nrl-ai/vn-spell-correction-eval
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/nrl-ai/vn-spell-correction-eval
下载链接
链接失效反馈官方服务:
资源简介:
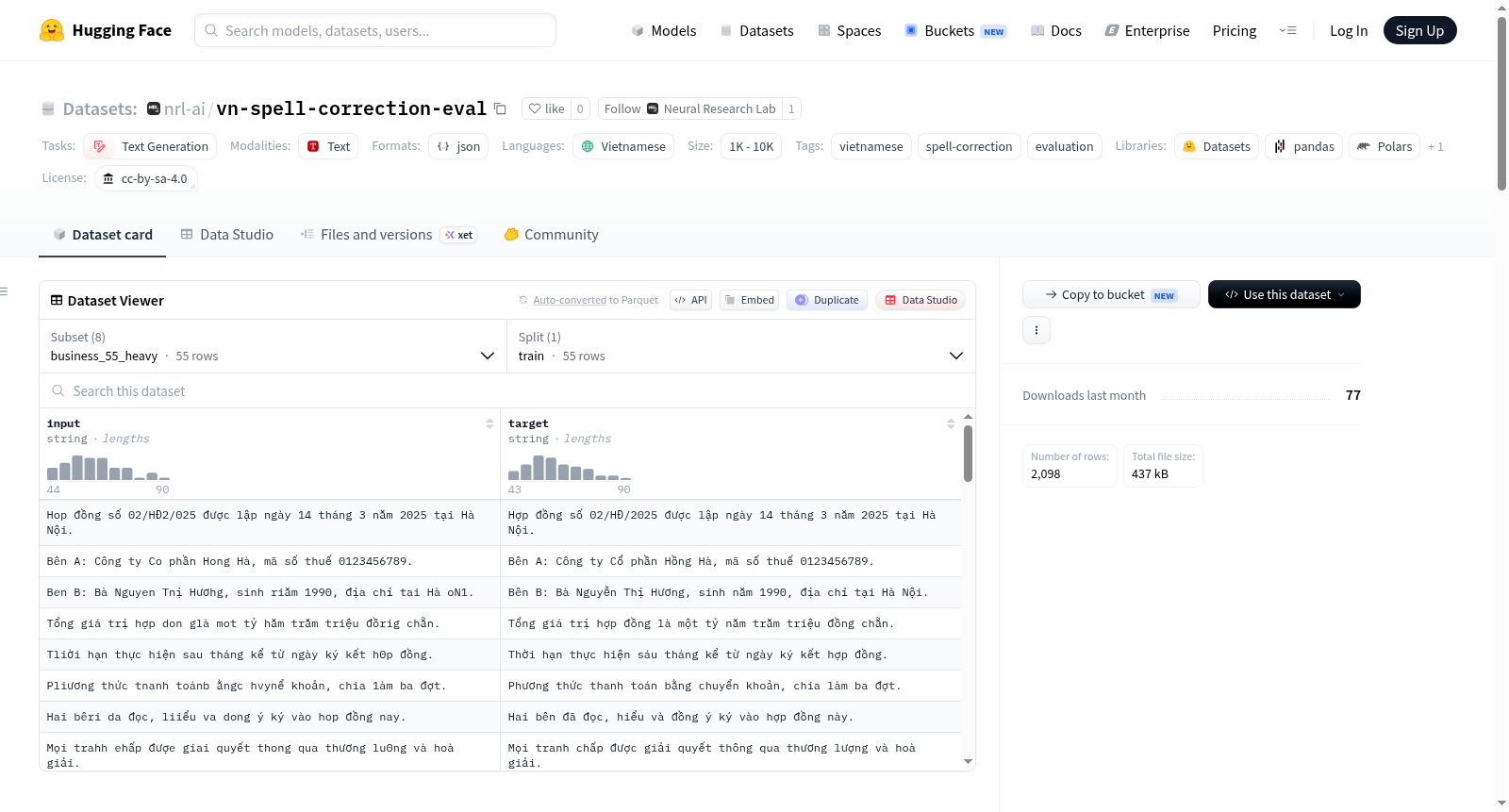
越南语拼写校正评估网格:4个来源语域 × 2种噪声级别 = 8个分割,总计2,098对(含噪声,干净)句子。每对句子格式为{input: <noisy>, target: <clean>}, 双方均经过NFC标准化处理。干净的目标句子与nrl-ai/vn-diacritic-eval数据集中的目标句子相同,因为拼写校正是重音恢复的严格超集,故复用相同的语域平衡语料库。噪声级别分为轻量级(约5%字符级编辑距离,模拟键盘输入时的少量口音错误和偶尔的误按)和重量级(约15-20%编辑距离,模拟中等质量扫描的OCR输出,含重音丢失和字符混淆)。数据集包含商业、正式、对话和文学四种语域,每种语域下分轻量和重量级噪声,具体句子数量及来源许可证详见README中的表格。数据集构建脚本位于nom-vn仓库,具有确定性(固定种子)。组合数据集采用CC-BY-SA-4.0许可证(最严格的组成源许可证),部分分割采用CC0或公共领域许可证。
Vietnamese spell-correction evaluation grid: 4 source registers × 2 noise levels = 8 splits, 2,098 (noisy, clean) sentence pairs total. Each pair is formatted as {input: <noisy>, target: <clean>}, with both sides NFC-normalized. The clean target sentences are the same as those in the nrl-ai/vn-diacritic-eval dataset, as spell correction is a strict superset of diacritic restoration, hence reusing the same registers-balanced corpus. Noise levels are categorized into light (~5% char-level edit distance, simulating a few accent slips and occasional fat-finger errors during typing) and heavy (~15-20% edit distance, modeling OCR output from mid-quality scans with diacritic drops and character