RankArena
收藏arXiv2025-08-07 更新2025-08-09 收录
下载链接:
https://rankarena.ngrok.io/
下载链接
链接失效反馈官方服务:
资源简介:
RankArena是一个统一的平台,用于比较和分析检索、重排和RAG系统的性能,并收集人类和LLM的反馈。它支持多种评估模式,包括直接重排可视化、盲匹配对比较、监督手动文档注释和端到端RAG答案质量评估。该平台还集成了LLM-as-a-judge评估,能够比较模型生成的排名和人类真实标注。所有交互都存储为结构化评估数据集,可用于训练重排器、奖励模型、判断代理或检索策略选择器。RankArena旨在解决评估检索增强生成(RAG)和文档重排系统质量的问题,由于缺乏可扩展的、以用户为中心的、多视角的评估工具,这仍然是一个挑战。
RankArena is a unified platform for comparing and analyzing the performance of retrieval, reranking, and RAG systems, while collecting feedback from both humans and LLMs. It supports multiple evaluation modes, including direct reranking visualization, blind pairwise comparison, supervised manual document annotation, and end-to-end RAG answer quality assessment. The platform also integrates LLM-as-a-judge evaluation, which enables comparison between model-generated rankings and human ground-truth annotations. All interactions are stored as structured evaluation datasets that can be used to train rerankers, reward models, judgment agents, or retrieval strategy selectors. RankArena aims to address the challenge of evaluating the quality of retrieval-augmented generation (RAG) and document reranking systems, which remains a critical issue due to the lack of scalable, user-centric, and multi-perspective evaluation tools.
提供机构:
因斯布鲁克大学
创建时间:
2025-08-07
原始信息汇总
🔍 RerankArena数据集概述
🎯 核心功能
- 多模态评估:用户投票、LLM评判、基准测试分数
- 实时竞赛:竞技场式头对头比较
