)的简易可视化视图即可开始探索数据集,快速定位目标数据片段:
python
from renumics import spotlight
df = dataset.to_pandas()
df_show = df.drop(columns=['embedding', 'probabilities'])
spotlight.show(df_show, port=8000, dtype={"image": spotlight.Image, "embedding_reduced": spotlight.Embedding})
您可通过可视化界面交互式配置数据视图。根据具体任务需求(例如模型对比、模型调试、异常值检测等),可灵活选用不同的增强内容与元数据。
### CIFAR-100原始数据集
CIFAR-100数据集包含100个类别的60000张32×32彩色图像,每个类别包含600张图像。其中训练集包含50000张图像,测试集包含10000张图像。
CIFAR-100的100个类别被划分为20个超类别。每张图像均带有一个“细粒度标签”(标注其所属的基础类别)与一个“粗粒度标签”(标注其所属的超类别)。
所有类别之间完全互斥。
我们通过添加由[视觉Transformer(Vision Transformer)](https://huggingface.co/google/vit-base-patch16-224)生成的**图像嵌入(image embeddings)**对原数据集进行了增强。
以下为CIFAR-100的类别列表:
| 超类别 | 类别列表 |
|----------------------------|----------------------------------------------------|
| 水生哺乳动物 | 海狸、海豚、水獭、海豹、鲸 |
| 鱼类 | 观赏鱼、比目鱼、鳐鱼、鲨鱼、鳟鱼 |
| 花卉 | 兰花、罂粟花、玫瑰、向日葵、郁金香 |
| 食品容器 | 瓶子、碗、罐、杯子、盘子 |
| 水果与蔬菜 | 苹果、蘑菇、橙子、梨、甜椒 |
| 家用电气设备 | 时钟、电脑键盘、台灯、电话、电视机 |
| 家用家具 | 床、椅子、沙发、桌子、衣柜 |
| 昆虫 | 蜜蜂、甲虫、蝴蝶、毛毛虫、蟑螂 |
| 大型食肉动物 | 熊、豹、狮子、老虎、狼 |
| 大型人造户外设施 | 桥梁、城堡、房屋、道路、摩天大楼 |
| 大型自然户外场景 | 云朵、森林、山脉、平原、海洋 |
| 大型杂食与草食动物 | 骆驼、牛、黑猩猩、大象、袋鼠 |
| 中型哺乳动物 | 狐狸、豪猪、负鼠、浣熊、臭鼬 |
| 非昆虫无脊椎动物 | 螃蟹、龙虾、蜗牛、蜘蛛、蠕虫 |
| 人物 | 婴儿、男孩、女孩、男人、女人 |
| 爬行动物 | 鳄鱼、恐龙、蜥蜴、蛇、乌龟 |
| 小型哺乳动物 | 仓鼠、小鼠、兔子、鼩鼱、松鼠 |
| 树木 | 枫树、橡树、棕榈树、松树、柳树 |
| 交通工具1 | 自行车、公共汽车、摩托车、皮卡、火车 |
| 交通工具2 | 割草机、火箭、有轨电车、坦克、拖拉机 |
### 支持任务与排行榜
- `图像分类(image-classification)`:该任务的目标是将给定图像分类至100个类别之一。相关排行榜可参见[此处](https://paperswithcode.com/sota/image-classification-on-cifar-100)。
### 语言说明
类别标签使用英语标注。
## 数据集结构
### 数据样例
以下展示训练集的一条数据样例:
python
{
'image': '/huggingface/datasets/downloads/extracted/f57c1a3fbca36f348d4549e820debf6cc2fe24f5f6b4ec1b0d1308a80f4d7ade/0/0.png',
'full_image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=32x32 at 0x7F15737C9C50>,
'fine_label': 19,
'coarse_label': 11,
