Salesforce/wikitext
收藏Hugging Face2024-01-04 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/Salesforce/wikitext
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- no-annotation
language_creators:
- crowdsourced
language:
- en
license:
- cc-by-sa-3.0
- gfdl
multilinguality:
- monolingual
size_categories:
- 1M<n<10M
source_datasets:
- original
task_categories:
- text-generation
- fill-mask
task_ids:
- language-modeling
- masked-language-modeling
paperswithcode_id: wikitext-2
pretty_name: WikiText
dataset_info:
- config_name: wikitext-103-raw-v1
features:
- name: text
dtype: string
splits:
- name: test
num_bytes: 1305088
num_examples: 4358
- name: train
num_bytes: 546500949
num_examples: 1801350
- name: validation
num_bytes: 1159288
num_examples: 3760
download_size: 315466397
dataset_size: 548965325
- config_name: wikitext-103-v1
features:
- name: text
dtype: string
splits:
- name: test
num_bytes: 1295575
num_examples: 4358
- name: train
num_bytes: 545141915
num_examples: 1801350
- name: validation
num_bytes: 1154751
num_examples: 3760
download_size: 313093838
dataset_size: 547592241
- config_name: wikitext-2-raw-v1
features:
- name: text
dtype: string
splits:
- name: test
num_bytes: 1305088
num_examples: 4358
- name: train
num_bytes: 11061717
num_examples: 36718
- name: validation
num_bytes: 1159288
num_examples: 3760
download_size: 7747362
dataset_size: 13526093
- config_name: wikitext-2-v1
features:
- name: text
dtype: string
splits:
- name: test
num_bytes: 1270947
num_examples: 4358
- name: train
num_bytes: 10918118
num_examples: 36718
- name: validation
num_bytes: 1134123
num_examples: 3760
download_size: 7371282
dataset_size: 13323188
configs:
- config_name: wikitext-103-raw-v1
data_files:
- split: test
path: wikitext-103-raw-v1/test-*
- split: train
path: wikitext-103-raw-v1/train-*
- split: validation
path: wikitext-103-raw-v1/validation-*
- config_name: wikitext-103-v1
data_files:
- split: test
path: wikitext-103-v1/test-*
- split: train
path: wikitext-103-v1/train-*
- split: validation
path: wikitext-103-v1/validation-*
- config_name: wikitext-2-raw-v1
data_files:
- split: test
path: wikitext-2-raw-v1/test-*
- split: train
path: wikitext-2-raw-v1/train-*
- split: validation
path: wikitext-2-raw-v1/validation-*
- config_name: wikitext-2-v1
data_files:
- split: test
path: wikitext-2-v1/test-*
- split: train
path: wikitext-2-v1/train-*
- split: validation
path: wikitext-2-v1/validation-*
---
# Dataset Card for "wikitext"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://blog.einstein.ai/the-wikitext-long-term-dependency-language-modeling-dataset/](https://blog.einstein.ai/the-wikitext-long-term-dependency-language-modeling-dataset/)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [Pointer Sentinel Mixture Models](https://arxiv.org/abs/1609.07843)
- **Point of Contact:** [Stephen Merity](mailto:smerity@salesforce.com)
- **Size of downloaded dataset files:** 391.41 MB
- **Size of the generated dataset:** 1.12 GB
- **Total amount of disk used:** 1.52 GB
### Dataset Summary
The WikiText language modeling dataset is a collection of over 100 million tokens extracted from the set of verified
Good and Featured articles on Wikipedia. The dataset is available under the Creative Commons Attribution-ShareAlike License.
Compared to the preprocessed version of Penn Treebank (PTB), WikiText-2 is over 2 times larger and WikiText-103 is over
110 times larger. The WikiText dataset also features a far larger vocabulary and retains the original case, punctuation
and numbers - all of which are removed in PTB. As it is composed of full articles, the dataset is well suited for models
that can take advantage of long term dependencies.
Each subset comes in two different variants:
- Raw (for character level work) contain the raw tokens, before the addition of the <unk> (unknown) tokens.
- Non-raw (for word level work) contain only the tokens in their vocabulary (wiki.train.tokens, wiki.valid.tokens, and wiki.test.tokens).
The out-of-vocabulary tokens have been replaced with the the <unk> token.
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### wikitext-103-raw-v1
- **Size of downloaded dataset files:** 191.98 MB
- **Size of the generated dataset:** 549.42 MB
- **Total amount of disk used:** 741.41 MB
An example of 'validation' looks as follows.
