cryptpesa/anv_data_ke_kikuyu_scripted
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/cryptpesa/anv_data_ke_kikuyu_scripted
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: audio_id
dtype: string
- name: type
dtype: string
- name: split
dtype: string
- name: recorder_uuid
dtype: string
- name: domain
dtype: string
- name: transcription
dtype: string
- name: language
dtype: string
- name: audio_duration
dtype: float64
splits:
- name: train
num_bytes: 17790375379.375
num_examples: 111197
- name: validation
num_bytes: 1922279561.75
num_examples: 13346
- name: test
num_bytes: 953606178.75
num_examples: 6522
download_size: 20070605071
dataset_size: 20666261119.875
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
提供机构:
cryptpesa
搜集汇总
数据集介绍
构建方式
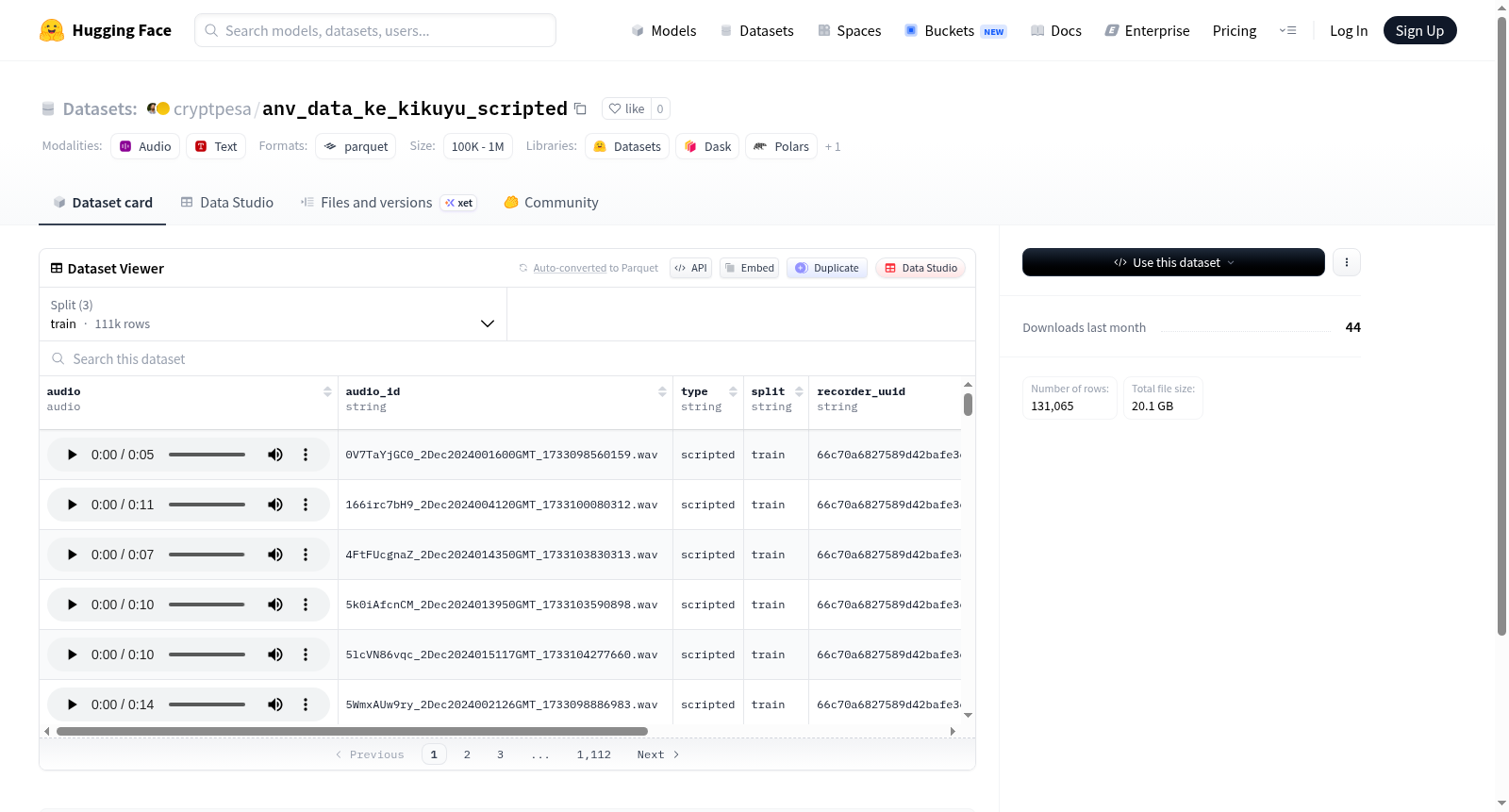
该数据集名为anv_data_ke_kikuyu_scripted,是面向基库尤语(Kikuyu)的语音数据集,旨在支持低资源非洲语言的语音技术研究。其构建方式以大规模脚本化采集为核心:共包含131,065条语音样本,按比例划分为训练集(111,197条)、验证集(13,346条)和测试集(6,522条)。每条数据均以16kHz采样率的音频文件存储,并附带音频ID、类型、数据划分标签、录音设备唯一标识符、领域、转录文本、语言标签及音频时长等结构化信息。数据来源可能涵盖多领域场景,以确保语音内容的多样性。
特点
该数据集的核心特点体现在覆盖完整的语音识别任务所需要素。音频以标准化16kHz采样率存储,适配主流语音处理管线;转录文本与音频严格对齐,为监督学习提供高质量监督信号。数据集包含明确的领域(domain)与类型(type)标签,便于进行领域适应或多任务学习研究。同时,录音设备标识符(recorder_uuid)的保留支持对说话人或设备相关特征的统计分析。整体规模超过130k样本,语音时长总和约达20GB,在基库尤语数据资源中属于较大规模。
使用方法
数据集可通过HuggingFace的datasets库便捷加载,使用默认配置从'data/'目录下按数据划分自动读取分片文件。使用时首先需加载数据集,随后可按标准流程进行音频预处理(如重采样、特征提取)并配合转录文本进行模型训练。特点在于提供预划分的train/validation/test子集,评估流程无需自定义拆分。建议使用1024点梅尔频谱特征或wav2vec 2.0等自监督特征作为输入,结合连接时序分类(CTC)或变换器(Transformer)架构进行端到端基库尤语音识别系统的开发。
