FinanceReasoning
收藏arXiv2025-06-06 更新2025-06-10 收录
下载链接:
https://bupt-reasoning-lab.github.io/FinanceReasoning
下载链接
链接失效反馈官方服务:
资源简介:
FinanceReasoning是一个专为评估大型推理模型在金融数值推理问题中的推理能力而设计的基准数据集。该数据集由北京邮电大学的研究团队创建,包含2238个问题,覆盖了广泛的金融知识,旨在解决现有数据集在金融领域知识覆盖面、推理复杂性和准确性方面的不足。每个问题都包括混合上下文、明确的问题、Python格式的解决方案和精确答案,为准确评估大型推理模型的复杂数值推理能力提供了可靠的参考。此外,还构建了一个包含3133个Python格式函数的全面金融函数库,以增强模型的金融推理能力。
FinanceReasoning is a benchmark dataset specifically designed to evaluate the reasoning capabilities of large reasoning models on financial numerical reasoning problems. Developed by the research team from Beijing University of Posts and Telecommunications, this dataset contains 2,238 questions covering a wide range of financial knowledge, aiming to address the shortcomings of existing datasets in terms of financial domain knowledge coverage, reasoning complexity and accuracy. Each question includes mixed context, explicit problem statement, Python-formatted solution and precise answer, providing a reliable reference for accurately evaluating the complex numerical reasoning capabilities of large reasoning models. In addition, a comprehensive financial function library containing 3,133 Python-formatted functions has been constructed to enhance the financial reasoning abilities of the models.
提供机构:
北京邮电大学
创建时间:
2025-06-06
原始信息汇总
FinanceReasoning 数据集概述
基本信息
- 数据集名称: FinanceReasoning
- 研究机构: 北京邮电大学
- 会议: ACL 2025 Main Conference
- 论文状态: ACL 2025主会议论文
- 代码与资源: 提供arXiv论文和代码链接
核心贡献
-
可信度提升:
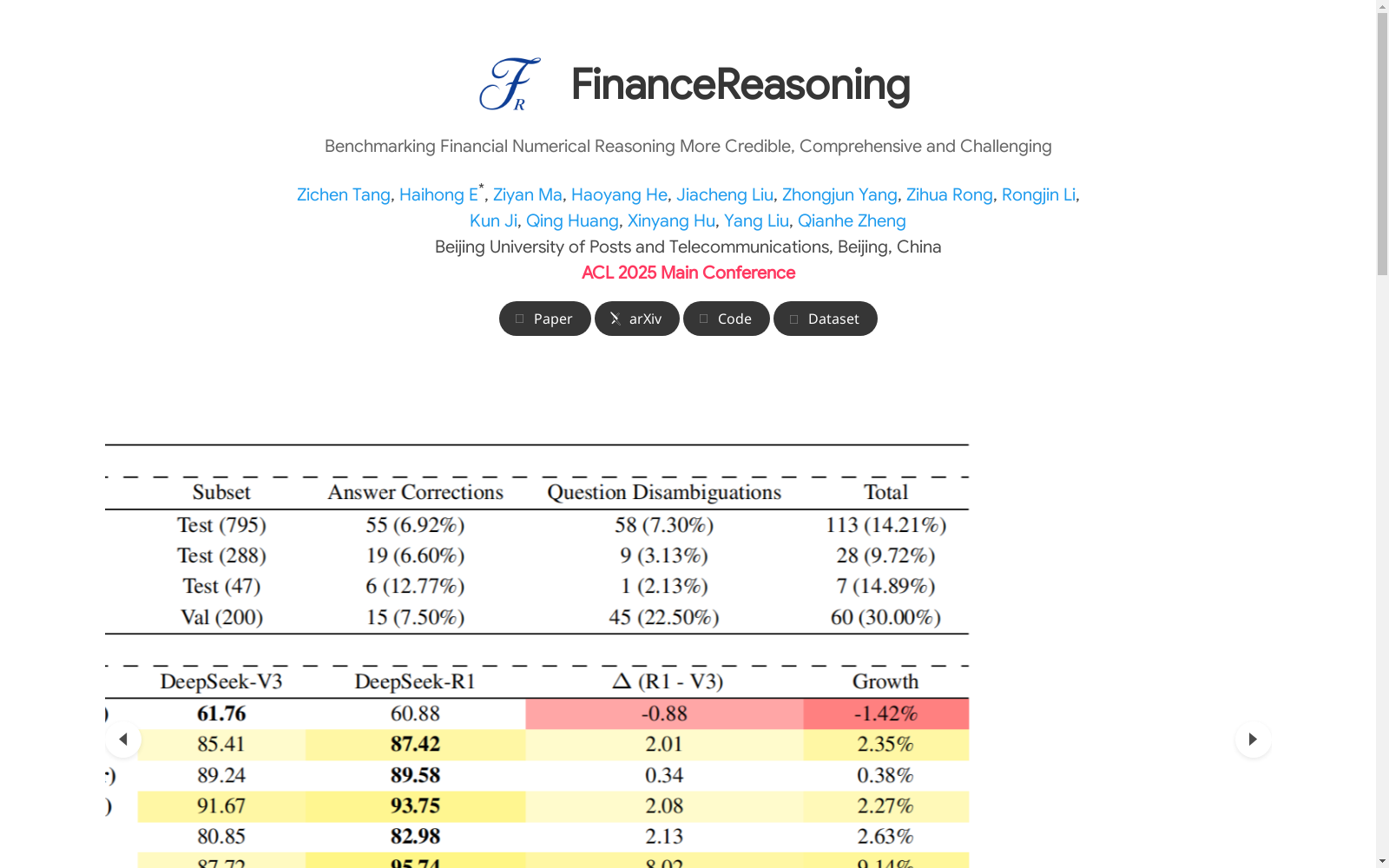
- 更新了4个公开数据集中15.6%的问题
- 新增908道带Python详细解法的问题
- 建立了严格的评估标准
-
全面性增强:
- 覆盖67.8%的金融概念和公式
- 构建3,133个Python格式化函数
- 显著提升模型表现(如GPT-4o从83.2%→91.6%)
-
挑战性设计:
- 包含238道高难度问题
- 需要应用多重金融公式进行精确数值推理
- 当前最佳模型(OpenAI o1+PoT)准确率89.1%
关键技术指标
- 知识覆盖率: 计算问题涉及的金融计算占金融百科全书比例
- 重标注比例: 测试/验证集样本更新比例9.7%-30%
- 性能提升: DeepSeek-RT较DeepSeek-V3有显著改进
模型要求
- 需基于给定条件(如最低预期回报率)选择合适金融公式
- 执行带舍入要求的逐步精确数值计算
