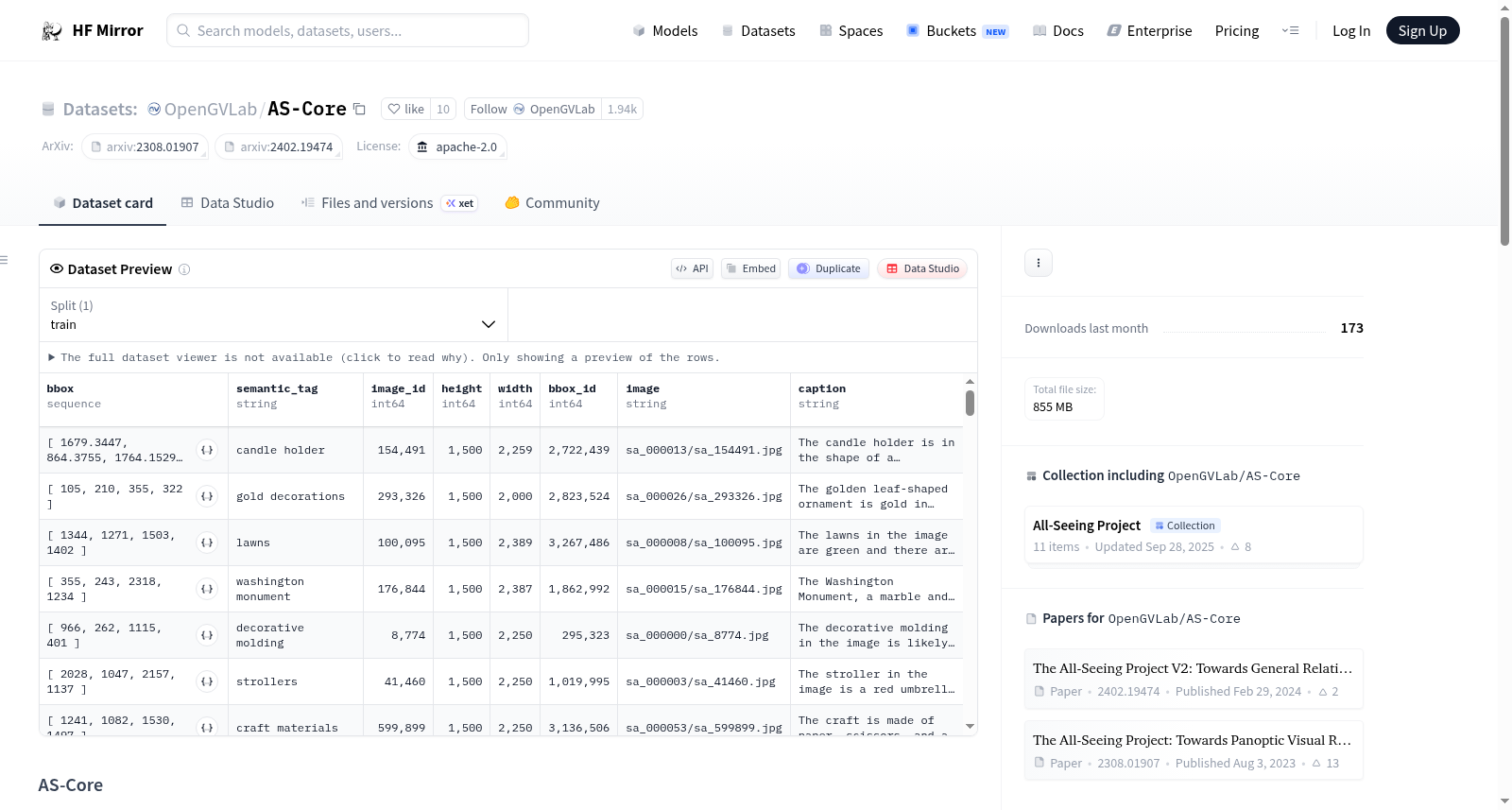
资源简介:
---
license: apache-2.0
---
# AS-Core
AS-Core is the human-verified subset of AS-1B.
