## Dataset Summary
A dataset for benchmarking keyphrase extraction and generation techniques from english news articles. For more details about the dataset please refer the original paper - [https://dl.acm.org/doi/10.5555/1620163.1620205](https://dl.acm.org/doi/10.5555/1620163.1620205)
Original source of the data - []()
## Dataset Structure
### Data Fields
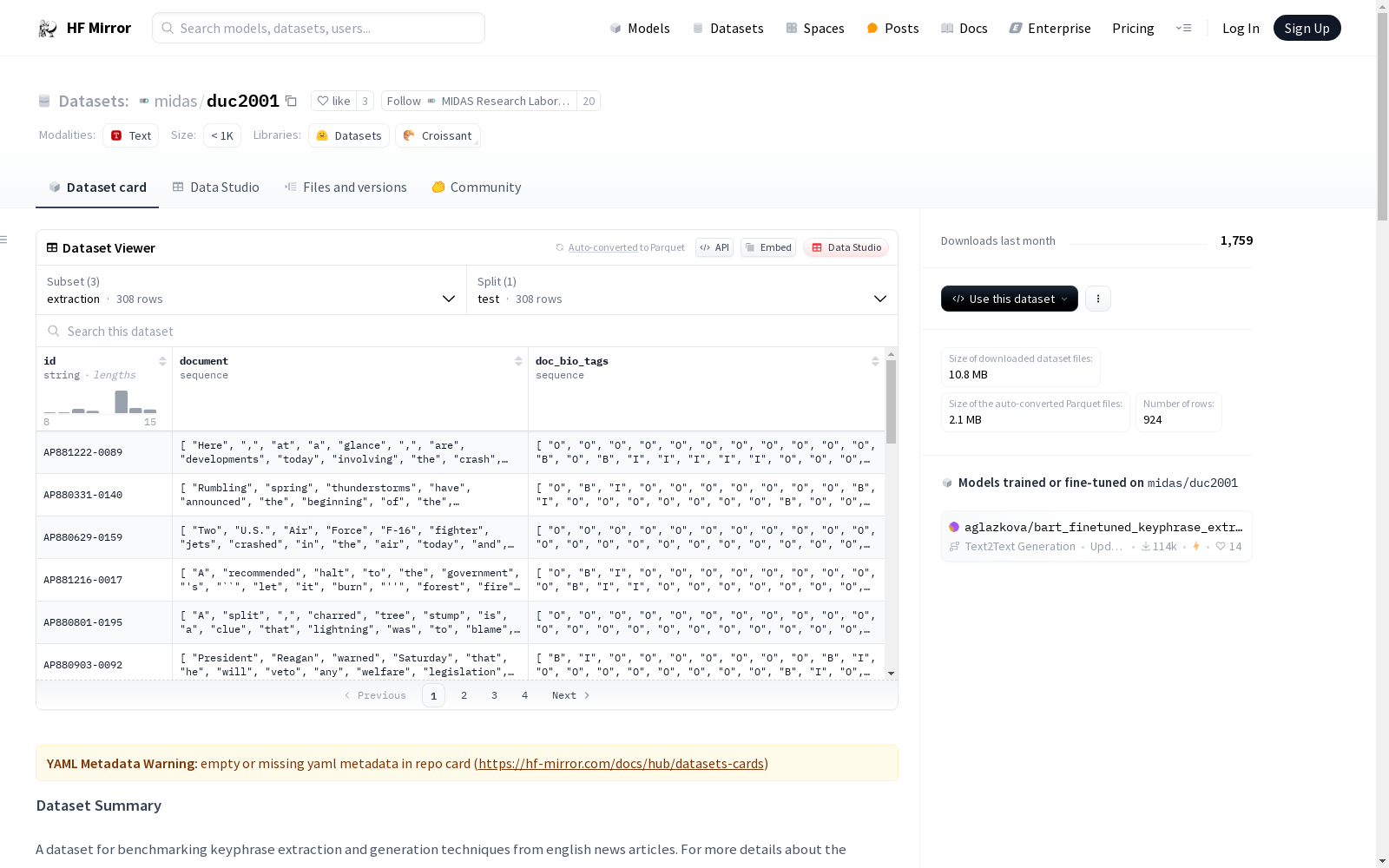
- **id**: unique identifier of the document.
- **document**: Whitespace separated list of words in the document.
