L3Cube-MahaSTS
收藏arXiv2025-08-29 更新2025-09-03 收录
下载链接:
https://huggingface.co/datasets/l3cube-pune/MahaSTS
下载链接
链接失效反馈官方服务:
资源简介:
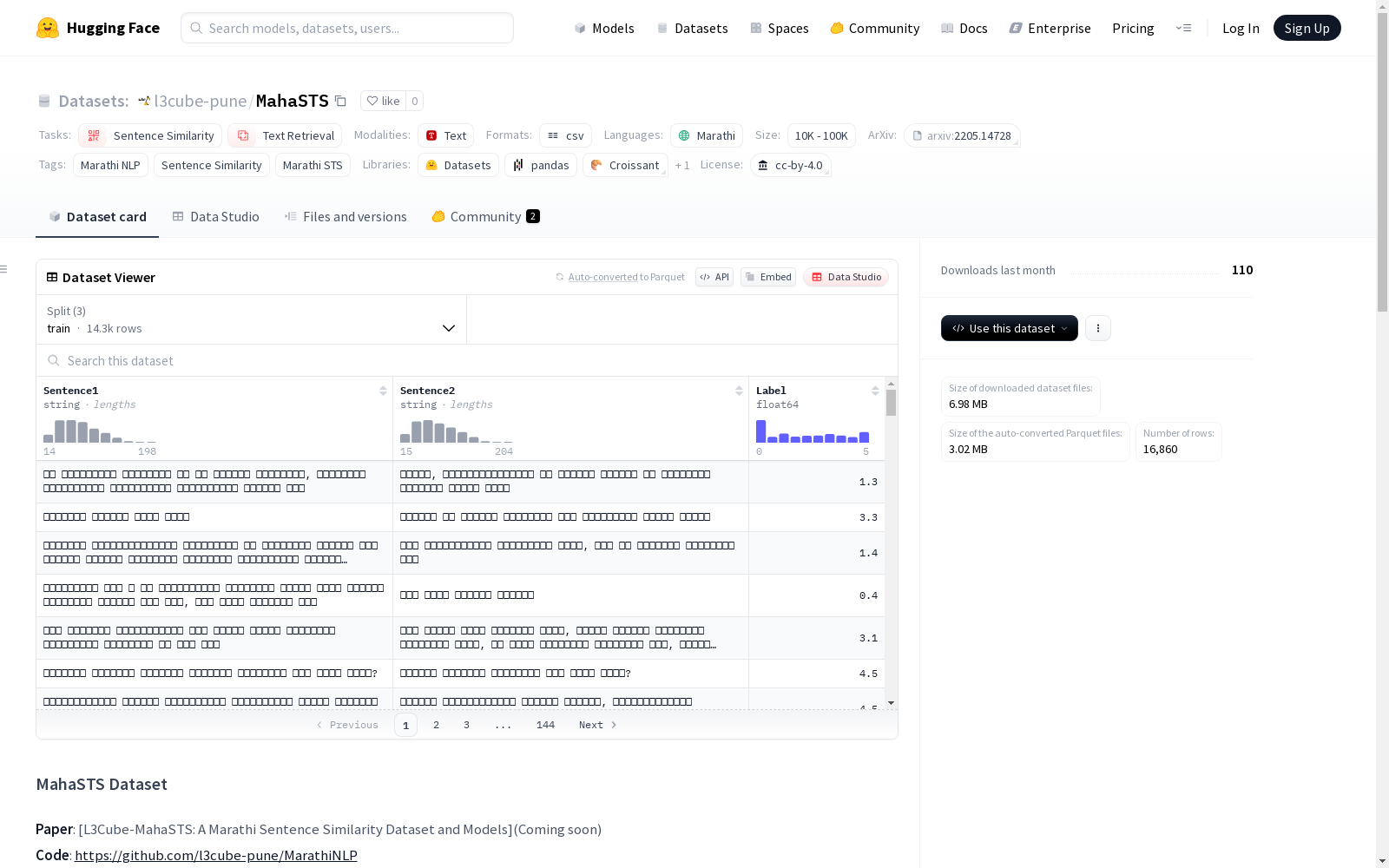
L3Cube-MahaSTS是一个人类标注的马拉地语句子文本相似度数据集,包含16,860个马拉地语句对,每个语句对都被标注了0到5之间的连续相似度分数。数据集被均匀地分布在六个基于分数的桶中,以确保监督平衡并减少标签偏差。该数据集旨在支持马拉地语中细粒度语义相似度建模,并促进低资源环境中模型训练的稳定性和泛化能力。
提供机构:
印度理工学院马德拉斯分校,印度
创建时间:
2025-08-29
原始信息汇总
MahaSTS 数据集概述
基本信息
- 许可证: CC-BY-4.0
- 任务类别: 句子相似性、文本检索
- 语言: 马拉地语
- 标签: 马拉地语自然语言处理、句子相似性、马拉地语STS
- 数据集名称: MahaSTS
- 规模分类: 10K<n<100K
数据集详情
- 论文: L3Cube-MahaSTS: A Marathi Sentence Similarity Dataset and Models(即将发布)
- 代码库: https://github.com/l3cube-pune/MarathiNLP
- 概述: MahaSTS数据集是一个人工标注的马拉地语句子文本相似性(STS)数据集,用于训练和评估句子相似性任务模型。包含16,860个马拉地语句子对,每个句子对标注有0-5范围内的连续相似性分数。数据集按85:10:5的比例划分为训练集、验证集和测试集,确保平衡监督。
语言信息
- 主要语言: 马拉地语(低资源印度语言)
数据规模
- 总句子对数量: 16,860
- 训练集: 14,328个句子对
- 验证集: 840个句子对
- 测试集: 1,692个句子对
- 分布情况:
- 6个相似性分桶(0-5)
- 每个分桶2,810个句子对
标注信息
每个句子对标注有0到5范围内的连续相似性分数。标签表示两个句子之间的相似程度,0表示无相似性,5表示高度相似。
用途
- 句子相似性
- 回归任务
- 句子嵌入
- 马拉地语嵌入模型基准测试
模型基准
基于该数据集微调的MahaSBERT-STS-v2模型提供了性能基线。其他可进行比较基准测试的模型包括MahaBERT、MuRIL、IndicBERT和IndicSBERT。
引用
bibtex @article{joshi2022l3cube, title={L3cube-mahanlp: Marathi natural language processing datasets, models, and library}, author={Joshi, Raviraj}, journal={arXiv preprint arXiv:2205.14728}, year={2022} }
搜集汇总
数据集介绍
构建方式
在构建L3Cube-MahaSTS数据集的过程中,研究团队从L3Cube-MahaCorpus中筛选出100万条真实马拉提语句子,经过预处理去除短句、长句、非马拉提语内容及重复项后,采用MahaSBERT-STS模型生成句子嵌入并计算余弦相似度。通过将相似度分数划分为五个区间桶,并为每个查询句子从各桶中选取一个相似句对,最终通过人工标注调整并补充第六个完全不相关桶,确保数据质量的精确性和语义丰富性。
使用方法