'fine_label_str': 'cattle',
'coarse_label_str': 'large_omnivores_and_herbivores',
'fine_label_prediction': 19,
'fine_label_prediction_str': 'cattle',
'fine_label_prediction_error': 0,
'split': 'train',
'embedding': [-1.2482988834381104,
0.7280710339546204, ...,
0.5312759280204773],
'probabilities': [4.505949982558377e-05,
7.286163599928841e-05, ...,
6.577593012480065e-05],
'embedding_reduced': [1.9439491033554077, -5.35720682144165]
}
### 数据字段
| 字段名称 | 数据类型 |
|---------------------------------|------------------------------------------------|
| image | 值类型(Value),数据类型为字符串(string) |
| full_image | 图像类型(Image),支持解码(decode=True) |
| fine_label | 分类标签(ClassLabel),包含类别名称列表,id为None |
| coarse_label | 分类标签(ClassLabel),包含类别名称列表,id为None |
| fine_label_str | 值类型(Value),数据类型为字符串(string) |
| coarse_label_str | 值类型(Value),数据类型为字符串(string) |
| fine_label_prediction | 分类标签(ClassLabel),包含类别名称列表,id为None |
| fine_label_prediction_str | 值类型(Value),数据类型为字符串(string) |
| fine_label_prediction_error | 值类型(Value),数据类型为int32 |
| split | 值类型(Value),数据类型为字符串(string) |
| embedding | 序列类型(Sequence),元素为float32类型值,长度为768 |
| probabilities | 序列类型(Sequence),元素为float32类型值,长度为100 |
| embedding_reduced | 序列类型(Sequence),元素为float32类型值,长度为2 |
### 数据划分
| 数据集划分 | 图像数量 | 每类样本数(细粒度) |
| ------------- |---------------------------| -------------------------|
| 训练集 | 50000 | 500 |
| 测试集 | 10000 | 100 |
## 数据集构建
### 构建初衷
CIFAR-10与CIFAR-100均为[8000万微小图像数据集](http://people.csail.mit.edu/torralba/tinyimages/)的带标签子集。
该数据集由Alex Krizhevsky、Vinod Nair与Geoffrey Hinton采集整理。
### 源数据
#### 初始数据采集与标准化
[待补充更多信息]
#### 源文本创作者是谁?
[待补充更多信息]
### 标注信息
#### 标注流程
[待补充更多信息]
#### 标注人员是谁?
[待补充更多信息]
### 个人与敏感信息
[待补充更多信息]
## 数据集使用注意事项
### 数据集社会影响
[待补充更多信息]
### 偏见分析
[待补充更多信息]
### 其他已知局限性
[待补充更多信息]
## 补充信息
### 数据集维护者
[待补充更多信息]
