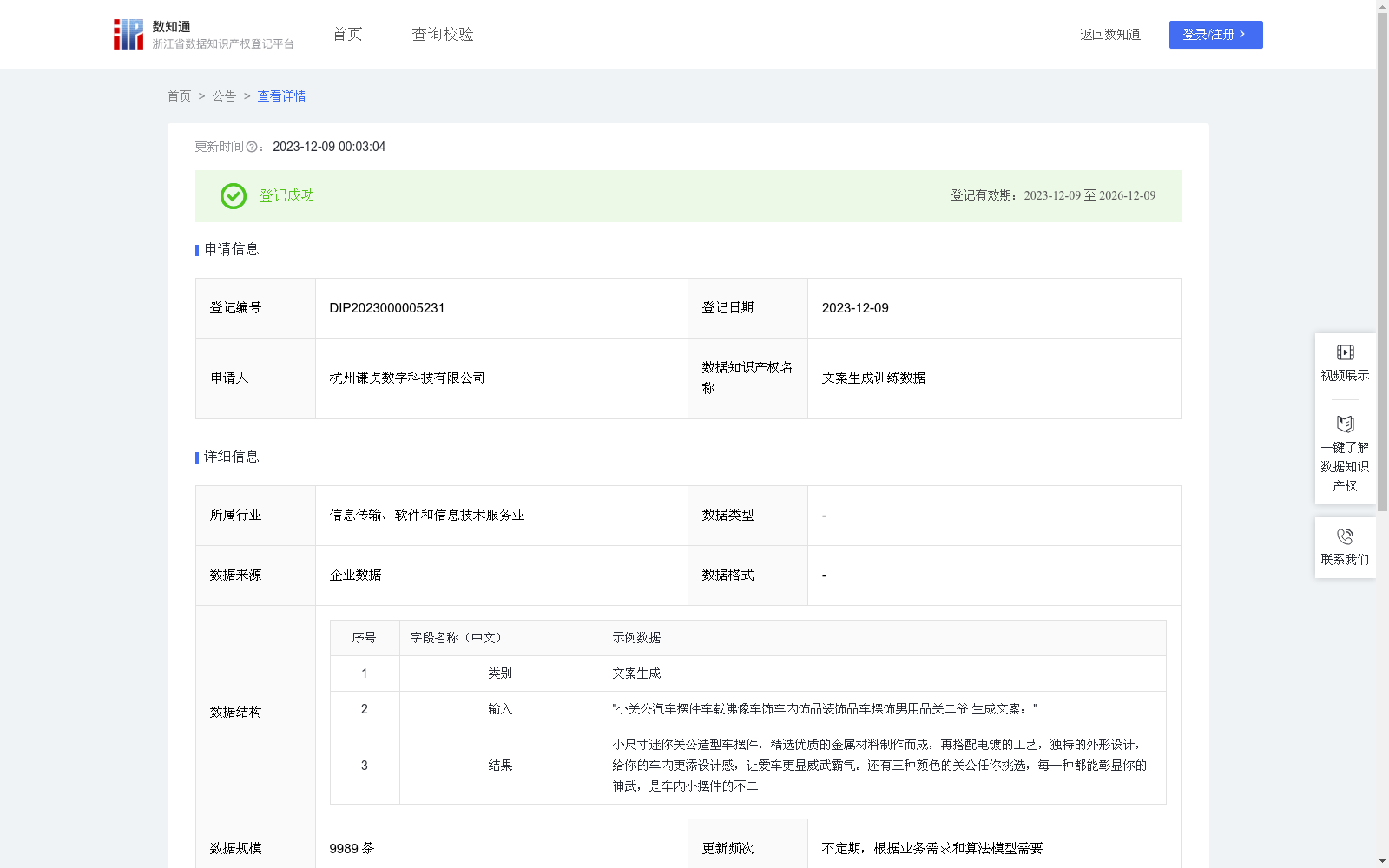
文案生成训练数据
收藏浙江省数据知识产权登记平台2023-12-09 更新2024-05-08 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/17976
下载链接
链接失效反馈官方服务:
资源简介:
应用场景
适用条件与范围
营销与广告:自动生成针对特定受众的创意文案,适用于社交媒体、邮件营销、网站内容等。
内容创作:协助内容创作者和博客作者生成文章、故事、博客帖子等。
产品描述:在电子商务平台上,用于生成吸引人的产品描述。
新闻报道:辅助新闻编辑快速撰写标准新闻报导。
教育与培训:为教育材料或在线课程生成创意和教育性内容。
对象
企业与品牌:帮助企业在各种媒介上创建有吸引力的内容。
内容创作者:辅助个人或团队快速产生高质量的写作内容。
教育工作者:为教育专业人士提供工具,生成教学材料或课程内容。
禁用场景
伪造和误导性内容:不得用于生成虚假新闻、误导性广告或任何形式的欺诈内容。
侵权内容:不得用于生成侵犯版权、商标或其他知识产权的内容。
敏感或不当内容:不得用于生成令人反感、歧视性、挑衅性或其他不适当的内容。
法律和伦理限制:在生成内容时必须遵守适用的法律法规和伦理标准。文案生成任务的核心是利用自然语言处理(NLP)技术,特别是机器学习和深度学习方法,来自动产生有吸引力、有意义且通常是针对特定目的或受众的文本内容。以下是文案生成任务算法规则的简要说明:
1. 数据预处理
文本清洗:去除无关数据,如重复内容、错误信息等。
标准化:统一文本格式,确保数据一致性。
2. 语言模型
基于统计的模型:使用统计方法从大量文本数据中学习语言规律。
基于神经网络的模型:如循环神经网络(RNN)和变压器(Transformer)模型,更适用于理解和生成复杂语言结构。
3. 上下文理解
关键词识别:识别与主题相关的关键词和短语。
意图理解:根据使用场景和目标受众理解文案的目的。
4. 内容生成
文案撰写:基于预训练模型和特定输入生成文案。
风格适配:调整生成内容的风格以符合特定品牌或受众特征。
5. 后处理和优化
质量控制:通过自动或人工审查确保文案的质量。
个性化调整:根据反馈和用户需求调整生成策略。
6. 评估与反馈
性能评估:监测生成文案的效果,如吸引力、相关性等。
持续学习:利用反馈和新数据不断优化模型。
Application Scenarios
Applicable Conditions and Scope
Marketing and Advertising: Automatically generate creative copy for specific audiences, applicable to social media, email marketing, website content, etc.
Content Creation: Assist content creators and bloggers in generating articles, stories, blog posts, etc.
Product Descriptions: Generate engaging product descriptions on e-commerce platforms.
News Reporting: Assist news editors in quickly drafting standard news reports.
Education and Training: Generate creative and educational content for teaching materials or online courses.
Target Users
Enterprises and Brands: Help enterprises create engaging content across various media.
Content Creators: Assist individuals or teams in quickly producing high-quality written content.
Educators: Provide tools for education professionals to generate teaching materials or course content.
Prohibited Scenarios
Forged and Misleading Content: Prohibited from generating fake news, misleading advertisements, or any form of fraudulent content.
Infringing Content: Prohibited from generating content that infringes copyrights, trademarks, or other intellectual property rights.
