Human-Preferences-Alignment-KTO-Dataset-AI-Services-Genuine-User-Reviews
收藏Hugging Face2024-10-29 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/DeepNLP/Human-Preferences-Alignment-KTO-Dataset-AI-Services-Genuine-User-Reviews
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是从AI服务(如ChatGPT、Gemini、Claude和Perplexity)的用户评论中提取的,经过转换以适应KTO(Kahneman-Tversky Optimisation)训练格式。评论根据评分被标记为'true'(选择)或'false'(拒绝),并分为训练集和测试集。数据集用于微调大型语言模型,以对齐用户偏好。
创建时间:
2024-10-29
原始信息汇总
Human Preferences Alignment KTO Dataset of AI Service User Reviews of ChatGPT Gemini Claude Perplexity
数据集概述
该数据集用于训练用户偏好对齐模型,特别是通过KTO(Kahneman-Tversky Optimisation)方法。数据集包含AI服务(如ChatGPT、Gemini、Claude、Perplexity)的用户评价,这些评价被转换为KTO训练格式,以便微调语言模型以对齐用户偏好。
数据集准备方法
- 数据来源:来自DeepNLP AI Store Users Open Review panel的用户评价。
- 数据筛选:评价总体评分大于等于4星的标记为“true”(选择),评分小于等于3星的标记为“false”(拒绝)。
- 数据格式:数据分为训练集和测试集,并以json格式存储,类似于KTO_Trainer教程和KTO-14K数据集。
数据集使用
- 数据可视化:使用DeepNLP Chat Visualizer工具可视化对话风格的prompt-completion列表。
- 模型微调:示例代码展示了如何使用该数据集微调Qwen2-0.5B小型语言模型。
参考文献
- RLHF Reinforcement Learning from Human Feedback
- DPO Direct Preference Optimization Equation and Paper
- KTO Kahneman-Tversky Optimisation Equation and Paper
- Huggingface TRL KTO Trainer
- Huggingface Dataset of AI Services Multi-Aspect User Reviews
- Data Source OpenAI o1 User Reviews
- Data Source ChatGPT User Reviews
- Data Source Gemini User Reviews
- Data Source Perplexity User Reviews
- Data Source of Claude User Reviews
- AI Agents & Dialogue Data Visualization Tools
- Multi-Agents Asynchronous Memory Timeline Visualization Tools
搜集汇总
数据集介绍
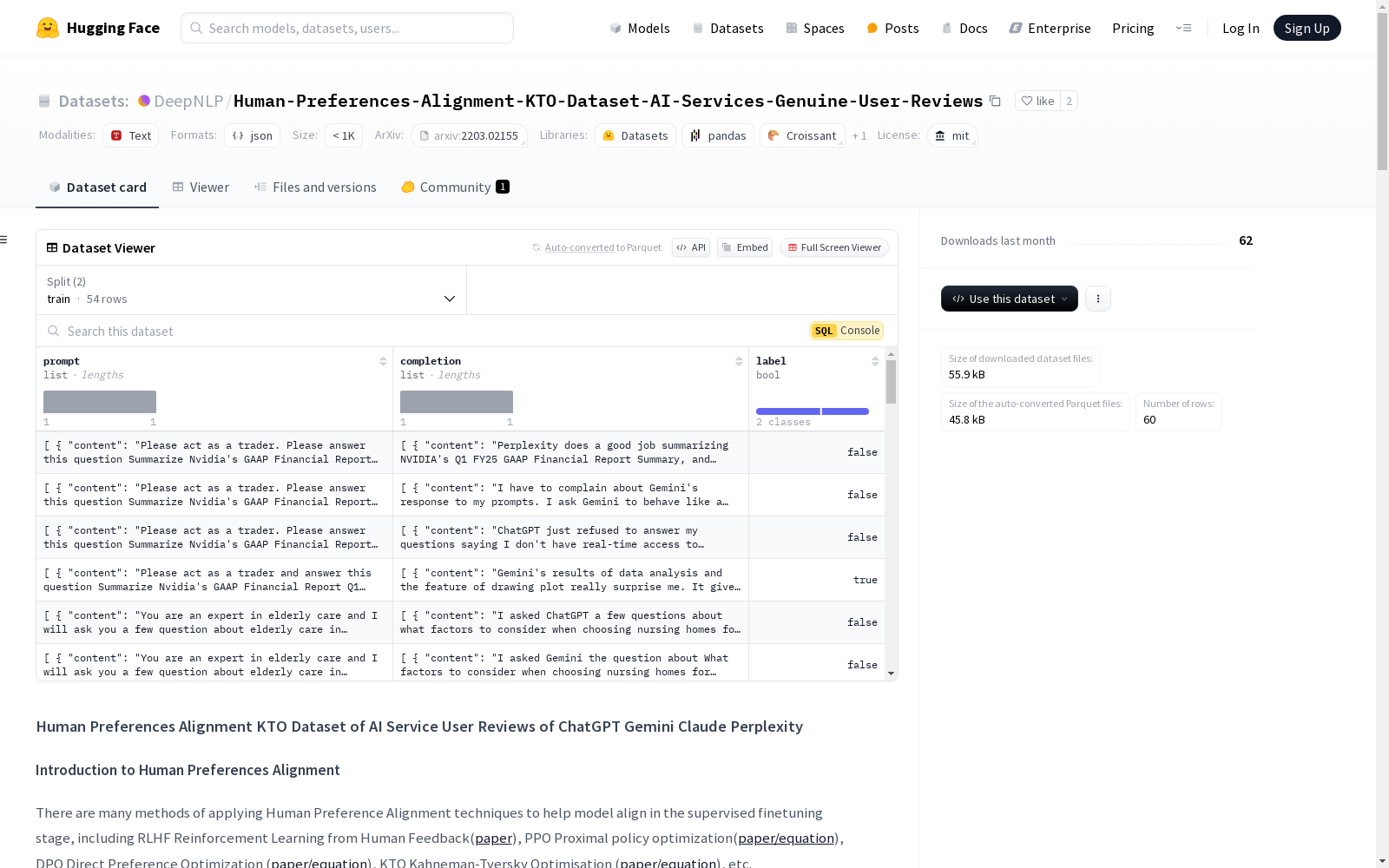
构建方式
