jhu-clsp/FollowIR-train
收藏Hugging Face2024-03-25 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/jhu-clsp/FollowIR-train
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
language:
- en
tags:
- retrieval
- information retrieval
pretty_name: FollowIR-train
size_categories:
- 1K<n<10K
---
# Dataset Summary
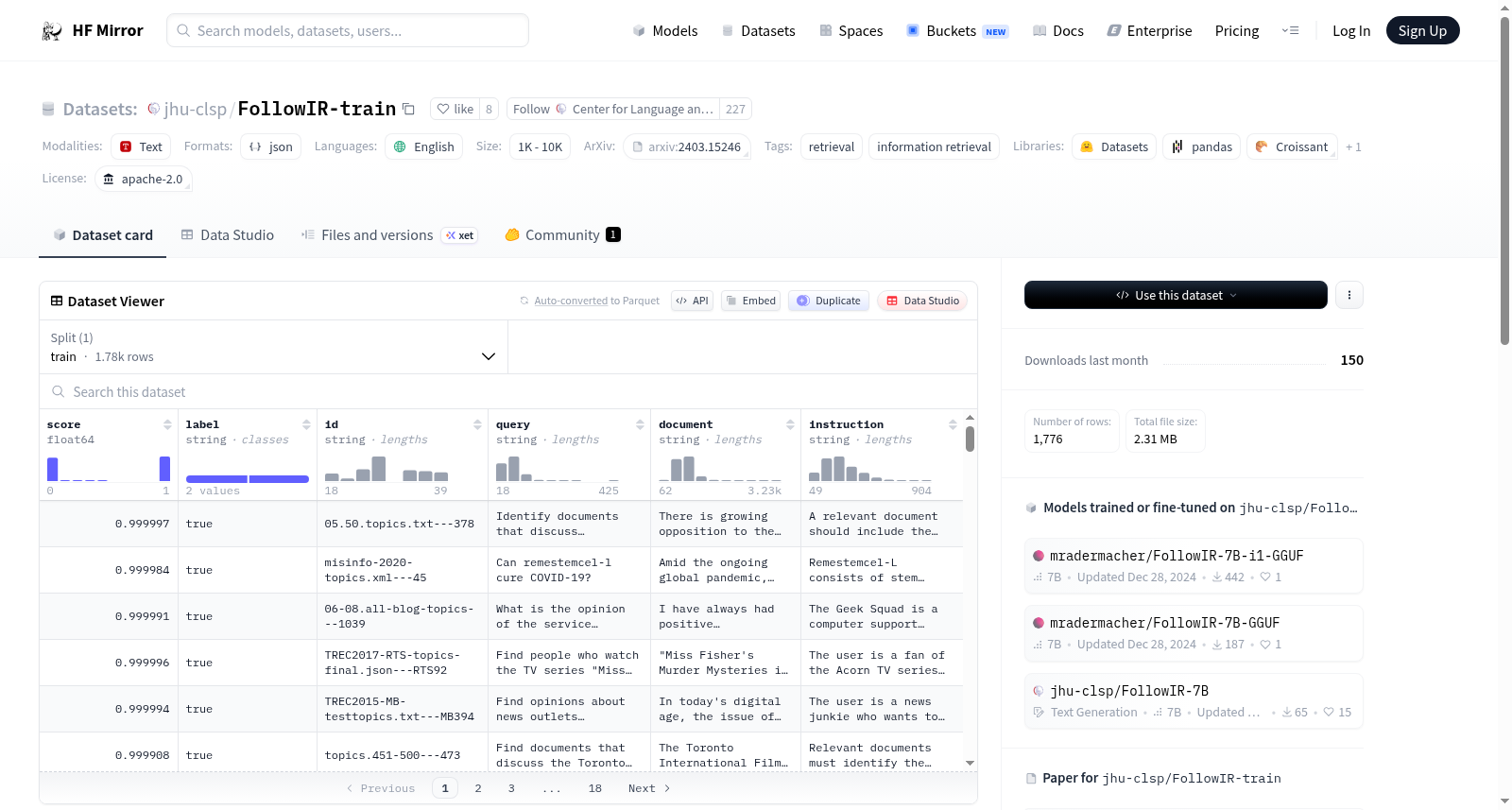
FollowIR-train contains ~1800 query and instruction pairs, with labels for relevance (true or false). It can be used to train retrieval models to better follow instructions (see [FollowIR-7B](https://huggingface.co/jhu-clsp/FollowIR-7B)).