```
This example was too long and was cropped:
{
"text": "\" The gold dollar or gold one @-@ dollar piece was a coin struck as a regular issue by the United States Bureau of the Mint from..."
}
```
#### wikitext-103-v1
- **Size of downloaded dataset files:** 190.23 MB
- **Size of the generated dataset:** 548.05 MB
- **Total amount of disk used:** 738.27 MB
An example of 'train' looks as follows.
```
This example was too long and was cropped:
{
"text": "\" Senjō no Valkyria 3 : <unk> Chronicles ( Japanese : 戦場のヴァルキュリア3 , lit . Valkyria of the Battlefield 3 ) , commonly referred to..."
}
```
#### wikitext-2-raw-v1
- **Size of downloaded dataset files:** 4.72 MB
- **Size of the generated dataset:** 13.54 MB
- **Total amount of disk used:** 18.26 MB
An example of 'train' looks as follows.
```
This example was too long and was cropped:
{
"text": "\" The Sinclair Scientific Programmable was introduced in 1975 , with the same case as the Sinclair Oxford . It was larger than t..."
}
```
#### wikitext-2-v1
- **Size of downloaded dataset files:** 4.48 MB
- **Size of the generated dataset:** 13.34 MB
- **Total amount of disk used:** 17.82 MB
An example of 'train' looks as follows.
```
This example was too long and was cropped:
{
"text": "\" Senjō no Valkyria 3 : <unk> Chronicles ( Japanese : 戦場のヴァルキュリア3 , lit . Valkyria of the Battlefield 3 ) , commonly referred to..."
}
```
### Data Fields
The data fields are the same among all splits.
#### wikitext-103-raw-v1
- `text`: a `string` feature.
#### wikitext-103-v1
- `text`: a `string` feature.
#### wikitext-2-raw-v1
- `text`: a `string` feature.
#### wikitext-2-v1
- `text`: a `string` feature.
### Data Splits
| name | train |validation|test|
|-------------------|------:|---------:|---:|
|wikitext-103-raw-v1|1801350| 3760|4358|
|wikitext-103-v1 |1801350| 3760|4358|
|wikitext-2-raw-v1 | 36718| 3760|4358|
|wikitext-2-v1 | 36718| 3760|4358|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
The dataset is available under the [Creative Commons Attribution-ShareAlike License (CC BY-SA 4.0)](https://creativecommons.org/licenses/by-sa/4.0/).
### Citation Information
```
@misc{merity2016pointer,
title={Pointer Sentinel Mixture Models},
author={Stephen Merity and Caiming Xiong and James Bradbury and Richard Socher},
year={2016},
eprint={1609.07843},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Contributions
Thanks to [@thomwolf](https://github.com/thomwolf), [@lewtun](https://github.com/lewtun), [@patrickvonplaten](https://github.com/patrickvonplaten), [@mariamabarham](https://github.com/mariamabarham) for adding this dataset.
annotations_creators:
- 无标注
language_creators:
- 众包
language:
- en
license:
- CC BY-SA 3.0 (cc-by-sa-3.0)
- GNU自由文档许可证(GFDL)
multilinguality:
- 单语言
size_categories:
- 100万 < 样本数 < 1000万
source_datasets:
- 原始数据集
task_categories:
- 文本生成
- 掩码填充
task_ids:
- 语言建模
- 掩码语言建模
paperswithcode_id: wikitext-2
pretty_name: WikiText
dataset_info:
- config_name: wikitext-103-raw-v1
features:
- name: text
dtype: string
splits:
- name: test
num_bytes: 1305088
num_examples: 4358
- name: train
num_bytes: 546500949
num_examples: 1801350
- name: validation
num_bytes: 1159288
num_examples: 3760
download_size: 315466397
dataset_size: 548965325
- config_name: wikitext-103-v1
features:
- name: text
dtype: string
splits:
- name: test
num_bytes: 1295575
num_examples: 4358
- name: train
num_bytes: 545141915
num_examples: 1801350
- name: validation
num_bytes: 1154751
num_examples: 3760
download_size: 313093838
dataset_size: 547592241
- config_name: wikitext-2-raw-v1
features:
- name: text