confusions). The dataset covers four registers (business, formal, conversational, literary), each with light and heavy noise levels, with detailed sentence counts and source licenses provided in the README table. The dataset build script is located in the nom-vn repository and is deterministic (fixed seeds). The combined dataset is licensed under CC-BY-SA-4.0 (the most restrictive constituent source license), with some splits under CC0 or public domain licenses.
提供机构:
nrl-ai
搜集汇总
数据集介绍
构建方式
越南语拼写校正评测数据集基于四种语域(商务、正式、会话、文学)的公共语料构建,每种语域通过固定种子生成轻量(约5%编辑距离模拟键盘输入错误)与重度(约15-20%编辑距离模拟OCR噪声)两种噪声等级,最终形成八个子集共计2098对(含噪输入、干净目标)平行句对。干净目标复用自同一研究组开发的声调恢复评测数据集,确保拼写校正与声调恢复任务间的兼容性与扩展性。数据构建脚本完全可复现,采用确定性随机种子确保结果一致。
特点
该数据集的核心特色在于其多维度的评估网格设计:横跨商务合同、法律文书、日常对话和古典文学四种语域,纵贯两种噪声强度,全面覆盖越南语拼写校正的实际应用场景。轻量噪声侧重于模拟用户打字时的声调误触和按键失误,重度噪声则针对OCR场景中的字符混淆与缺失问题。每个子集均保留原始语料的版权信息,便于用户根据许可证限制灵活筛选,为模型性能的细粒度分析和鲁棒性测试提供了可靠的基准框架。
使用方法
用户可通过HuggingFace Datasets库按子集名称加载数据,每条数据包涵'input'和'target'字段,分别代表待校正句子与标准答案。推荐使用序列到序列模型进行端到端评估,加载时需对模型输出进行NFC标准化和标点归一化处理以确保公平比较。完整的评估流程包括遍历所有八个子集、生成预测、执行文本预处理后计算校正准确率,相关基准实现已集成在nom-vn工具库中供直接调用。
背景与挑战
背景概述
越南语拼写纠错是自然语言处理领域的一项重要任务,其挑战在于越南语丰富的声调系统和复杂的拼写规则,使得自动纠错尤为困难。vn-spell-correction-eval数据集由Neural Research Lab的研究人员Nguyen Viet-Anh等人于2026年创建,旨在为越南语拼写纠错模型提供一个全面、标准化的评估基准。该数据集涵盖了商务、正式、对话和文学四种语域,每种语域又细分为轻度和重度两种噪声水平,共计8个子集和2098个句对,设计精巧,兼顾了评估的多样性与严谨性。该数据集的发布填补了越南语拼写纠错评估领域的空白,为研究者提供了可重复、可比较的测试平台,对推动越南语自然语言处理技术发展具有重要影响。
