有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
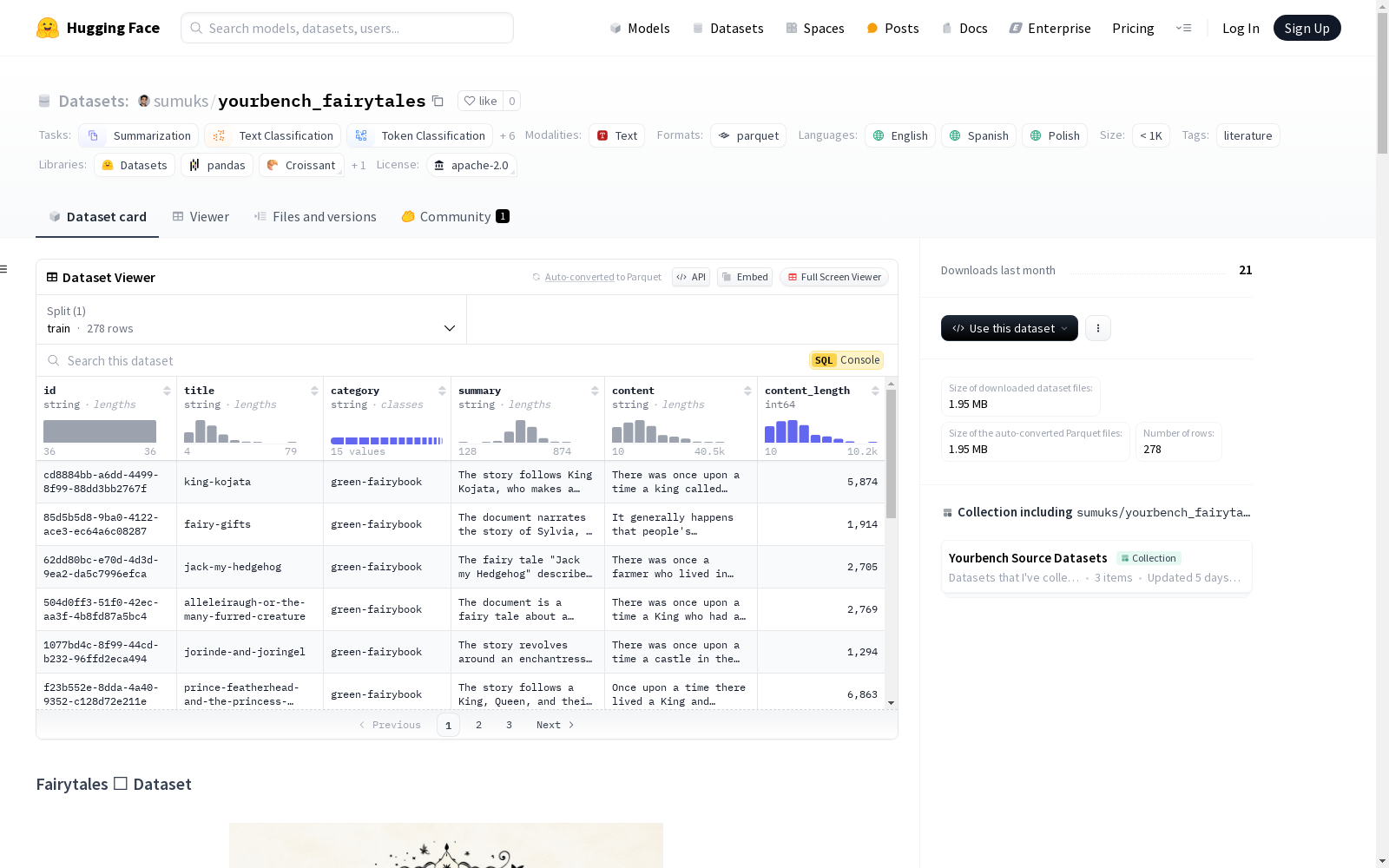
id: 字符串title: 字符串category: 字符串summary: 字符串content: 字符串content_length: 整数train: 278个样本,3328889字节 count
first-round 36 norwegian-fairybook 33 chinese-fairybook 28 native-american-fairybook 24 swedish-fairybook 23 lilac-fairybook 21 scottish-fairybook 19 andersen-fairybook 19 japanese-fairybook 19 irish-fairybook 15 beatrix-potter-fairybook 13 grimm-fairybook 11 blue-fairybook 8 green-fairybook 6 wonderclock-fairybook 3
gpt-4o-0824生成摘要。

python from datasets import load_dataset
dataset = load_dataset("sumuks/fairytales")
story = dataset[train][0] print(f"Title: {story[title]}") print(f"Category: {story[category]}") print(f"First 200 chars: {story[content][:200]}...")
TPTP
TPTP(Thousands of Problems for Theorem Provers)是一个包含大量逻辑问题的数据集,主要用于定理证明器的测试和评估。它包含了多种逻辑形式的问题,如一阶逻辑、高阶逻辑、命题逻辑等。
www.tptp.org 收录
中国行政区划数据
本项目为中国行政区划数据,包括省级、地级、县级、乡级和村级五级行政区划数据。数据来源于国家统计局,存储格式为sqlite3 db文件,支持直接使用数据库连接工具打开。
github 收录
US EPA Air Quality System (AQS)
US EPA Air Quality System (AQS) 数据集包含了美国各地的空气质量监测数据,包括污染物浓度、气象数据、监测站点信息等。该数据集用于监测和评估空气质量,支持环境政策和公众健康研究。
www.epa.gov 收录
CAP-DATA
CAP-DATA数据集由长安大学交通学院的研究团队创建,包含11,727个交通事故视频,总计超过2.19百万帧。该数据集不仅标注了事故发生的时间窗口,还提供了详细的文本描述,包括事故前的实际情况、事故类别、事故原因和预防建议。数据集的创建旨在通过结合视觉和文本信息,提高交通事故预测的准确性和解释性,从而支持更安全的驾驶决策系统。
arXiv 收录
Yahoo Finance
Dataset About finance related to stock market
kaggle 收录