The dataset was created by taking instruction and query pairs from all [TREC tracks](https://trec.nist.gov/) (which provides instructions as "narratives") from 1993-on that provided these instructions. Synthetic documents were then created from GPT-3.5-Turbo-1106 and filtered using Mistral-Instruct-7B-v0.2. This dataset contains the filtered instructions only. See [jhu-clsp/FollowIR-train-raw]() for the raw data before filtering.
- **Repository:** [orionw/FollowIR](https://github.com/orionw/FollowIR)
- **Paper:** https://arxiv.org/abs/2403.15246
- **Model Trained on the Dataset:** [jhu-clsp/FollowIR-7B](https://huggingface.co/jhu-clsp/FollowIR-7B/)
The structure of the dataset is as follows:
```
{
"score": the score from Mistral-Instruct-7B-v0.2 of whether it was relevant or not (1 is relevant, 0 is not)
"label": the label of relevance from GPT-3.5-Turbo-1106 who created the document
"id": the id from the original TREC track and the file it came from
"document": the synthetic document produced by GPT-3.5-Turbo-1106 given the original instruction, query, and label
"query": the query written by TREC
"instruction": the instruction (or narrative) written by TREC for human annotation
}
```
# Citation
```bibtex
@misc{weller2024followir,
title={FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions},
author={Orion Weller and Benjamin Chang and Sean MacAvaney and Kyle Lo and Arman Cohan and Benjamin Van Durme and Dawn Lawrie and Luca Soldaini},
year={2024},
eprint={2403.15246},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
```
提供机构:
jhu-clsp
原始信息汇总
数据集概述
基本信息
- 许可证: Apache-2.0
- 语言: 英语
- 标签: 检索, 信息检索
- 美观名称: FollowIR-train
- 大小分类: 1K<n<10K
数据集内容
- 包含内容: 约1800对查询和指令配对,带有相关性标签(真或假)。
- 用途: 用于训练检索模型,以更好地遵循指令。
- 数据来源: 从1993年至今的所有TREC轨道中提取的指令和查询对,使用GPT-3.5-Turbo-1106生成合成文档,并通过Mistral-Instruct-7B-v0.2进行过滤。
数据集结构
json { "score": 相关性评分(1为相关,0为不相关), "label": 由GPT-3.5-Turbo-1106创建的文档的相关性标签, "id": 原始TREC轨道和文件来源的ID, "document": 根据原始指令、查询和标签由GPT-3.5-Turbo-1106生成的合成文档, "query": TREC编写的查询, "instruction": TREC为人类注释编写的指令(或叙述) }
引用信息
bibtex @misc{weller2024followir, title={FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions}, author={Orion Weller and Benjamin Chang and Sean MacAvaney and Kyle Lo and Arman Cohan and Benjamin Van Durme and Dawn Lawrie and Luca Soldaini}, year={2024}, eprint={2403.15246}, archivePrefix={arXiv}, primaryClass={cs.IR} }
搜集汇总
数据集介绍
背景与挑战
背景概述
FollowIR-train是一个英文信息检索数据集,包含约1800个查询和指令对,并带有相关性标签(true或false),用于训练检索模型以更好地遵循指令。该数据集通过从TREC轨道(1993年起)收集指令和查询,使用GPT-3.5-Turbo-1106生成合成文档,并经过Mistral-Instruct-7B-v0.2过滤而成,结构包括score、label、id、document、query和instruction字段,支持如FollowIR-7B等模型训练。
以上内容由遇见数据集搜集并总结生成