当前挑战
该数据集所解决的领域挑战在于越南语拼写纠错任务本身的多源性:声调符号丢失、字符混淆、键盘误触以及OCR噪声等,均需模型具备高度鲁棒性。具体而言,轻度噪声模拟了打字时的轻微声调错误,重度噪声则模拟了OCR输出中的字符混淆(如'o'与'0'、'l'与'1'等),跨语域评估还要求模型能适应不同文本风格的拼写规范。在构建过程中,挑战主要源于噪声生成的可控性与样本均衡性:需确保不同语域和噪声水平下句子数量合理分布,同时剔除无变化噪声的冗余样本以提升评估效率。此外,数据来源涵盖多个开源语料库,需协调不同许可证的兼容性,最终以CC-BY-SA-4.0协议发布,促进了学术界的共享与复用。
常用场景
经典使用场景
在越南语自然语言处理领域,拼写纠错是一项基础而富有挑战性的任务,尤其面对不同语域和噪声环境时。vn-spell-correction-eval数据集为此精心构建了一个覆盖四种典型语域(商务、正式、对话、文学)与两种噪声强度(轻度与重度)的评测网格,共2098对噪声与干净句子配对。经典使用场景聚焦于对序列到序列模型在越南语拼写纠错任务上的标准化性能评估,研究者可在该数据集上系统性地测试模型对声调错漏、字符混淆及键盘误触等真实噪声模式的鲁棒性。该数据集为模型选择与超参数调优提供了统一的基准,使得不同架构(如基于Transformer的模型或传统统计方法)的拼写纠错能力得以公平比较。
解决学术问题
该数据集有效解决了越南语拼写纠错研究中长期存在的评测标准不统一、语域覆盖不全面等问题。学术上,它将拼写纠错明确定义为比声调恢复更严格的任务,并重用已有的声调恢复语料,为跨任务对比奠定了基础。通过引入轻度(约5%字符级编辑距离)和重度(15%-20%编辑距离)两种噪声水平,数据集模拟了从键盘输入误差到光学字符识别(OCR)输出混沌的连续频谱,从而使研究者能够量化模型在噪声敏感性上的差异。其意义在于为越南语自然语言处理社区提供了一个可复制、细粒度且语域均衡的评测工具,促进了鲁棒纠错算法的发展,并推动了对语言模型在非标准输入下泛化能力的深入理解。
衍生相关工作
该数据集的诞生催生了一系列越南语自然语言处理领域的衍生研究。一方面,它可与同源的声调恢复数据集联合使用,推动多任务学习模型的发展,实现声调校正与广义拼写纠错的协同优化。另一方面,数据集的分层噪声设计为对抗训练、数据增强策略及噪声自编码器的研究提供了理想实验床,研究者可基于其轻度和重度子集构建渐进式学习流水线。此外,该数据集的构建流程已被封装在nom-vn开源工具库中,使得后续工作能够轻松复现或扩展其评测网格至更多语域(如医疗或技术文档)。这些衍生工作共同促进了越南语文字处理生态的成熟,并为低资源语言的拼写纠错研究树立了可借鉴的范式。
以上内容由遇见数据集搜集并总结生成