搜集汇总
数据集介绍
构建方式
FinanceReasoning数据集的构建采用了严谨的多阶段流程,首先对四个公开数据集(CodeFinQA、CodeTAT-QA、FinCode、FinanceMath)的15.6%样本进行重新标注,修正了问题表述模糊、答案错误等缺陷。随后通过GPT-4o生成908道新问题,并组织8名跨学科研究生与2名CFA持证专家进行双重验证,最终形成包含2,238道题目的基准测试集。每个问题均配备混合上下文、Python解决方案及精确数值答案,同时构建了包含3,133个Python格式化函数的金融知识库作为结构化推理支持。
特点
该数据集具有三大核心特征:可信性方面采用双盲审核机制,确保问题无歧义且解决方案可复现;全面性覆盖67.8%的金融概念与公式,包含1,000道简单题、1,000道中等难度题及238道高难度题,难度等级通过运算符数量、括号对数和代码行数等指标量化;挑战性体现在要求模型综合应用多种金融公式进行精确计算,最优模型(OpenAI o1+PoT)在难题集准确率仅达89.1%,暴露出数值精度不足的共性缺陷。
使用方法
使用该数据集时建议采用三阶段流程:首先通过Program-of-Thought(PoT)提示法生成可执行代码,相比Chain-of-Thought(CoT)可降低68.8%的token消耗;其次结合内置金融函数库进行知识增强,实验表明LLM指导的知识检索能使GPT-4o准确率提升8.41%;最后可采用Reasoner-Programmer组合策略,如让DeepSeek-R1负责逻辑推理、Claude 3.5 Sonnet执行代码生成,该方案可修正91.7%的计算错误。评估时需严格遵循0.2%误差容限标准,重点关注公式应用与数值计算两类错误。
背景与挑战
背景概述
FinanceReasoning是由北京邮电大学推理实验室(BUPT-Reasoning-Lab)于2025年6月提出的金融数值推理基准数据集,旨在评估大型推理模型(LRMs)在金融领域的复杂数值推理能力。该数据集通过整合四个公开数据集的1,420个修订问题和908个由GPT-4o生成的新问题,构建了包含2,238个问题的综合性评测集,覆盖67.8%的金融概念与公式。其创新性体现在三个方面:通过专家标注的Python解决方案和严格评估标准提升可信度;构建包含3,133个Python格式化函数的金融知识库增强模型推理能力;设计238个需多公式联用的高难度问题以检验模型极限性能。该数据集推动了金融领域复杂推理任务的评估方法学研究,并为模型优化提供了结构化知识支持。
当前挑战
FinanceReasoning针对两大挑战展开攻关:领域问题层面,现有金融数值推理数据集存在标注质量不足(如CodeFinQA中14.21%的问题需修正)、知识覆盖狭窄(仅涵盖32.2%金融概念)和难度分层缺失等问题,难以准确评估模型在真实金融场景中的多步推理与精确计算能力;构建过程层面,需解决金融专业标注成本高昂(依赖8名跨学科研究生和2名CFA专家)、复杂问题自动化生成的可靠性(LLM生成问题的纠错率达23.7%)以及评估标准统一性(将误差容忍度从1%压缩至0.2%)等难题。实验表明,当前最优模型(OpenAI o1)在硬性子集上准确率仅89.1%,仍面临公式误用(35%错误率)和数值精度不足(37.5%错误率)等核心挑战。
常用场景
经典使用场景
FinanceReasoning数据集专为评估大型推理模型(LRMs)在金融数值推理任务中的表现而设计。其经典使用场景包括金融定量分析、投资组合管理以及风险评估等领域。通过提供混合上下文、明确的Python解决方案和精确答案,该数据集能够全面测试模型在复杂金融计算中的推理能力。
解决学术问题
该数据集解决了金融领域数值推理任务中的多个关键学术问题,包括模型对金融概念的理解、多步精确计算能力以及复杂公式的应用。通过更新和扩充现有数据集,FinanceReasoning提供了更可信、全面且具有挑战性的评估标准,填补了金融领域复杂推理任务评估的空白。
衍生相关工作
FinanceReasoning的推出催生了一系列相关研究,包括基于检索增强生成(RAG)的金融知识增强方法、模型协作策略(如Reasoner与Programmer模型的结合)以及针对金融领域复杂推理任务的优化算法。这些工作进一步推动了大型语言模型在专业领域的应用和发展。
以上内容由遇见数据集搜集并总结生成


