nocola
收藏Hugging Face2026-02-04 更新2026-02-05 收录
下载链接:
https://huggingface.co/datasets/ltg/nocola
下载链接
链接失效反馈官方服务:
资源简介:
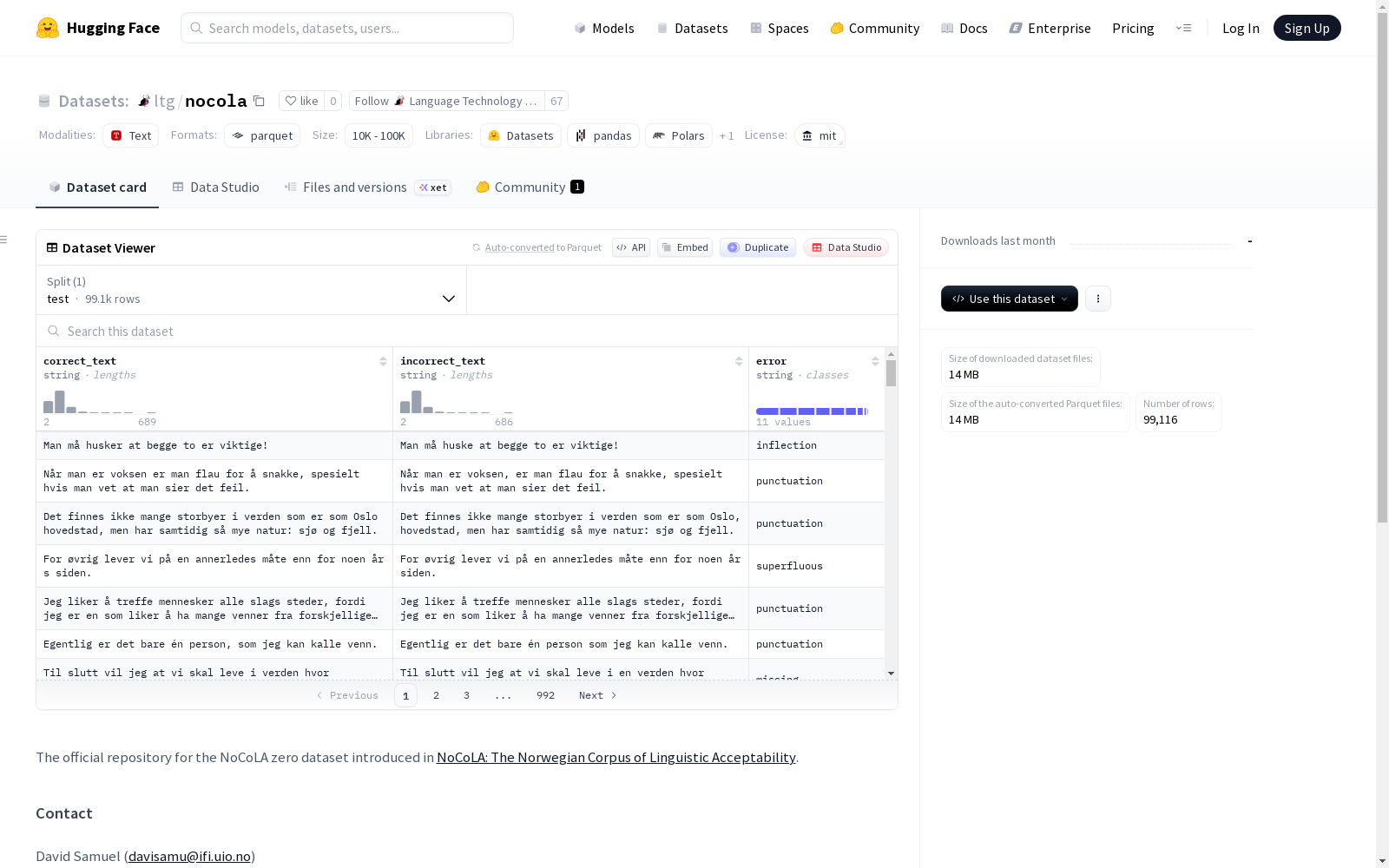
NoCoLA zero 数据集是一个挪威语语言可接受性语料库,旨在用于语言学研究。该数据集包含三个主要字段:correct_text(正确文本)、incorrect_text(错误文本)和error(错误类型)。数据集仅包含测试集(test split),共有99,116个样本,总大小为23,464,301字节,下载大小为13,964,902字节。该数据集适用于语言可接受性判断、语法错误检测等自然语言处理任务。数据集的相关研究发表在2023年北欧计算语言学会议(NoDaLiDa)上。
创建时间:
2026-02-04
原始信息汇总
NoCoLA 零样本数据集概述
数据集基本信息
- 数据集名称:NoCoLA 零样本数据集
- 发布机构:官方存储库
- 许可证:MIT
- 下载大小:13,964,902 字节
- 数据集大小:23,464,301 字节
数据集结构
特征
- correct_text:字符串类型,表示正确的文本。
- incorrect_text:字符串类型,表示不正确的文本。
- error:字符串类型,表示错误类型。
数据划分
- 测试集:包含 99,116 个样本,大小为 23,464,301 字节。
来源与引用
引入论文
- 论文标题:NoCoLA: The Norwegian Corpus of Linguistic Acceptability
- 论文地址:https://aclanthology.org/2023.nodalida-1.60/
- 会议信息:Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa),2023年5月,法罗群岛托尔斯港,由塔尔图大学图书馆出版。
引用格式
bibtex @inproceedings{jentoft-samuel-2023-nocola, title = "{N}o{C}o{LA}: The {N}orwegian Corpus of Linguistic Acceptability", author = "Jentoft, Matias and Samuel, David", editor = {Alum{"a}e, Tanel and Fishel, Mark}, booktitle = "Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa)", month = may, year = "2023", address = "T{o}rshavn, Faroe Islands", publisher = "University of Tartu Library", url = "https://aclanthology.org/2023.nodalida-1.60/", pages = "610--617", }
联系方式
- 联系人:David Samuel
- 邮箱:davisamu@ifi.uio.no