背景与挑战
背景概述
该数据集名为anv_data_ke_kikuyu_scripted,由非洲语音技术团队(African Voice Technology)于2023年创建,专注于基库尤语(Kikuyu)的语音识别研究。基库尤语是肯尼亚使用最广泛的土著语言之一,拥有超过600万母语者,但在语音技术领域长期处于资源匮乏状态。该数据集的核心研究问题是如何构建高质量的基库尤语语音语料库,以推动低资源语言在自动语音识别(ASR)系统中的应用。通过收录逾13万条音频样本,涵盖多种领域和说话人特征,该数据集填补了非洲语言语音技术的重要空白,为多语言ASR模型训练提供了关键基准,对促进语言多样性和数字包容具有深远影响。
当前挑战
该数据集所解决的领域挑战在于基库尤语作为低资源语言,缺乏大规模、标准化的语音数据,导致现有ASR模型在识别精度上远低于主流语言。构建过程中面临多重障碍:转录一致性难以保证,因为基库尤语存在多种方言变体且缺乏统一的正字法规范;录音环境复杂,需在嘈杂的家庭、市场等实地场景中采集高质量音频;还需平衡说话人性别、年龄和地域分布,以避免模型产生偏见。此外,数据清洗和标注耗时巨大,涉及对长达11GB原始音频的逐句校验,以及处理录制设备差异带来的信噪比波动,最终形成适用于学术研究与工业落地的可靠语料库。
常用场景
经典使用场景
数据集anv_data_ke_kikuyu_scripted专为基库尤语(Kikuyu)的自动语音识别(ASR)任务而构建,是东非语言语音技术发展的重要基石。该数据集包含超过13万条音频片段,每个片段均配有高精度的文本转写,采样率为16kHz,确保了语音信号的保真度。其典型使用场景在于训练端到端的声学模型与语言模型,研究者常基于此数据搭建Transformer或Conformer架构的系统,以捕捉基库尤语独有的音韵特征。通过将音频与对应文本对齐,该数据集支持从原始波形到字符序列的映射学习,为低资源语言的语音交互提供数据基础。
实际应用
实际应用中,该数据集赋能了基库尤语的语音助手、语音输入法及教育工具的开发。例如,在肯尼亚农业推广中,农民可用母语基库尤语通过语音查询天气或市场价格;医疗领域,语音病历录入系统可降低文盲患者的使用门槛。此外,该数据集支持构建语音到文本的翻译服务,促进政府公告、新闻播报等场景下的无障碍信息传播。其结构化设计(包含录音设备、领域标签等元数据)还便于开发者针对特定噪声环境或口音进行模型微调,显著提升了真实场景下的识别鲁棒性。
衍生相关工作
该数据集衍生了一系列低资源语言语音研究的经典工作。基于此数据,研究者提出了多任务学习框架,联合优化语音识别与语种识别,以增强模型对基库尤语与其他班图语系语言的区分能力。此外,有工作利用该数据集验证了无监督预训练(如wav2vec 2.0)在低资源场景下的有效性,显示其能显著降低对标注数据的依赖。另一些研究则聚焦于数据增强技术,通过速度扰动、频谱掩蔽等方法扩展训练规模,并探索了将基库尤语语音识别模型迁移至斯瓦希里语等相近语言的可能性,为跨语言语音系统的构建提供了可复现的基准。
以上内容由遇见数据集搜集并总结生成