dtype: string
splits:
- name: test
num_bytes: 1305088
num_examples: 4358
- name: train
num_bytes: 11061717
num_examples: 36718
- name: validation
num_bytes: 1159288
num_examples: 3760
download_size: 7747362
dataset_size: 13526093
- config_name: wikitext-2-v1
features:
- name: text
dtype: string
splits:
- name: test
num_bytes: 1270947
num_examples: 4358
- name: train
num_bytes: 10918118
num_examples: 36718
- name: validation
num_bytes: 1134123
num_examples: 3760
download_size: 7371282
dataset_size: 13323188
configs:
- config_name: wikitext-103-raw-v1
data_files:
- split: test
path: wikitext-103-raw-v1/test-*
- split: train
path: wikitext-103-raw-v1/train-*
- split: validation
path: wikitext-103-raw-v1/validation-*
- config_name: wikitext-103-v1
data_files:
- split: test
path: wikitext-103-v1/test-*
- split: train
path: wikitext-103-v1/train-*
- split: validation
path: wikitext-103-v1/validation-*
- config_name: wikitext-2-raw-v1
data_files:
- split: test
path: wikitext-2-raw-v1/test-*
- split: train
path: wikitext-2-raw-v1/train-*
- split: validation
path: wikitext-2-raw-v1/validation-*
- config_name: wikitext-2-v1
data_files:
- split: test
path: wikitext-2-v1/test-*
- split: train
path: wikitext-2-v1/train-*
- split: validation
path: wikitext-2-v1/validation-*
# "WikiText" 数据集卡片
## 目录
- [数据集描述](#dataset-description)
- [数据集概述](#dataset-summary)
- [支持的任务与基准测试榜](#supported-tasks-and-leaderboards)
- [语言](#languages)
- [数据集结构](#dataset-structure)
- [数据实例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集创建](#dataset-creation)
- [数据集构建依据](#curation-rationale)
- [源数据](#source-data)
- [标注信息](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据集使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏差讨论](#discussion-of-biases)
- [其他已知局限性](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集整理者](#dataset-curators)
- [许可证信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献致谢](#contributions)
## 数据集描述
- **主页**:[https://blog.einstein.ai/the-wikitext-long-term-dependency-language-modeling-dataset/](https://blog.einstein.ai/the-wikitext-long-term-dependency-language-modeling-dataset/)
- **代码仓库**:[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **相关论文**:[Pointer Sentinel Mixture Models](https://arxiv.org/abs/1609.07843)
- **联系人**:[Stephen Merity](mailto:smerity@salesforce.com)
- **下载数据集文件大小**:391.41 MB
- **生成的数据集大小**:1.12 GB
- **占用总磁盘空间**:1.52 GB
### 数据集概述
WikiText语言建模数据集是从维基百科已验证的优质(Good)与特色(Featured)文章集中提取的超过1亿个Token的集合,该数据集采用知识共享署名-相同方式共享协议发布。
相较于预处理后的宾夕法尼亚树库(Penn Treebank,PTB),WikiText-2的规模是其2倍以上,而WikiText-103的规模更是其110倍以上。该数据集拥有更大的词表,且保留了原始的大小写、标点符号与数字——而这些内容在PTB中均被移除。由于该数据集由完整的文章构成,因此非常适合能够利用长期依赖关系的模型。
每个子集均包含两种变体:
- 原始版(适用于字符级任务):保留添加<unk>(未知标记)之前的原始Token。
- 非原始版(适用于词级任务):仅包含词表中的Token(对应文件为wiki.train.tokens、wiki.valid.tokens与wiki.test.tokens),其中未登录词(out-of-vocabulary, OOV)已被替换为<unk>标记。
### 支持的任务与基准测试榜
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 语言
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据集结构
### 数据实例
#### wikitext-103-raw-v1
- **下载数据集文件大小**:191.98 MB
- **生成的数据集大小**:549.42 MB
- **占用总磁盘空间**:741.41 MB
"验证集"的一条示例如下:
This example was too long and was cropped:
{
"text": "" The gold dollar or gold one @-@ dollar piece was a coin struck as a regular issue by the United States Bureau of the Mint from..."
}
#### wikitext-103-v1
- **下载数据集文件大小**:190.23 MB
- **生成的数据集大小**:548.05 MB
- **占用总磁盘空间**:738.27 MB
"训练集"的一条示例如下:
This example was too long and was cropped:
{
"text": "" Senjō no Valkyria 3 : <unk> Chronicles ( Japanese : 戦場のヴァルキュリア3 , lit . Valkyria of the Battlefield 3 ) , commonly referred to..."