- 综合基准测试:BEIR、DL19、DL20和自定义数据集
- 高级分析:统计显著性、聚类、相关性
- RAG管道测试:端到端检索增强生成
📊 支持方法
- 检索:BM25、DPR、BGE、ColBERT、Contriever、在线搜索
- 重新排序:多种重新排序方法和模型
- 生成:通过Together AI使用Llama 3.3 70B
- 评估:NDCG、MAP、MRR、RBO、ELO评分
- 数据集:维基百科、MS MARCO、BEIR集合
📚 标签描述与用例
💬 RAG竞技场
- 端到端检索增强生成管道评估
- 在线和离线文档检索
- 并排重新排序比较
- LLM答案生成与来源归属
🎯 直接重新排序
- 使用自己的文档或JSON上传测试单个重新排序方法
- JSON文件上传支持
- 实时重新排序结果
⚔️ 1v1重新排序竞技场
- 头对头比较两个重新排序方法
- 用户投票系统
- LLM评判评估
🛠️ 检索器+重新排序器
- 完整检索和重新排序管道
- 多种检索方法(BM25、DPR、BGE等)
- 在线网络搜索通过Serper API
🎭 匿名竞技场
- 隐藏方法身份的公正评估
- 无偏见评估
- 统计比较
📈 BEIR评估
- 在标准BEIR数据集和TREC深度学习任务上评估方法
- 14+ BEIR数据集(COVID、NFCorpus等)
- 标准IR指标(NDCG@k、MAP@k、MRR)
✏️ 文档注释
- 通过手动排名文档相关性创建地面真实注释
- 直观的拖放排名
- 完整文档内容显示
🏆 竞技场排行榜
- 查看综合排名结合用户投票、LLM评估和基准分数
- ELO评分系统
- 多维度性能分析
🏗️ 技术架构
📚 数据层
- 用户数据:会话跟踪、投票历史
- 交互:所有活动的JSON日志记录
- 基准测试:BEIR数据集、自定义评估
- 注释:手动相关性判断
🔧 处理层
- Rankify:多种重新排序方法
- 检索器:BM25、神经检索器
- LLM评判:自动评估
- 分析:统计分析引擎
🎨 表示层
- Gradio UI:交互式Web界面
- Plotly图表:高级可视化
- 实时更新:渐进式反馈
- 导出选项:CSV、JSON下载
搜集汇总
数据集介绍
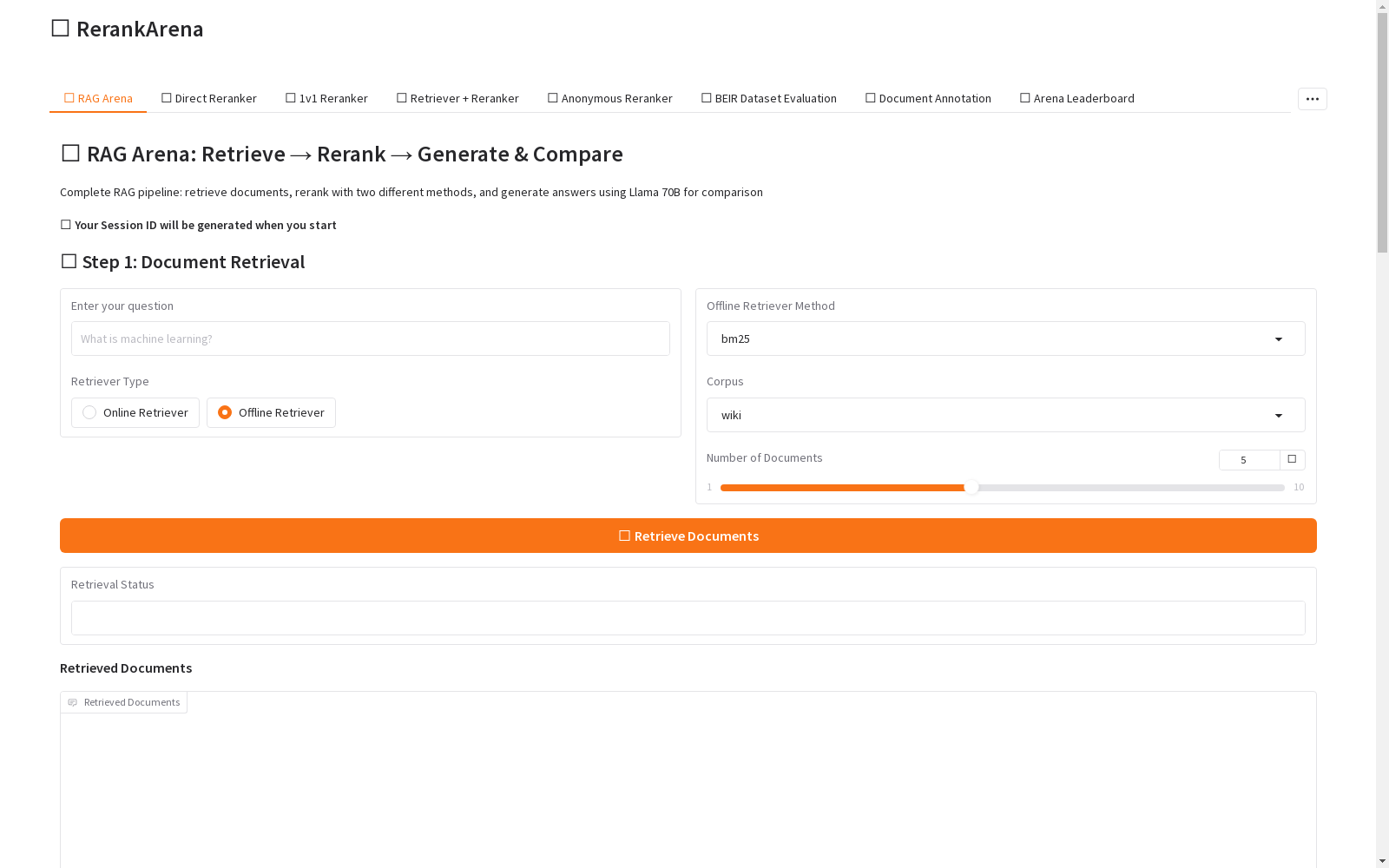
构建方式
RankArena数据集通过集成多种评估模式构建,包括直接重排序可视化、盲对比实验、人工标注以及端到端RAG质量评估。平台支持人类和大型语言模型(LLM)作为评委,收集细粒度的相关性反馈,如成对偏好和完整列表标注,同时记录辅助元数据如移动指标、标注时间和质量评级。所有交互数据均以结构化形式存储,便于后续模型训练和分析。
特点
RankArena数据集的特点在于其多模态评估能力,支持检索、重排序和RAG系统的全面评估。数据集不仅包含人类偏好数据,还整合了LLM生成的反馈,提供了丰富的多视角评估信号。其结构化设计使得数据可用于训练重排序模型、奖励模型和检索策略选择器,同时支持人类与LLM在排序任务中的对齐研究。
使用方法
