reddit_dataset_144
收藏Hugging Face2025-03-19 更新2025-03-20 收录
下载链接:
https://huggingface.co/datasets/ashikshaffi08/reddit_dataset_144
下载链接
链接失效反馈官方服务:
资源简介:
Bittensor Subnet 13 Reddit数据集是Bittensor Subnet 13去中心化网络的一部分,包含预处理后的Reddit帖子和评论数据。这个数据集是实时更新的,支持多种机器学习任务,如情感分析、主题建模等。数据集主要是英文,但也可能是多语言的。每个数据实例包括文本内容、标签、数据类型、社区名称、时间戳、用户名编码和URL编码等信息。
创建时间:
2025-03-19
搜集汇总
数据集介绍
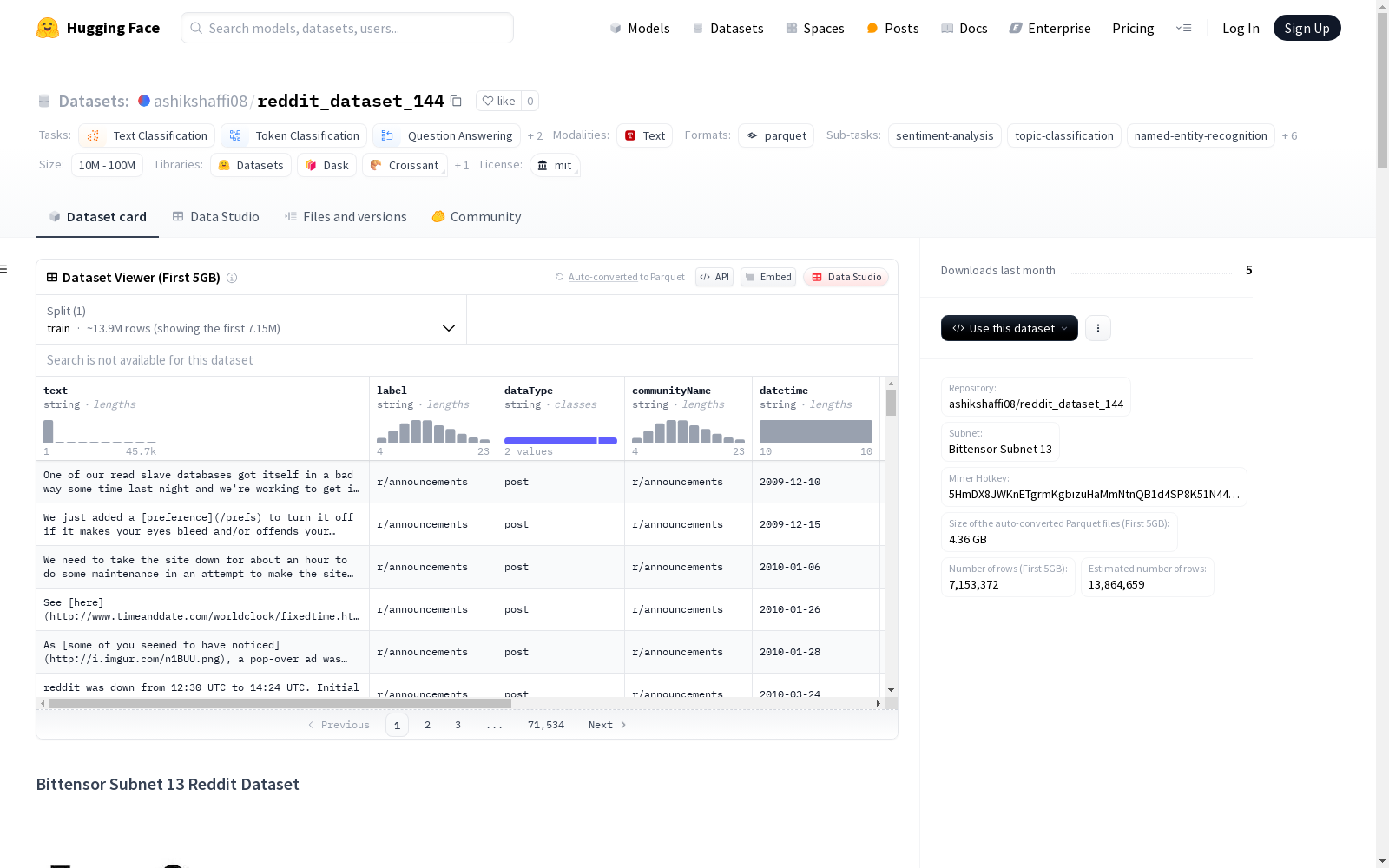
构建方式
该数据集构建于Bittensor Subnet 13去中心化网络之上,通过收集并预处理Reddit平台上的公开帖子和评论数据。数据源严格遵守Reddit的服务条款和API使用指南,确保合法合规。所有用户名和URL均经过编码处理,以保护用户隐私,避免涉及个人或敏感信息。数据集由网络矿工持续更新,提供实时的Reddit内容流,适用于多种分析和机器学习任务。
特点
该数据集以其多语言性和广泛的适用性著称,主要包含Reddit帖子和评论的文本内容,涵盖了情感分析、主题分类、社区分析等多种任务。每个数据实例包含文本、标签、数据类型、社区名称、时间戳等字段,确保了数据的丰富性和多样性。数据集反映了Reddit平台上的动态内容,但也存在潜在的偏见和噪声,需谨慎处理。
使用方法
用户可通过HuggingFace平台访问该数据集,并根据需求自定义数据分割。数据集适用于多种自然语言处理任务,如情感分析、主题建模和内容分类等。使用时应考虑数据的时间戳,避免因实时更新导致的偏差。此外,用户需遵守MIT许可和Reddit的使用条款,确保数据使用的合法性和伦理性。
背景与挑战
背景概述