}
#### wikitext-2-raw-v1
- **下载数据集文件大小**:4.72 MB
- **生成的数据集大小**:13.54 MB
- **占用总磁盘空间**:18.26 MB
"训练集"的一条示例如下:
This example was too long and was cropped:
{
"text": "" The Sinclair Scientific Programmable was introduced in 1975 , with the same case as the Sinclair Oxford . It was larger than t..."
}
#### wikitext-2-v1
- **下载数据集文件大小**:4.48 MB
- **生成的数据集大小**:13.34 MB
- **占用总磁盘空间**:17.82 MB
"训练集"的一条示例如下:
This example was too long and was cropped:
{
"text": "" Senjō no Valkyria 3 : <unk> Chronicles ( Japanese : 戦場のヴァルキュリア3 , lit . Valkyria of the Battlefield 3 ) , commonly referred to..."
}
### 数据字段
所有划分下的数据字段均保持一致。
#### wikitext-103-raw-v1
- `text`:字符串类型特征。
#### wikitext-103-v1
- `text`:字符串类型特征。
#### wikitext-2-raw-v1
- `text`:字符串类型特征。
#### wikitext-2-v1
- `text`:字符串类型特征。
### 数据划分
| 名称 | 训练集 | 验证集 | 测试集 |
|-------------------|---------:|--------:|-------:|
|wikitext-103-raw-v1| 1801350 | 3760| 4358|
|wikitext-103-v1 | 1801350 | 3760| 4358|
|wikitext-2-raw-v1 | 36718 | 3760| 4358|
|wikitext-2-v1 | 36718 | 3760| 4358|
## 数据集创建
### 数据集构建依据
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 源数据
#### 初始数据收集与标准化
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 源语言生产者是谁?
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 标注信息
#### 标注流程
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 标注者是谁?
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 个人与敏感信息
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据集使用注意事项
### 数据集的社会影响
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 偏差讨论
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 其他已知局限性
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 附加信息
### 数据集整理者
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 许可证信息
本数据集采用[知识共享署名-相同方式共享4.0协议(CC BY-SA 4.0)](https://creativecommons.org/licenses/by-sa/4.0/)发布。
### 引用信息
@misc{merity2016pointer,
title={Pointer Sentinel Mixture Models},
author={Stephen Merity and Caiming Xiong and James Bradbury and Richard Socher},
