OmniCoT
收藏arXiv2026-06-29 更新2026-07-01 收录
下载链接:
https://huggingface.co/datasets/Eustia1/OmniCoT/
下载链接
链接失效反馈官方服务:
资源简介:
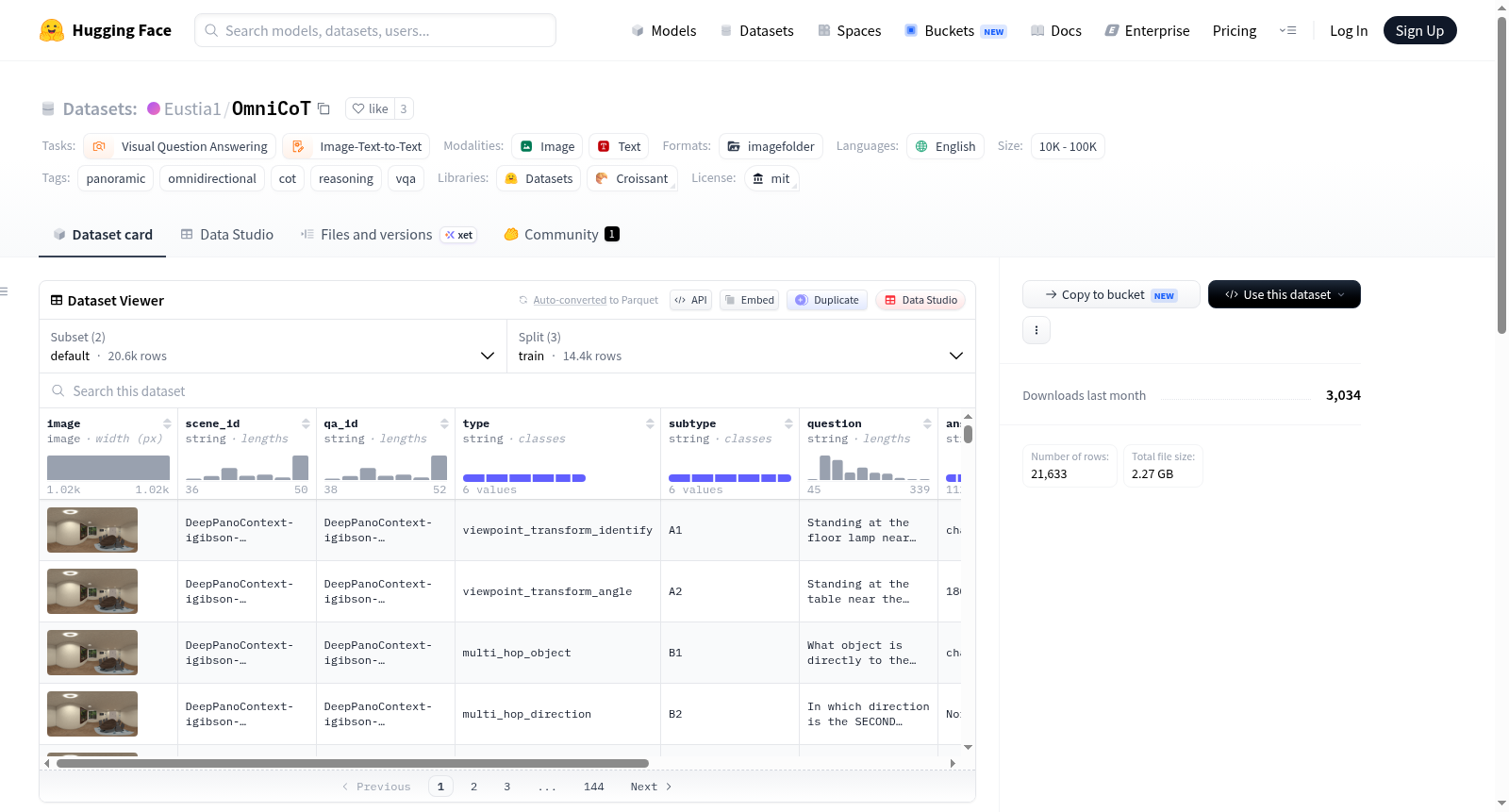
OmniCoT是由上海交通大学、香港科技大学(广州)等机构联合构建的全球多步全景推理基准数据集,旨在推动多模态大语言模型在360度全景图像中的复杂空间推理能力。该数据集包含总计21.6K条高质量问答对,涵盖4.2K张全景图像,通过自动化与人工标注相结合的混合流程生成,并附有结构化的逐步思维链注释。其创建过程基于三维场景几何到结构化语言表示的转换,遵循“观察-定位-移动”的渐进式问题分类法,确保问题需要多跳推理和全局信息整合。该数据集主要应用于评估和训练模型在全景环境下的空间理解能力,解决现有基准中问题过于简单、未能充分利用全景图像全局视野的核心缺陷,为自动驾驶、具身智能等领域的全景空间推理研究提供标准化测试平台。
OmniCoT is a global multi-step panoramic reasoning benchmark dataset jointly constructed by institutions including Shanghai Jiao Tong University, The Hong Kong University of Science and Technology (Guangzhou), and others, aiming to advance the complex spatial reasoning capabilities of multimodal large language models (LLMs) in 360° panoramic images. This dataset contains a total of 21.6K high-quality question-answer pairs, covering 4.2K panoramic images, and is generated via a hybrid workflow combining automated annotation and manual labeling, with structured step-by-step chain-of-thought annotations attached. Its construction process is based on the conversion from 3D scene geometry to structured linguistic representations, and follows the progressive question classification framework of "Observe-Locate-Move", ensuring that the questions require multi-hop reasoning and global information integration. This dataset is mainly used to evaluate and train models' spatial understanding capabilities in panoramic environments, addressing the core flaws of