数据集按85:10:5的比例划分为训练集、测试集和验证集,适用于回归式句子相似度模型的训练与评估。使用者可基于该数据对预训练模型(如MahaSBERT)进行微调,采用余弦相似度损失函数和均值池化策略优化性能。评估时通过皮尔逊和斯皮尔曼相关系数衡量模型预测与人工标注的一致性,适用于信息检索、问答系统及文本复述检测等自然语言处理任务。
背景与挑战
背景概述
自然语言处理领域长期面临低资源语言语义理解的技术瓶颈,马拉地语作为印度主要语言之一,其语义文本相似度研究因缺乏高质量标注数据而进展缓慢。2025年由L3Cube实验室联合浦那计算机技术研究所等机构发布的L3Cube-MahaSTS数据集,首次构建了包含16,860对人工标注句子的语义相似度基准,采用0-5分连续评分体系,并通过六等分均匀分布设计有效降低了标签偏差。该数据集为马拉地语语义理解模型提供了关键训练资源,显著推动了印度语言自然语言处理技术的发展。
当前挑战
该数据集主要解决马拉地语句义相似度计算中的语义深层理解挑战,包括方言表达差异、文化特定语境解读以及低资源语言缺乏标注数据等问题。构建过程中面临双重挑战:一是需要从百万级语料中筛选符合长度与语言纯净度要求的句子对,并保持六档相似度的精确平衡分布;二是人工标注需克服机器翻译数据缺乏文化适配性的局限,确保本土语言学家能准确捕捉细微语义差异,同时维护标注一致性与质量控制体系。
常用场景
经典使用场景
在自然语言处理领域,L3Cube-MahaSTS数据集为马拉地语的语义文本相似度任务提供了重要基准。该数据集通过人工标注的16,860个句子对,覆盖了0-5分的连续相似度评分范围,为训练和评估句子嵌入模型提供了标准化测试平台。研究者利用该数据集优化句子编码器的语义表示能力,特别是在低资源语言环境下验证模型对深层语义关系的捕捉效果。
解决学术问题
该数据集有效解决了低资源语言缺乏高质量标注数据的核心学术问题,为马拉地语语义相似度研究提供了首个人类标注的基准资源。通过均匀分布的六个分数桶设计,缓解了训练过程中的标签偏差问题,支持回归模型的稳定训练。其结构化标注体系为研究跨语言语义表示迁移、少样本学习以及文化语言特异性对语义理解的影响提供了重要实验基础。
实际应用
在实际应用层面,该数据集支撑了马拉地语信息检索系统的语义匹配优化,显著提升了检索相关性和准确性。在智能客服系统中,基于该数据集训练的模型能够更精准地识别用户查询与知识库条目的语义关联。此外,在教育科技领域,该资源为开发自动作文评分、剽窃检测等应用提供了核心技术支撑,同时促进了跨语言RAG系统在印度本土语言中的落地应用。
数据集最近研究
最新研究方向
在低资源语言处理领域,L3Cube-MahaSTS数据集的推出显著推动了马拉提语句义相似性研究的前沿进展。该数据集通过人工标注的16,860个句子对,构建了均匀分布的六档相似度分级体系,为训练回归模型提供了平衡的监督信号。当前研究聚焦于优化句子嵌入模型MahaSBERT-STS-v2,其在Pearson相关系数上达到0.9600的突破性表现,超越了多语言基线模型如MuRIL和IndicBERT。这一进展与印度本土语言技术热潮相呼应,特别是在跨语言检索增强生成(RAG)和语义检索任务中,为消除机器翻译数据的文化失真问题提供了本土化解决方案。该数据集不仅填补了印度语言语义评估资源的空白,更成为推动低资源语言模型公平性评估和实际应用部署的关键基础设施。
相关研究论文
- 1L3Cube-MahaSTS: A Marathi Sentence Similarity Dataset and Models印度理工学院马德拉斯分校,印度 · 2025年
以上内容由遇见数据集搜集并总结生成