year={2016},
eprint={1609.07843},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
### 贡献致谢
感谢[@thomwolf](https://github.com/thomwolf)、[@lewtun](https://github.com/lewtun)、[@patrickvonplaten](https://github.com/patrickvonplaten)与[@mariamabarham](https://github.com/mariamabarham)为本数据集的添加所做的贡献。
提供机构:
Salesforce
原始信息汇总
数据集概述
基本信息
- 数据集名称: WikiText
- 语言: 英语
- 许可证: CC BY-SA 3.0 和 GFDL
- 多语言性: 单语种
- 数据集大小: 1M<n<10M
- 源数据: 原始数据
- 任务类别: 文本生成、填充掩码
- 任务ID: 语言建模、掩码语言建模
- 论文ID: wikitext-2
数据集配置
wikitext-103-raw-v1
- 特征:
text: 字符串类型
- 分割:
test: 1305088 字节, 4358 样本train: 546500949 字节, 1801350 样本validation: 1159288 字节, 3760 样本
- 下载大小: 315466397 字节
- 数据集大小: 548965325 字节
wikitext-103-v1
- 特征:
text: 字符串类型
- 分割:
test: 1295575 字节, 4358 样本train: 545141915 字节, 1801350 样本validation: 1154751 字节, 3760 样本
- 下载大小: 313093838 字节
- 数据集大小: 547592241 字节
wikitext-2-raw-v1
- 特征:
text: 字符串类型
- 分割:
test: 1305088 字节, 4358 样本train: 11061717 字节, 36718 样本validation: 1159288 字节, 3760 样本
- 下载大小: 7747362 字节
- 数据集大小: 13526093 字节
wikitext-2-v1
- 特征:
text: 字符串类型
- 分割:
test: 1270947 字节, 4358 样本train: 10918118 字节, 36718 样本validation: 1134123 字节, 3760 样本
- 下载大小: 7371282 字节
- 数据集大小: 13323188 字节
数据集结构
数据实例
-
wikitext-103-raw-v1:
validation示例: json { "text": "" The gold dollar or gold one @-@ dollar piece was a coin struck as a regular issue by the United States Bureau of the Mint from..." }
-
wikitext-103-v1:
train示例: json { "text": "" Senjō no Valkyria 3 : <unk> Chronicles ( Japanese : 戦場のヴァルキュリア3 , lit . Valkyria of the Battlefield 3 ) , commonly referred to..." }
-
wikitext-2-raw-v1:
train示例: json { "text": "" The Sinclair Scientific Programmable was introduced in 1975 , with the same case as the Sinclair Oxford . It was larger than t..." }
-
wikitext-2-v1:
train示例: json { "text": "" Senjō no Valkyria 3 : <unk> Chronicles ( Japanese : 戦場のヴァルキュリア3 , lit . Valkyria of the Battlefield 3 ) , commonly referred to..." }
数据字段
- wikitext-103-raw-v1:
text: 字符串类型