- **doc_bio_tags**: BIO tags for each word in the document. B stands for the beginning of a keyphrase and I stands for inside the keyphrase. O stands for outside the keyphrase and represents the word that isn't a part of the keyphrase at all.
- **extractive_keyphrases**: List of all the present keyphrases.
- **abstractive_keyphrase**: List of all the absent keyphrases.
### Data Splits
|Split| #datapoints |
|--|--|
| Test | 308 |
## Usage
### Full Dataset
```python
from datasets import load_dataset
# get entire dataset
dataset = load_dataset("midas/duc2001", "raw")
# sample from the test split
print("Sample from test dataset split")
test_sample = dataset["test"][0]
print("Fields in the sample: ", [key for key in test_sample.keys()])
print("Tokenized Document: ", test_sample["document"])
print("Document BIO Tags: ", test_sample["doc_bio_tags"])
print("Extractive/present Keyphrases: ", test_sample["extractive_keyphrases"])
print("Abstractive/absent Keyphrases: ", test_sample["abstractive_keyphrases"])
print("\n-----------\n")
```
**Output**
```bash
Sample from test data split
Fields in the sample: ['id', 'document', 'doc_bio_tags', 'extractive_keyphrases', 'abstractive_keyphrases', 'other_metadata']
Tokenized Document: ['Here', ',', 'at', 'a', 'glance', ',', 'are', 'developments', 'today', 'involving', 'the', 'crash', 'of', 'Pan', 'American', 'World', 'Airways', 'Flight', '103', 'Wednesday', 'night', 'in', 'Lockerbie', ',', 'Scotland', ',', 'that', 'killed', 'all', '259', 'people', 'aboard', 'and', 'more', 'than', '20', 'people', 'on', 'the', 'ground', ':']
Document BIO Tags: ['O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B', 'O', 'B', 'I', 'I', 'I', 'I', 'I', 'O', 'O', 'O', 'B', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
Extractive/present Keyphrases: ['pan american world airways flight 103', 'crash', 'lockerbie']
Abstractive/absent Keyphrases: ['terrorist threats', 'widespread wreckage', 'radical palestinian faction', 'terrorist bombing', 'bomb threat', 'sabotage']
-----------
```
### Keyphrase Extraction
```python
from datasets import load_dataset
# get the dataset only for keyphrase extraction
dataset = load_dataset("midas/duc2001", "extraction")
print("Samples for Keyphrase Extraction")
# sample from the test split
print("Sample from test data split")
test_sample = dataset["test"][0]
print("Fields in the sample: ", [key for key in test_sample.keys()])
print("Tokenized Document: ", test_sample["document"])
print("Document BIO Tags: ", test_sample["doc_bio_tags"])
print("\n-----------\n")
```
### Keyphrase Generation
```python
# get the dataset only for keyphrase generation
dataset = load_dataset("midas/duc2001", "generation")
print("Samples for Keyphrase Generation")
# sample from the test split
print("Sample from test data split")
test_sample = dataset["test"][0]
print("Fields in the sample: ", [key for key in test_sample.keys()])
print("Tokenized Document: ", test_sample["document"])
print("Extractive/present Keyphrases: ", test_sample["extractive_keyphrases"])
print("Abstractive/absent Keyphrases: ", test_sample["abstractive_keyphrases"])
print("\n-----------\n")
```
## Citation Information
```
@inproceedings{10.5555/1620163.1620205,
author = {Wan, Xiaojun and Xiao, Jianguo},
title = {Single Document Keyphrase Extraction Using Neighborhood Knowledge},
year = {2008},
isbn = {9781577353683},
publisher = {AAAI Press},
booktitle = {Proceedings of the 23rd National Conference on Artificial Intelligence - Volume 2},
pages = {855–860},