reddit_dataset_144数据集是Bittensor Subnet 13去中心化网络的一部分,由网络矿工持续更新,提供了实时的Reddit内容流,适用于多种分析和机器学习任务。该数据集由ashikshaffi08于2025年创建,旨在为研究人员和数据科学家提供一个丰富的社交媒体数据源,以探索社交媒体的动态并开发创新应用。数据集涵盖了从2009年至2025年的Reddit公开帖子和评论,内容多样且具有时效性,适用于情感分析、主题建模、社区分析等多种任务。
当前挑战
reddit_dataset_144数据集在构建和使用过程中面临多重挑战。首先,社交媒体数据的多样性和动态性使得数据质量难以保证,可能存在噪声、垃圾信息或无关内容。其次,由于数据实时更新,可能存在时间偏差,影响模型的泛化能力。此外,Reddit平台上的内容反映了特定群体的观点,可能导致数据集存在内容偏见,影响模型的公平性和代表性。最后,尽管数据集通过编码保护了用户隐私,但仍需警惕潜在的隐私泄露风险。这些挑战要求研究人员在使用数据时进行细致的预处理和偏差校正,以确保模型的鲁棒性和可靠性。
常用场景
经典使用场景
在社交媒体分析领域,reddit_dataset_144数据集被广泛用于情感分析和主题建模。研究者通过分析Reddit帖子与评论中的文本内容,能够深入理解用户的情感倾向和社区讨论的热点话题。这种分析不仅有助于揭示公众对特定事件或产品的看法,还能为市场趋势预测提供数据支持。
实际应用
在实际应用中,reddit_dataset_144数据集被用于品牌监控、舆情分析和内容推荐系统。企业可以通过分析Reddit上的用户讨论,及时捕捉市场反馈,优化产品策略。同时,新闻机构利用该数据集进行热点话题追踪,生成更具时效性的新闻报道。
衍生相关工作
基于reddit_dataset_144数据集,研究者开发了多种先进的自然语言处理模型,如基于Transformer的情感分析模型和多标签分类系统。这些工作不仅推动了社交媒体分析技术的发展,还为其他领域如金融预测和公共卫生监测提供了新的研究思路。
以上内容由遇见数据集搜集并总结生成