existing benchmarks where questions are overly simple and fail to fully utilize the global field of view of panoramic images, providing a standardized test platform for panoramic spatial reasoning research in fields such as autonomous driving and embodied intelligence.
提供机构:
上海交通大学; 香港科技大学(广州); 穆罕默德·本·扎耶德人工智能大学; 吉林大学; 清华大学; 湖南大学; 上海人工智能实验室; 特伦托大学; 香港科技大学
创建时间:
2026-06-29
搜集汇总
数据集介绍
构建方式
OmniCoT的构建依托于结构化场景序列化技术与混合数据生成管线。研究团队首先将三维场景几何信息转化为自然语言描述,在此基础上,利用大语言模型(如DeepSeekv3.2和Qwen3-Max)依据“看—定位—移动”三维问题分类体系,自动生成涵盖视角变换、对象间关系推理及具身行动模拟的多跳问题。生成的候选问题经过双大模型评分器从格式合规性、对象唯一性、逻辑一致性等六个维度筛选,并结合专家人工审核,确保高质量问题-答案对。随后,采用类型感知的链式思维生成框架,通过分阶段合成、精简与质量评估,构建带有显式中问推理步骤与全景证据关联的思维链数据。最终通过随机抽样的专家验证,保证整体数据集的准确性与推理质量。
使用方法
OmniCoT的使用方法分为评估与训练两大场景。在评估时,用户可将等距柱状投影全景图像与对应问题输入多模态大模型,模型需输出显式链式思维推理过程及最终答案(如物体名称、方位或角度)。评估框架采用二维度量体系,涵盖通用推理质量(精确率、召回率、F1值)与全景空间推理质量(视角一致性、空间证据充分性、推理可行性),通过大模型裁判进行自动化评分。在训练方面,研究者基于OmniCoT-T采用两阶段策略:首先通过监督微调(SFT)使模型掌握结构化全景推理协议,确保推理步骤与视觉证据锚定;随后使用组相对策略优化(GRPO)强化长程空间推理能力,通过格式奖励、准确率奖励与重复惩罚的组合,引导模型生成思维连贯、证据充分且无退化现象的推理链。
背景与挑战
背景概述
全景图像凭借其360°×180°的广阔视野,为具身智能、自动驾驶等新兴领域提供了前所未有的环境感知能力。然而,现有的全景空间推理基准大多局限于局部线索或单步/一步式推理,未能充分挖掘全景图像支持全局多步推理的独特优势。为弥合这一鸿沟,上海交通大学、香港科技大学(广州)等多家机构的研究团队于2026年提出了OmniCoT数据集。该数据集由基准测试集OmniCoT-B、人工标注的真实世界子集OmniCoT-Real以及训练集OmniCoT-T组成,旨在推动多模态大语言模型在全景场景中实现“看得更多、推理得更深”。通过引入“观察-定位-移动”的渐进式问题分类法,OmniCoT系统性地挑战模型在视角变换、物体间关系推理及具身动作模拟等方面的能力,为全景空间推理研究树立了全新的标杆与评价标准。
当前挑战
OmniCoT所应对的核心挑战在于引导多模态大语言模型突破局部线索的桎梏,真正实现基于全局证据的多步推理。当前主流模型在“定位”维度普遍表现乏力,揭示出多跳拓扑推理的艰巨性。同时,思维链在不同模型家族中呈现出截然相反的效果:开源模型因此受益,而闭源模型却可能因累积幻觉而导致性能下降。在数据集构建层面,研究人员面临两大难题:其一,如何在合成场景中生成兼具自然语言流畅性与答案唯一性的多步推理问答对;其二,如何凭借有限的人力对长链条思维过程进行大规模质量控制,以确保数据集的可靠性与可扩展性。OmniCoT通过混合自动化生成与专家验证的流水线,巧妙地平衡了数据规模与质量,为全景空间推理研究提供了坚实的数据基础。
