CENSUS-NER-Name-Email-Address-Phone
收藏CENSUS-NER-Name-Email-Address-Phone 数据集概述
数据集摘要
CENSUS-NER-Name-Email-Address-Phone 数据集是 FMCSA(联邦汽车运输安全管理局)CENSUS1 2016Sep 数据集的加工和结构化版本。该数据集旨在帮助训练语言模型,用于命名实体识别(NER)、地址解析和非结构化文本信息提取等任务。数据集包含从原始数据集中提取的姓名、电子邮件、电话号码和地址等信息,并以适合自然语言处理(NLP)任务的结构化格式呈现。
关键特性
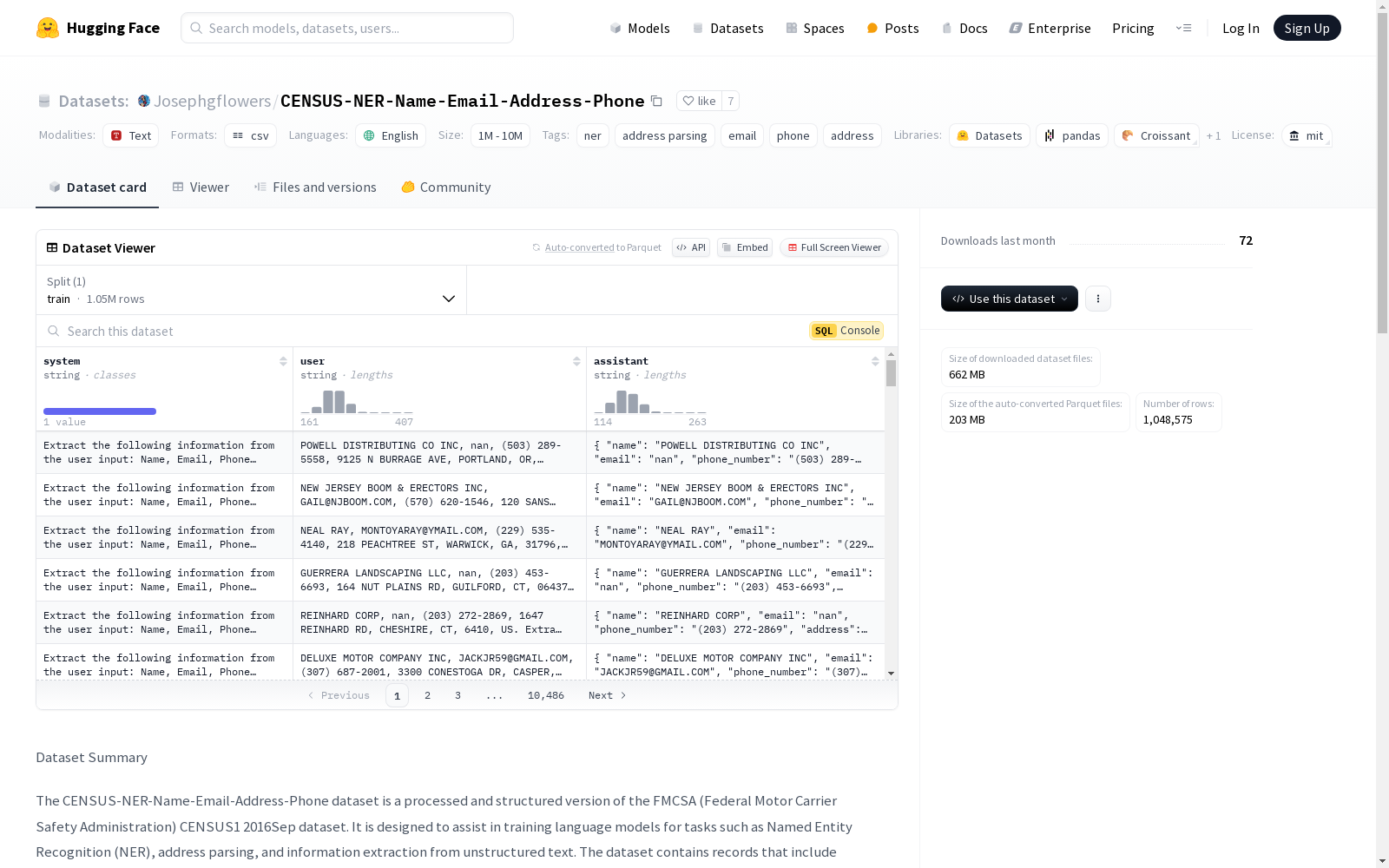
- 结构化数据:数据集分为三个关键列:system、user 和 assistant,代表 NLP 提示-响应交互的不同部分。
- 地址规范化:数据集包括规范化的地址信息,提取了门牌号、街道、城市、州、邮政编码和国家。
- 灵活的数据表示:数据集以 TXT 和 CSV 格式提供,适用于各种训练流程,包括微调语言模型和开发 AI 助手。
支持的任务
- 命名实体识别(NER)
- 地址解析
- 信息提取
- 自然语言处理(NLP)
源数据
原始数据来自 FMCSA CENSUS1 2016Sep 数据集,该数据集包含有关汽车运输公司的详细记录,包括联系信息和运营数据。数据集经过重组和处理,专注于提取和规范化关键信息字段,如姓名、电子邮件、电话号码和地址。
数据集结构
数据字段
- system:提供给模型的提示,指示其从用户输入中提取特定字段。
- user:包含模型从中提取信息的非结构化数据的输入文本。
- assistant:模型生成的输出,格式为 JSON,包含提取的字段:name、email、phone_number 和 address。
示例条目
json { "system": "从用户输入中提取以下信息:姓名、电子邮件、电话号码和地址。如果某个字段缺失,忽略它,不要输出任何关于该字段的信息。以 JSON 格式返回答案。", "user": "John Doe, john.doe@example.com, 555-1234, 123 Main St, Anytown, NY, 12345, USA. 额外信息:...", "assistant": { "name": "John Doe", "email": "john.doe@example.com", "phone_number": "555-1234", "address": "123 Main St, Anytown, NY, 12345, USA" } }
语言
数据集为英语,文本来自 FMCSA 维护的记录。
使用
该数据集可用于训练和评估模型,用于命名实体识别(NER)、地址解析和信息提取等任务。数据集的结构化特性使其非常适合微调需要从非结构化文本中理解和提取结构化信息的 NLP 模型。
致谢
我们感谢 FMCSA 提供原始数据集用于此项工作。他们维护和共享此类数据的承诺对研究社区至关重要。