### 许可证信息
[待补充更多信息]
### 引用信息
若您使用本数据集,请引用以下论文:
@article{krizhevsky2009learning,
added-at = {2021-01-21T03:01:11.000+0100},
author = {Krizhevsky, Alex},
biburl = {https://www.bibsonomy.org/bibtex/2fe5248afe57647d9c85c50a98a12145c/s364315},
interhash = {cc2d42f2b7ef6a4e76e47d1a50c8cd86},
intrahash = {fe5248afe57647d9c85c50a98a12145c},
keywords = {},
pages = {32--33},
timestamp = {2021-01-21T03:01:11.000+0100},
title = {Learning Multiple Layers of Features from Tiny Images},
url = {https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf},
year = 2009
}
### 贡献者
Alex Krizhevsky、Vinod Nair、Geoffrey Hinton与Renumics GmbH。
提供机构:
renumics
原始信息汇总
数据集概述
- 数据集名称: CIFAR-100-Enriched
- 数据集版本: 增强版,由Renumics提供
- 数据集类别: 图像分类
- 数据集大小: 10K<n<100K
- 数据集标签: 图像分类, cifar-100, cifar-100-enriched, embeddings, enhanced, spotlight, renumics
- 语言: 英语
- 多语言性: 单语种
- 注释创建者: 众包
- 语言创建者: 已发现
数据集详细描述
- 数据集概要: 该数据集是CIFAR-100的增强版本,增加了图像嵌入等应用特定富集内容,旨在帮助机器学习社区更好地理解和应用数据中心AI原则。
- 数据集内容: 包含60000张32x32彩色图像,分为100个类别,每个类别有600张图像。数据集包括50000张训练图像和10000张测试图像。每个图像附带一个“精细”标签和一个“粗糙”标签。
- 数据集增强: 通过添加由Vision Transformer生成的图像嵌入进行增强。
- 数据集结构:
- 数据实例: 每个实例包括图像路径、完整图像、精细标签、粗糙标签、标签预测等信息。
- 数据字段: 包括图像、完整图像、标签、预测、嵌入等数据类型。
- 数据分割: 训练集50000张图像,测试集10000张图像。
数据集使用
- 探索数据集: 使用Renumics Spotlight工具可以快速分析和探索数据集,通过简单的代码即可加载和显示数据。
- 支持的任务: 图像分类,目标是将图像分类到100个类别中的一个。
- 语言: 英语类标签。
数据集创建
- 来源数据: CIFAR-10和CIFAR-100是80 million tiny images数据集的标记子集,由Alex Krizhevsky, Vinod Nair, 和 Geoffrey Hinton收集。
- 贡献者: Alex Krizhevsky, Vinod Nair, Geoffrey Hinton, 和 Renumics GmbH。
引用信息
