HOTPOTQA
收藏arXiv2018-09-26 更新2024-06-21 收录
下载链接:
https://HotpotQA.github.io
下载链接
链接失效反馈官方服务:
资源简介:
HOTPOTQA是一个包含113,000个基于维基百科的问题-答案对的大型数据集,由卡内基梅隆大学等机构创建。该数据集的特点在于其问题需要通过多文档推理来回答,且问题类型多样,不依赖于预先存在的知识库或知识模式。此外,HOTPOTQA提供了句子级别的支持事实,以帮助QA系统进行强监督推理和解释预测。数据集还引入了新的事实比较问题类型,以测试QA系统提取相关事实和进行必要比较的能力。HOTPOTQA的应用领域主要集中在测试和提升智能系统在自然语言处理中的多跳推理能力,旨在解决现有QA数据集在复杂推理和解释性方面的不足。
HOTPOTQA is a large-scale dataset consisting of 113,000 Wikipedia-based question-answer pairs, created by institutions including Carnegie Mellon University. The core feature of this dataset is that its questions require multi-document reasoning to answer, cover diverse question types, and do not rely on pre-existing knowledge bases or predefined knowledge schemas. In addition, HOTPOTQA provides sentence-level supporting facts to help QA systems conduct strongly supervised reasoning and interpretable prediction. Furthermore, the dataset introduces a novel factual comparison question type to evaluate the ability of QA systems to extract relevant factual information and perform necessary comparative reasoning. The main application scenarios of HOTPOTQA focus on testing and enhancing the multi-hop reasoning capability of intelligent systems in natural language processing, aiming to address the shortcomings of existing QA datasets in complex reasoning and explainability.
提供机构:
卡内基梅隆大学
创建时间:
2018-09-26
搜集汇总
数据集介绍
构建方式