RankArena数据集的使用方法灵活多样,研究人员可通过平台进行盲对比实验收集偏好数据,或利用LLM评委模块自动化评估检索和RAG输出。数据集支持训练监督重排序模型和奖励模型,也可用于分析人类与LLM在评估中的差异。此外,平台提供的排行榜聚合功能允许用户综合比较不同模型在多样检索任务中的表现。
背景与挑战
背景概述
RankArena数据集由奥地利因斯布鲁克大学的研究团队于2025年提出,旨在解决检索增强生成(RAG)和文档重排序系统评估中的关键挑战。该数据集通过整合人类反馈和大型语言模型(LLM)的评估,提供了一个统一的平台,用于多角度比较和分析检索管道、重排序器及RAG系统的性能。RankArena支持多种评估模式,包括直接重排序可视化、盲对比评估、监督手动文档标注以及端到端RAG答案质量评估,显著推动了信息检索和自然语言处理领域的发展。
当前挑战
RankArena数据集面临的挑战主要包括两方面:其一,在领域问题解决上,如何准确评估RAG系统和文档重排序的复杂性能,尤其是在多阶段管道中保持文档相关性和生成答案的忠实性;其二,在构建过程中,如何高效整合人类和LLM的反馈,确保评估的一致性和可扩展性,同时处理不同评估模式下的数据异构性。此外,平衡人类标注的高成本与LLM评估的自动化需求,也是该数据集构建中的关键挑战。
常用场景
经典使用场景
RankArena数据集在信息检索与生成领域具有广泛的应用场景,特别是在评估检索增强生成(RAG)系统和文档重排序算法的性能时表现突出。通过结合人类反馈和大型语言模型(LLM)的自动化评估,该数据集能够为研究人员提供多角度的性能分析工具。其经典使用场景包括直接比较不同重排序算法的输出效果,进行盲测对比实验,以及评估端到端RAG系统的生成质量。这种多模态评估方式为信息检索领域的研究提供了全新的视角。
衍生相关工作
RankArena数据集已经衍生出多个重要的相关研究工作。基于其评估框架,研究人员开发了DynRank动态提示检索系统,改进了零样本文档重排序性能。Asrank等研究利用该数据集的反馈机制探索了基于答案线索的重排序方法。在RAG系统评估方面,衍生出了Tempretriever等时间敏感检索系统。数据集还启发了对LLM评判机制与人类偏好对齐度的深入研究,推动了检索系统评估方法学的创新。
数据集最近研究
最新研究方向
随着大语言模型(LLMs)和检索增强生成(RAG)系统的快速发展,RankArena作为一个统一的评估平台,为检索、重排序和RAG系统的性能评估提供了多视角、用户中心化的解决方案。该平台整合了人类反馈和LLM作为评判者的自动化评估,支持多种评估模式,包括直接重排序可视化、盲对比评估、监督式文档标注以及端到端RAG答案质量评估。RankArena的推出填补了传统静态评估工具在捕捉用户偏好和动态评估需求方面的不足,为训练和优化重排序模型、奖励模型以及检索策略选择器提供了结构化数据集。其前沿研究方向包括探索人类与LLM在排序任务中的一致性、自适应基准测试的演进以及多阶段检索生成管道的综合评估,对推动信息检索和自然语言处理领域的进步具有重要意义。
相关研究论文
- 1RankArena: A Unified Platform for Evaluating Retrieval, Reranking and RAG with Human and LLM Feedback因斯布鲁克大学 · 2025年
以上内容由遇见数据集搜集并总结生成