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,语言可接受性评估是衡量模型理解语言规范的关键任务。NoCoLA数据集的构建基于挪威语的语言学理论,通过系统性地收集和标注挪威语句子,形成了一套标准化的可接受性判断语料。该数据集包含正确文本、错误文本及对应的错误类型标注,其构建过程严格遵循语言学准则,确保了语料在语法、句法和语义层面的准确性与一致性,为挪威语的语言模型评估提供了可靠的基础资源。
特点
NoCoLA数据集以其高质量的标注和丰富的错误类型而著称,涵盖了挪威语中常见的语法和句法错误,为语言可接受性任务提供了细致的分析维度。数据集规模适中,包含近十万个例句,每个例句均配有明确的正确与错误版本,以及具体的错误描述,这使得它能够支持精细化的模型训练与评估。此外,其基于MIT许可证开放,促进了学术研究和工业应用的广泛使用,体现了数据共享的科学精神。
使用方法
使用NoCoLA数据集时,研究人员可将其应用于挪威语的语言可接受性分类任务,通过对比正确与错误文本,训练模型识别语言规范。数据集通常用于测试模型的零样本或小样本学习能力,用户可直接从HuggingFace平台下载测试集,并依据提供的特征进行模型评估。在实践过程中,建议结合相关论文中的基准方法,以确保评估的严谨性,从而推动挪威语自然语言处理技术的发展。
背景与挑战
背景概述
在计算语言学领域,语言可接受性评估是衡量语言模型对语法、句法及语义规则掌握程度的关键任务。NoCoLA数据集于2023年由挪威奥斯陆大学的研究人员Matias Jentoft和David Samuel构建并发布,作为挪威语的首个大规模语言可接受性语料库,其核心研究问题聚焦于评估模型对挪威语语法正确性的判别能力。该数据集的推出填补了北欧语言在可接受性评估资源上的空白,为挪威语自然语言处理研究提供了重要的基准工具,促进了跨语言模型泛化性能的深入探索。
当前挑战
NoCoLA数据集旨在解决挪威语语言可接受性分类的挑战,即模型需准确区分语法正确与错误的句子,这对理解语言的细微语法规则提出了较高要求。在构建过程中,研究人员面临数据收集与标注的困难,挪威语方言变体丰富且语法结构复杂,确保标注一致性与语言覆盖度成为关键难题。此外,作为零样本评估数据集,其设计需避免与训练数据重叠,以公正测试模型在未见数据上的泛化能力,这增加了数据筛选与平衡的复杂性。
常用场景
经典使用场景
在自然语言处理领域,NoCoLA数据集专为挪威语的语言可接受性评估而设计,其经典使用场景集中于语法错误检测与语言模型微调。研究者利用该数据集中的正确与错误文本对,训练模型以区分符合语法规范的表达与存在错误的句子,从而提升模型对挪威语语法结构的理解能力。这一过程不仅涉及句法分析,还涵盖语义一致性判断,为挪威语的语言技术开发提供了关键基准。
实际应用
在实际应用层面,NoCoLA数据集可直接服务于挪威语的教育技术工具,如自动语法检查器与写作辅助系统,帮助学习者识别并纠正语言错误。同时,该数据集为挪威语内容审核与文本质量评估提供了技术基础,适用于新闻媒体、出版业及社交媒体平台,确保文本内容的语言规范性。这些应用不仅提升了挪威语使用者的沟通效率,也增强了数字化环境中语言资源的可访问性与可靠性。
衍生相关工作
基于NoCoLA数据集,研究者已开展多项经典工作,包括开发针对挪威语的预训练语言模型微调策略,以及跨语言可接受性检测模型的迁移学习研究。这些工作扩展了数据集的适用范围,促进了挪威语与其他语言在语法错误检测任务上的比较分析。此外,该数据集还激发了关于低资源语言语法标注方法的新探索,为多语言自然语言处理社区的协作与创新提供了重要参考。
以上内容由遇见数据集搜集并总结生成