该数据集通过转换AI服务用户评论数据为KTO(Kahneman-Tversky Optimisation)训练格式构建而成。具体而言,数据来源于DeepNLP AI Store用户开放评论面板,用户可以对AI服务的响应进行评分,评分范围为1至5星。评论数据根据评分进行筛选,4星及以上的评论标记为‘true’(选择),3星及以下的评论标记为‘false’(拒绝)。数据随后被分割为训练集和测试集,并以json格式存储,便于后续的模型微调。
特点
该数据集的特点在于其专注于用户对AI服务的真实反馈,涵盖了ChatGPT、Gemini、Claude和Perplexity等主流AI服务的用户评论。数据集通过评分机制将用户偏好转化为二元标签,简化了偏好对齐模型的训练过程。此外,数据集的设计支持在线学习更新,能够随着用户评论的增加而不断扩展,为模型提供持续优化的机会。
使用方法
该数据集主要用于微调大型语言模型(LLM),以使其更好地适应用户偏好。用户可以通过Hugging Face的`load_dataset`函数加载数据集,并结合`KTOTrainer`进行模型训练。训练过程中,模型会根据用户评论的二元标签进行优化,从而提升其在特定任务中的表现。此外,用户还可以使用DeepNLP Chat Visualizer工具对数据集中的对话数据进行可视化分析,进一步理解模型的偏好对齐效果。
背景与挑战
背景概述
Human-Preferences-Alignment-KTO-Dataset-AI-Services-Genuine-User-Reviews数据集由DeepNLP机构于2024年创建,旨在通过用户真实反馈优化大型语言模型(LLM)的偏好对齐。该数据集基于Kahneman-Tversky优化(KTO)方法,通过收集ChatGPT、Gemini、Claude和Perplexity等AI服务的用户评论,将其转换为KTO训练格式,以帮助模型在监督微调阶段更好地适应用户偏好。相较于传统的直接偏好优化(DPO)方法,KTO方法更适用于点对点的偏好评分,且数据获取更为便捷。该数据集的研究背景源于对LLM与人类偏好对齐的迫切需求,尤其是在多维度用户评价的背景下,如何有效提升模型的响应质量和用户满意度。
当前挑战
该数据集面临的挑战主要体现在两个方面。首先,在领域问题层面,如何准确捕捉用户偏好并将其有效应用于模型训练仍是一个复杂问题。用户评论的主观性和多样性使得偏好对齐的难度增加,尤其是在多维度评分(如正确性、帮助性、趣味性等)的背景下,模型需要具备更高的泛化能力。其次,在数据构建过程中,获取高质量的用户评论并对其进行标准化处理是一项艰巨任务。尽管KTO方法简化了数据需求,但如何确保评论数据的代表性和一致性,以及如何处理数据中的噪声和偏差,仍然是构建过程中的主要挑战。此外,数据集的规模和质量仍需进一步扩展和优化,以满足生产级应用的需求。
常用场景
经典使用场景
Human-Preferences-Alignment-KTO-Dataset-AI-Services-Genuine-User-Reviews数据集在自然语言处理领域中被广泛用于微调大型语言模型(LLM),以使其更好地适应用户偏好。通过将用户对AI服务(如ChatGPT、Gemini、Claude和Perplexity)的真实评价转化为KTO(Kahneman-Tversky Optimisation)格式,该数据集为模型提供了点对点的偏好评分数据,从而帮助模型在监督微调阶段实现与人类偏好的对齐。
实际应用
在实际应用中,该数据集被用于微调AI服务模型,以提升其在用户交互中的表现。通过分析用户对AI服务的真实评价,模型能够更好地理解用户的需求和偏好,从而生成更符合用户期望的响应。这一过程不仅提高了AI服务的用户满意度,还为AI服务的持续优化提供了数据支持。
衍生相关工作
该数据集衍生了一系列与人类偏好对齐相关的研究工作。例如,基于KTO方法的模型微调技术被广泛应用于各类AI服务中,如ChatGPT、Gemini等。此外,该数据集还为RLHF(Reinforcement Learning from Human Feedback)和DPO等传统偏好对齐方法提供了新的数据来源,推动了这些方法在实际应用中的进一步发展。
以上内容由遇见数据集搜集并总结生成