常用场景
经典使用场景
OmniCoT数据集最经典的使用场景是作为全景空间推理的基准测试,专门用于评估多模态大语言模型在360°×180°全视场下的全局、多跳推理能力。它要求模型不仅依赖局部视觉线索,而是能够综合利用全景图像中的全局证据,完成诸如视点变换、物体间空间关系推理以及具身动作模拟等复杂任务。与先前仅关注少数推理步骤或局部线索的全景基准不同,OmniCoT通过结构化的问题分类体系(See-Locate-Move)迫使模型真正“看得更多、推理更多”,从而校准全景空间推理的难度标准,推动该领域的研究迈向更高层次。
解决学术问题
OmniCoT数据集着力解决现有全景空间推理基准任务过于简单、未能发挥全景图像固有优势的核心学术问题。此前基准如OSR-Bench和ODI-Bench多依赖合成数据且聚焦于单步或少量步骤的局部推理,忽视了全景图360°信息所支持的复杂多步推理潜力。OmniCoT通过引入跨视点的多跳推理、人工标注的真实世界子集以及结构化的Chain-of-Thought标注,系统性地提升了评测的挑战性与真实性。它使研究者能够准确衡量模型是否具有真正的全局空间推理能力,而非仅停留在局部识别的层面,其意义在于为全景空间推理研究提供了一个可靠的、可横向对比的标杆,促进了该领域理论与方法的实质性进步。
实际应用
在实际应用中,OmniCoT所定义的推理能力直接服务于具身智能、自主导航与虚拟现实等前沿领域。例如,在具身智能机器人执行室内导航任务时,机器人需利用全景感知能力综合理解周边环境,识别目标物体相对位置并进行多步路径规划;在自动驾驶车辆的全景环视系统中,模型需通过多视点推理预测周围物体的运动轨迹与潜在碰撞风险。此外,OmniCoT还可用于增强虚拟现实中的空间交互体验,使AI助手能够理解用户在360°环境中的视角变化与移动意图,从而提供精准的语音或视觉反馈。这些场景受益于OmniCoT所倡导的“全局证据驱动、多跳推理”的范式,将全景空间推理从学术论文推向真实部署。
数据集最近研究
最新研究方向
当前全景空间推理研究的前沿方向聚焦于推动多模态大语言模型从依赖局部线索和单跳推理的浅层理解,迈向能够整合全局360°视觉证据并进行多跳推理的深层次认知。OmniCoT基准的提出正是对这一趋势的精准响应,它通过设计“视-定-动”三维渐进式问题分类体系,系统性地要求模型在视点变换、物间关系推理及具身动作模拟等复杂任务中展现真正的全景智能。该基准不仅评估最终答案的准确性,更独创性地引入了对中间推理链条质量的度量,揭示了当前顶尖模型在“语言盲航”现象下的关键缺陷——即其推理过程往往由文本先验驱动而非真正的跨模态空间感知。这一突破性工作重新校准了全景推理的难度标尺,为自主驾驶、具身智能等应用领域提供了至关重要的评估基石,并指明了通过强化学习优化空间推理链条的未来方向。
相关研究论文
- 1OmniCoT: A Benchmark for Global and Multi-Step Panoramic Reasoning上海交通大学; 香港科技大学(广州); 穆罕默德·本·扎耶德人工智能大学; 吉林大学; 清华大学; 湖南大学; 上海人工智能实验室; 特伦托大学; 香港科技大学 · 2026年
以上内容由遇见数据集搜集并总结生成