Sensitive or Inappropriate Content: Prohibited from generating offensive, discriminatory, provocative, or other inappropriate content.
Legal and Ethical Restrictions: Must comply with applicable laws, regulations and ethical standards when generating content.
The core of copy generation tasks is to use natural language processing (NLP) technologies, especially machine learning and deep learning methods, to automatically generate engaging, meaningful textual content that is usually tailored for specific purposes or audiences. The following is a brief explanation of the algorithmic rules for copy generation tasks:
1. Data Preprocessing
Text Cleaning: Remove irrelevant data such as duplicate content, erroneous information, etc.
Standardization: Unify text formats to ensure data consistency.
2. Language Models
Statistical-based Models: Use statistical methods to learn language patterns from large volumes of text data.
Neural Network-based Models: Such as Recurrent Neural Networks (RNN) and Transformer models, which are more suitable for understanding and generating complex language structures.
3. Context Understanding
Keyword Recognition: Identify keywords and phrases related to the topic.
Intent Understanding: Understand the purpose of the copy based on the usage scenario and target audience.
4. Content Generation
Copy Writing: Generate copy based on pre-trained models and specific inputs.
Style Adaptation: Adjust the style of the generated content to match specific brand or audience characteristics.
5. Post-processing and Optimization
Quality Control: Ensure the quality of the copy through automatic or manual review.
Personalization Adjustment: Adjust the generation strategy based on feedback and user needs.
6. Evaluation and Feedback
Performance Evaluation: Monitor the effectiveness of the generated copy, such as attractiveness, relevance, etc.
Continuous Learning: Continuously optimize the model using feedback and new data.
提供机构:
杭州谦贞数字科技有限公司
创建时间:
2023-11-23
搜集汇总
数据集介绍
特点
该数据集名为'文案生成训练数据',包含9989条数据,主要用于自动生成创意文案,适用于营销广告、内容创作、产品描述等多种场景。数据生成依赖于自然语言处理技术,包括数据预处理、语言模型、上下文理解等步骤。
以上内容由遇见数据集搜集并总结生成