HOTPOTQA的构建基于维基百科文章,通过众包方式收集了113,000个问题-答案对。构建过程中,众包工作者被展示多个支持性上下文文档,并被要求提出需要对所有文档进行推理的问题。这种设计确保了问题涵盖了更自然的、不需要预先存在的知识库架构的多跳问题。此外,众包工作者还被要求提供他们用于回答问题的支持性事实,这些事实也被作为数据集的一部分提供。
特点
HOTPOTQA的主要特点包括:1) 问题需要从多个支持文档中找到并进行推理;2) 问题多样,不受任何预先存在的知识库或知识模式的限制;3) 提供句子级的支持性事实,允许QA系统在强监督下进行推理并解释预测;4) 引入了一种新的事实比较问题类型,测试QA系统提取相关事实和进行必要比较的能力。
使用方法
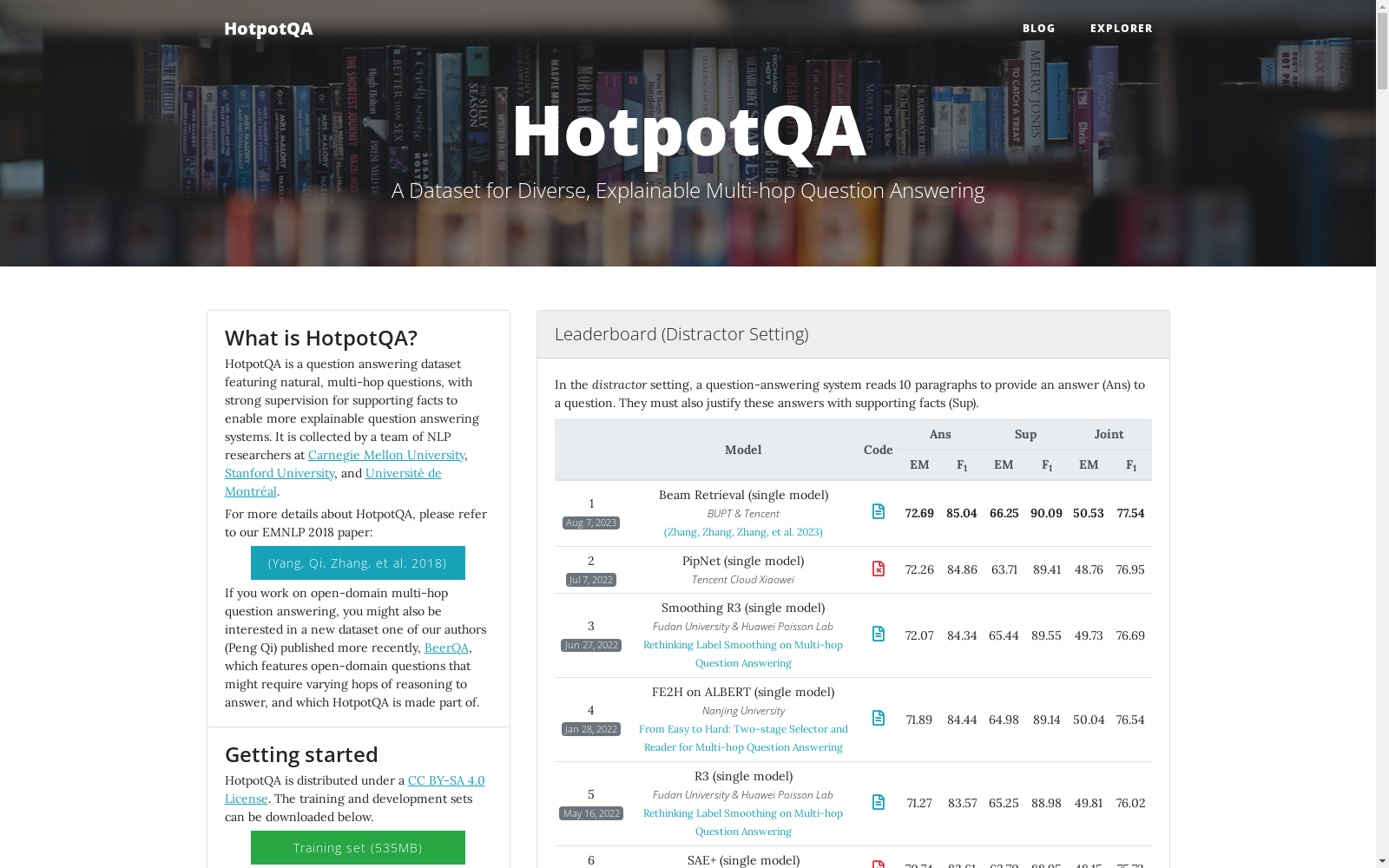
HOTPOTQA可用于训练和评估多跳问答系统。使用者可以通过提供的支持性事实进行强监督训练,以提高模型的推理能力和解释性。数据集分为不同的子集,包括单跳和多跳问题,便于模型在不同难度级别上的训练和测试。此外,数据集还提供了两种基准设置,即干扰设置和全维基设置,以全面评估模型的性能。
背景与挑战
背景概述
HOTPOTQA,由Zhilin Yang、Peng Qi、Saizheng Zhang等研究人员于2018年创建,是一个旨在推动多跳问答系统发展的数据集。该数据集包含113,000个基于维基百科的问题-答案对,其核心研究问题是如何训练问答系统进行复杂推理并提供答案解释。HOTPOTQA的引入填补了现有问答数据集在多跳推理和解释性方面的不足,对自然语言处理领域,特别是问答系统的研究产生了深远影响。
当前挑战
HOTPOTQA面临的挑战主要集中在两个方面:一是如何设计能够真正测试多跳推理能力的问题,这要求系统必须从多个文档中提取信息并进行综合推理;二是数据集构建过程中如何确保问题和答案的多样性,避免受限于预先存在的知识库或知识模式。此外,提供句子级别的支持事实以增强系统的解释能力,也是HOTPOTQA在构建过程中的一大挑战。
常用场景
经典使用场景
HOTPOTQA 数据集的经典使用场景在于其多跳问答任务,要求系统从多个支持文档中提取信息并进行推理以得出答案。这种场景不仅测试了系统的信息检索能力,还评估了其在复杂推理任务中的表现,特别是在需要跨文档进行多步推理的情况下。
衍生相关工作
HOTPOTQA 数据集的发布激发了大量相关研究工作,特别是在多跳问答和可解释性模型领域。例如,后续研究提出了基于 HOTPOTQA 的改进模型,以提高多文档推理的准确性和效率。此外,该数据集还促进了跨学科研究,如结合知识图谱和自然语言处理的混合模型,进一步推动了问答系统的发展。
数据集最近研究
最新研究方向
在自然语言处理领域,HOTPOTQA数据集的最新研究方向主要集中在提升多跳问答系统的推理能力和解释性。研究者们致力于开发能够处理复杂推理任务的模型,这些任务要求系统从多个文档中提取信息并进行综合分析。此外,研究还关注于如何通过提供句子级别的支持事实来增强模型的解释性,使系统能够更透明地展示其推理过程。这些研究不仅推动了问答系统在复杂场景下的应用,还为构建更加智能和可信赖的自然语言处理系统奠定了基础。
相关研究论文
- 1HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering卡内基梅隆大学 · 2018年
以上内容由遇见数据集搜集并总结生成