@article{krizhevsky2009learning, added-at = {2021-01-21T03:01:11.000+0100}, author = {Krizhevsky, Alex}, biburl = {https://www.bibsonomy.org/bibtex/2fe5248afe57647d9c85c50a98a12145c/s364315}, interhash = {cc2d42f2b7ef6a4e76e47d1a50c8cd86}, intrahash = {fe5248afe57647d9c85c50a98a12145c}, keywords = {}, pages = {32--33}, timestamp = {2021-01-21T03:01:11.000+0100}, title = {Learning Multiple Layers of Features from Tiny Images}, url = {https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf}, year = 2009 }
搜集汇总
数据集介绍
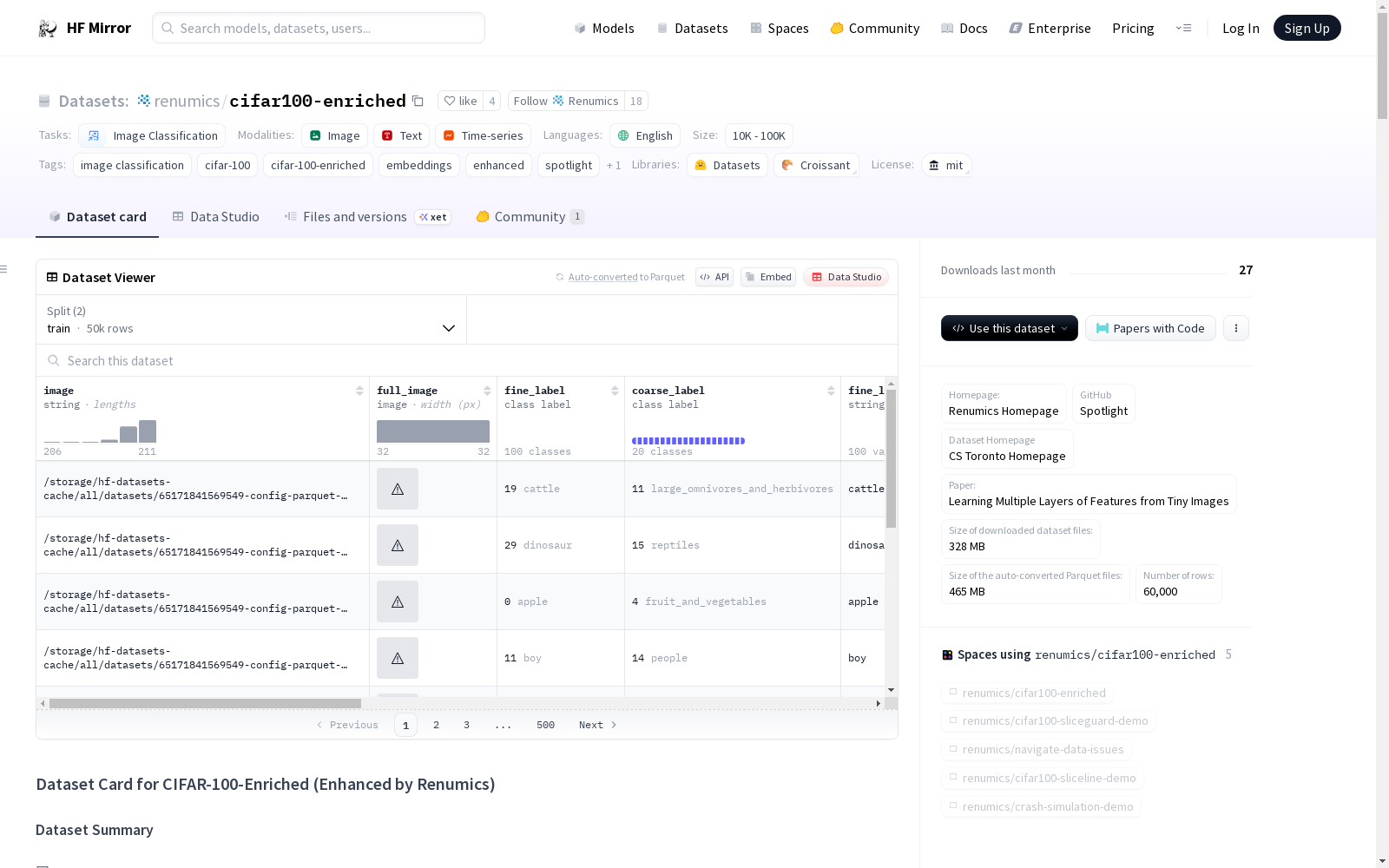
构建方式
CIFAR-100-Enriched数据集是在原始CIFAR-100数据集的基础上,通过添加图像嵌入等应用特定增强而构建的。该数据集源于80百万小图像数据集的子集,经过精心标注,每个类别包含500个训练样本和100个测试样本,总计包含50000个训练图像和10000个测试图像。数据集的构建旨在为机器学习社区提供一种具有丰富信息的资源,以便研究人员能够快速深入理解数据集,并推动数据为中心的人工智能原则在机器学习领域中的应用。
特点
CIFAR-100-Enriched数据集的特点在于其丰富的增强信息,包括图像嵌入、基线结果、不确定性、标签错误分数等。这些增强信息使得数据集不仅包含传统的图像分类数据,还提供了额外的定性和定量分析工具,有助于研究人员从多个维度探索和理解数据。此外,数据集还提供了细粒度和粗粒度标签,使得对图像的理解更加全面。
使用方法
使用CIFAR-100-Enriched数据集,用户可以通过Hugging Face的datasets库轻松加载数据。借助Renumics Spotlight这一开源数据整理工具,用户可以仅用几行代码即可开始探索数据集。通过交互式界面,用户可以配置数据视图,进行模型比较、调试、异常值检测等任务,从而高效地利用数据集的丰富信息。
背景与挑战
背景概述
CIFAR-100数据集,由Alex Krizhevsky, Vinod Nair和Geoffrey Hinton于2009年创建,是一个包含60000张32x32彩色图像的图像分类数据集,涵盖100个类别。这些图像分为50000张训练图像和10000张测试图像,每个类别有600张图像。CIFAR-100的类别进一步划分为20个超类别,每个图像同时具有细粒度标签和粗粒度标签。该数据集旨在促进对小型图像进行多层特征学习的研究,并对图像分类领域产生了深远影响。Renumics公司对该数据集进行了增强,添加了图像嵌入等应用特定富集信息,以支持数据为中心的人工智能原则在机器学习社区的应用和推广。
当前挑战
在构建CIFAR-100数据集时,研究人员面临了多个挑战,包括如何从80 million tiny images数据集中筛选和标注合适的图像,以及如何平衡不同类别之间的样本分布。此外,Renumics在增强数据集时,也遇到了如何有效整合额外信息(如嵌入)以提升数据集实用性的挑战。在研究领域问题方面,CIFAR-100数据集的挑战包括提高图像分类的准确性,尤其是在细粒度分类任务中,以及如何减少标签错误对模型性能的影响。
常用场景
经典使用场景
在深入研究图像分类领域时,CIFAR-100 Enriched数据集因其丰富的图像特征和标签信息,成为了学者们进行基准测试的经典选择。该数据集不仅包含了细粒度的类别标签,还提供了图像的嵌入表示,使得研究人员能够高效地进行特征提取、模型训练与验证。
解决学术问题
CIFAR-100 Enriched数据集解决了图像分类研究中数据稀疏性和标签不一致性的问题。通过引入图像嵌入和基线结果等丰富信息,该数据集助力于提升模型的泛化能力和准确性,同时促进了数据驱动的人工智能原则在机器学习领域的普及。
衍生相关工作
基于CIFAR-100 Enriched数据集,学术界衍生出了一系列相关工作,包括但不限于图像嵌入技术的改进、细粒度图像分类方法的研究以及数据增强策略的探索,这些研究进一步推动了计算机视觉领域的理论进步和技术发展。
以上内容由遇见数据集搜集并总结生成