numpages = {6},
location = {Chicago, Illinois},
series = {AAAI'08}
}
```
## Contributions
Thanks to [@debanjanbhucs](https://github.com/debanjanbhucs), [@dibyaaaaax](https://github.com/dibyaaaaax) and [@ad6398](https://github.com/ad6398) for adding this dataset
## 数据集概述
本数据集用于基准测试来自英文新闻文章的关键词短语(keyphrase)抽取与生成技术。如需了解该数据集的更多细节,请参阅原始论文:[https://dl.acm.org/doi/10.5555/1620163.1620205](https://dl.acm.org/doi/10.5555/1620163.1620205)
数据集的原始来源:[]()
## 数据集结构
### 数据字段
- **id**:文档的唯一标识符。
- **document**:文档中以空格分隔的单词列表。
- **doc_bio_tags**:文档中每个单词对应的BIO标签(BIO tags)。其中B代表关键词短语(keyphrase)的起始位置,I代表关键词短语的内部位置,O代表非关键词短语位置,即该单词完全不属于任何关键词短语。
- **extractive_keyphrases**:所有存在于原文中的关键词短语列表。
- **abstractive_keyphrases**:所有未出现在原文中的关键词短语列表。
### 数据拆分
|拆分|数据点数量|
|--|--|
| 测试集 | 308 |
## 使用方法
### 完整数据集
python
from datasets import load_dataset
# 获取完整数据集
dataset = load_dataset("midas/duc2001", "raw")
# 从测试拆分中采样示例
print("测试数据集拆分采样示例")
test_sample = dataset["test"][0]
print("样本包含的字段:", [key for key in test_sample.keys()])
print("分词后的文档:", test_sample["document"])
print("文档BIO标签:", test_sample["doc_bio_tags"])
print("抽取式/存在的关键词短语:", test_sample["extractive_keyphrases"])
print("生成式/缺失的关键词短语:", test_sample["abstractive_keyphrases"])
print("
-----------
")
**输出**
bash
测试数据集拆分采样示例
样本包含的字段: ['id', 'document', 'doc_bio_tags', 'extractive_keyphrases', 'abstractive_keyphrases', 'other_metadata']
分词后的文档: ['Here', ',', 'at', 'a', 'glance', ',', 'are', 'developments', 'today', 'involving', 'the', 'crash', 'of', 'Pan', 'American', 'World', 'Airways', 'Flight', '103', 'Wednesday', 'night', 'in', 'Lockerbie', ',', 'Scotland', ',', 'that', 'killed', 'all', '259', 'people', 'aboard', 'and', 'more', 'than', '20', 'people', 'on', 'the', 'ground', ':']
文档BIO标签: ['O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B', 'O', 'B', 'I', 'I', 'I', 'I', 'I', 'O', 'O', 'O', 'B', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
抽取式/存在的关键词短语: ['pan american world airways flight 103', 'crash', 'lockerbie']
生成式/缺失的关键词短语: ['terrorist threats', 'widespread wreckage', 'radical palestinian faction', 'terrorist bombing', 'bomb threat', 'sabotage']
-----------
### 关键词短语抽取
python
from datasets import load_dataset
# 仅加载用于关键词短语抽取任务的数据集
dataset = load_dataset("midas/duc2001", "extraction")
print("关键词短语抽取任务示例")
# 从测试拆分中采样示例
print("测试数据集拆分采样示例")
test_sample = dataset["test"][0]
print("样本包含的字段:", [key for key in test_sample.keys()])
print("分词后的文档:", test_sample["document"])
print("文档BIO标签:", test_sample["doc_bio_tags"])
print("
-----------
")
### 关键词短语生成
python
# 仅加载用于关键词短语生成任务的数据集
dataset = load_dataset("midas/duc2001", "generation")
print("关键词短语生成任务示例")
# 从测试拆分中采样示例
print("测试数据集拆分采样示例")
test_sample = dataset["test"][0]
print("样本包含的字段:", [key for key in test_sample.keys()])
print("分词后的文档:", test_sample["document"])
print("抽取式/存在的关键词短语:", test_sample["extractive_keyphrases"])
print("生成式/缺失的关键词短语:", test_sample["abstractive_keyphrases"])
print("
-----------
")
## 引用信息
@inproceedings{10.5555/1620163.1620205,
author = {Wan, Xiaojun and Xiao, Jianguo},
title = {Single Document Keyphrase Extraction Using Neighborhood Knowledge},
year = {2008},
isbn = {9781577353683},
publisher = {AAAI Press},
booktitle = {Proceedings of the 23rd National Conference on Artificial Intelligence - Volume 2},
pages = {855–860},
numpages = {6},
location = {Chicago, Illinois},
series = {AAAI'08}
}
## 贡献
感谢 [@debanjanbhucs](https://github.com/debanjanbhucs)、[@dibyaaaaax](https://github.com/dibyaaaaax) 与 [@ad6398](https://github.com/ad6398) 贡献本数据集