- `semantic_tag_1m.json`: the human verified annotations for semantic tags.
- `region_vqa_1m.jsonl`: the human verified annotations for region VQA.
- `region_caption_400k.jsonl`: the region captions generated base on paraphrasing the region question-answer pairs.
***NOTE***: The bbox format is `x1y1x2y2`.
## Introduction
We present the All-Seeing Project with:
[***All-Seeing 1B (AS-1B) dataset***](https://huggingface.co/datasets/Weiyun1025/AS-100M): we propose a new large-scale dataset (AS-1B) for open-world panoptic visual recognition and understanding, using an economical semi-automatic data engine that combines the power of off-the-shelf vision/language models and human feedback.
[***All-Seeing Model (ASM)***](https://huggingface.co/Weiyun1025/All-Seeing-Model-FT): we develop a unified vision-language foundation model (ASM) for open-world panoptic visual recognition and understanding. Aligning with LLMs, our ASM supports versatile image-text retrieval and generation tasks, demonstrating impressive zero-shot capability.
<img width="820" alt="image" src="https://github.com/OpenGVLab/all-seeing/assets/8529570/e43ab8db-6437-46f1-8aa1-c95f012e9147">
Figure 1: Overview and comparison of our All-Seeing project with other popular large foundation models.
<!-- ## Online Demo
**All-Seeing Model demo** is available [here](https://openxlab.org.cn/apps/detail/wangweiyun/All-Seeing-Model-Demo).
**Dataset Browser** is available [here](https://openxlab.org.cn/apps/detail/wangweiyun/All-Seeing-Dataset-Browser).
https://github.com/OpenGVLab/all-seeing/assets/47669167/9b5b32d1-863a-4579-b576-b82523f2205e -->
## Dataset Overview
AS-1B with over 1 billion regions annotated with semantic tags, question-answering pairs, and detailed captions. It covers a wide range of 3.5 million common and rare concepts in the real world, and has 132.2 billion tokens that describe the concepts and their attributes.
<img width="800" alt="image" src="https://github.com/OpenGVLab/all-seeing/assets/8529570/adac37ed-312f-4f11-ba8a-6bc62067438f">
Some examples
<img width="800" alt="image" src="https://github.com/OpenGVLab/all-seeing/assets/8529570/fcf6ab07-c4ba-441c-aa6c-111c769f75b1">
Please see our [paper](https://arxiv.org/abs/2308.01907) to learn more details.
## Model Architecture
The All-Seeing model (ASM) is a unified framework for panoptic visual recognition and understanding, including image/region-text retrieval, image/region recognition, captioning, and question-answering.
<img width="820" alt="image" src="https://github.com/OpenGVLab/all-seeing/assets/8529570/8995e88c-6381-452f-91e4-05d68a2795fc">
## License
This project is released under the [Apache 2.0 license](LICENSE).
# Citation
If you find our work useful in your research, please consider cite:
```BibTeX
@article{wang2023allseeing,
title={The All-Seeing Project: Towards Panoptic Visual Recognition and Understanding of the Open World},
author={Wang, Weiyun and Shi, Min and Li, Qingyun and Wang, Wenhai and Huang, Zhenhang and Xing, Linjie and Chen, Zhe and Li, Hao and Zhu, Xizhou and Cao, Zhiguo and others},
journal={arXiv preprint arXiv:2308.01907},
year={2023}
}
@article{wang2024allseeing_v2,
title={The All-Seeing Project V2: Towards General Relation Comprehension of the Open World},
author={Wang, Weiyun and Ren, Yiming and Luo, Haowen and Li, Tiantong and Yan, Chenxiang and Chen, Zhe and Wang, Wenhai and Li, Qingyun and Lu, Lewei and Zhu, Xizhou and others},
journal={arXiv preprint arXiv:2402.19474},
year={2024}
}
```