- wikitext-103-v1:
text: 字符串类型
- wikitext-2-raw-v1:
text: 字符串类型
- wikitext-2-v1:
text: 字符串类型
数据分割
| name | train | validation | test |
|---|---|---|---|
| wikitext-103-raw-v1 | 1801350 | 3760 | 4358 |
| wikitext-103-v1 | 1801350 | 3760 | 4358 |
| wikitext-2-raw-v1 | 36718 | 3760 | 4358 |
| wikitext-2-v1 | 36718 | 3760 | 4358 |
搜集汇总
数据集介绍
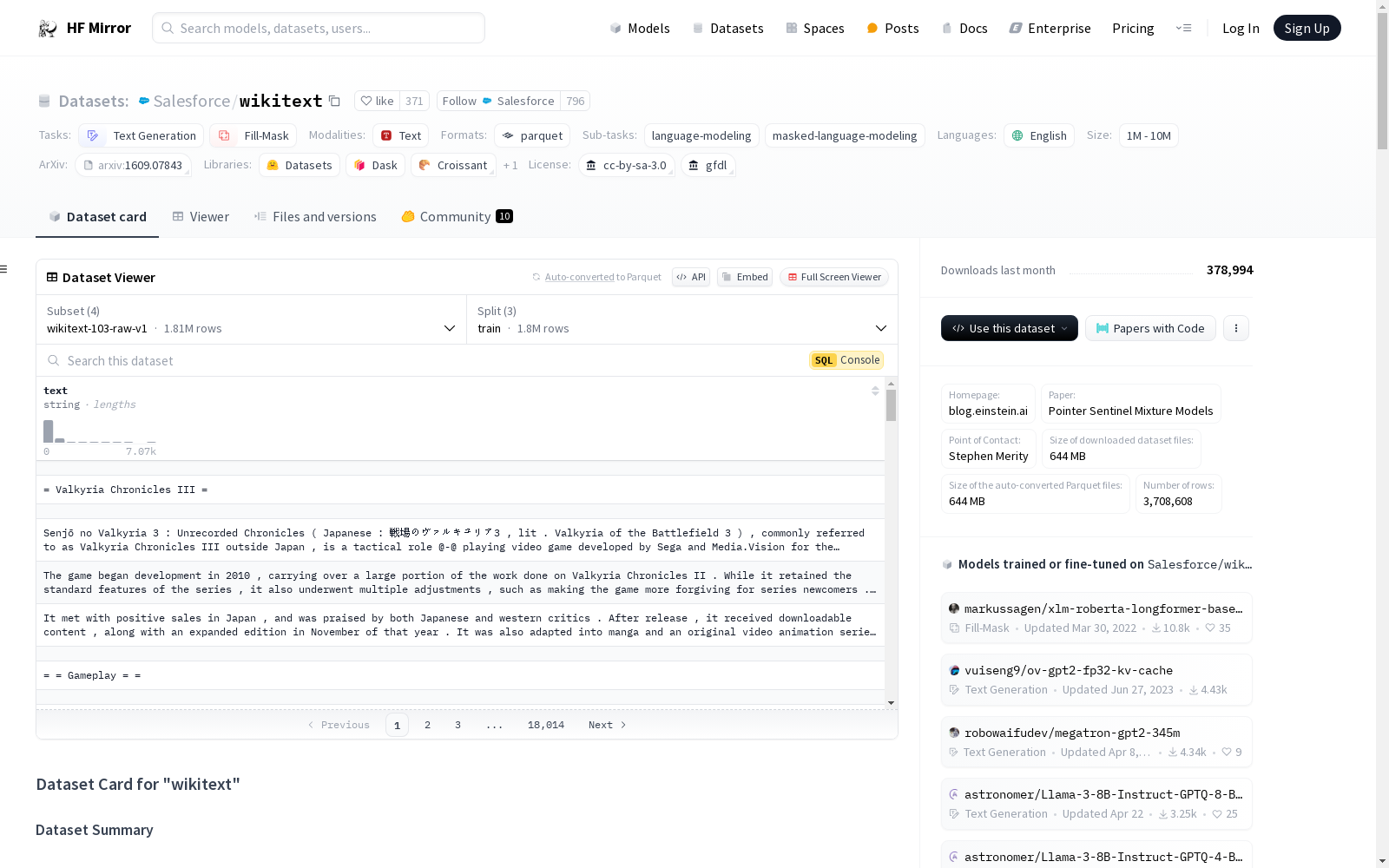
构建方式
WikiText数据集的构建基于维基百科上经过验证的优质和特色文章,通过众包方式收集了超过1亿个词汇。该数据集分为两个主要版本:原始版本(raw)和非原始版本(non-raw)。原始版本保留了原始的标点符号、大小写和数字,而非原始版本则将词汇表外的词汇替换为<unk>标记。这种设计旨在为语言模型提供丰富的上下文信息和长程依赖关系,同时支持字符级和词汇级的工作。
使用方法
使用WikiText数据集时,用户可以根据需求选择不同的配置版本(如wikitext-103-raw-v1或wikitext-2-v1)。数据集的加载和处理可以通过HuggingFace的datasets库轻松实现。用户可以利用该数据集进行文本生成、掩码语言建模等任务。具体操作包括加载数据集、划分数据集、以及根据任务需求进行预处理和模型训练。数据集的灵活性和多样性使其适用于多种自然语言处理任务的研究和应用。
背景与挑战
背景概述
WikiText数据集是由Salesforce的研究团队创建,旨在为语言建模任务提供一个大规模、高质量的文本资源。该数据集于2016年首次发布,主要研究人员包括Stephen Merity、Caiming Xiong、James Bradbury和Richard Socher。WikiText的核心研究问题是如何在保留原始文本特征的同时,提供一个适用于长程依赖建模的语料库。相较于传统的Penn Treebank数据集,WikiText-2的规模是其两倍,而WikiText-103则超过110倍。这一数据集的推出,极大地推动了自然语言处理领域中长文本建模技术的发展,尤其是在处理复杂语言结构和上下文依赖方面。
当前挑战
尽管WikiText数据集在规模和质量上具有显著优势,但其构建过程中仍面临诸多挑战。首先,数据集的原始文本来自Wikipedia,如何从海量内容中筛选出高质量的文章并进行有效处理,是一个复杂的过程。其次,保留原始文本的标点符号、大小写和数字等特征,虽然增加了数据的真实性,但也增加了模型处理的难度。此外,数据集的多样性可能导致模型在处理特定领域文本时表现不佳,这需要在模型训练和评估时加以考虑。最后,数据集的版权问题和使用限制,也对其广泛应用提出了一定的挑战。
常用场景
经典使用场景
在自然语言处理领域,WikiText数据集被广泛用于语言模型的训练与评估。其丰富的文本内容和多样化的词汇,使得该数据集成为研究长程依赖性和上下文理解的重要资源。研究者们利用WikiText进行文本生成和掩码语言建模,以提升模型在处理复杂语言结构和生成连贯文本方面的能力。
解决学术问题
WikiText数据集解决了传统语言模型数据集(如Penn Treebank)在词汇量和文本复杂性方面的局限。通过提供大量未经处理的原始文本,WikiText使得研究者能够更真实地模拟自然语言环境,从而推动了语言模型在处理长文本和复杂语境方面的研究进展。
实际应用
在实际应用中,基于WikiText训练的语言模型被广泛应用于自动文本生成、机器翻译和智能问答系统等领域。这些模型能够生成高质量的文本内容,提升用户体验,并在多种自然语言处理任务中展现出优越的性能。
数据集最近研究
最新研究方向
在自然语言处理领域,WikiText数据集因其丰富的文本内容和广泛的应用场景而备受关注。最新研究方向主要集中在利用该数据集进行大规模语言模型的预训练和微调,以提升模型在长文本生成和掩码语言建模任务中的表现。此外,研究者们还探索了如何通过引入更多的上下文信息和多任务学习策略,进一步增强模型的语义理解和生成能力。这些研究不仅推动了语言模型性能的提升,也为相关领域的应用提供了更为坚实的基础。
以上内容由遇见数据集搜集并总结生成


