---
task_categories:
- question-answering
language:
- en
size_categories:
- 10K<n<100K
---
# Natural Questions Open Dataset with Gold Documents
This dataset is a curated version of the [Natural Questions open dataset](https://huggingface.co/datasets/nq_open),
with the inclusion of the gold documents from the original [Natural Questions](https://huggingface.co/datasets/natural_questions) (NQ) dataset.
The main difference with the NQ-open dataset is that some entries were excluded, as their respective gold documents exceeded 512 tokens in length.
This is due to the pre-processing of the gold documents, as detailed in this related [dataset](https://huggingface.co/datasets/florin-hf/wiki_dump2018_nq_open).
The dataset is designed to facilitate research in question-answering systems, especially focusing on integrating gold documents for training and testing purposes.
## Dataset Sources
The Natural Questions (NQ) dataset is a large-scale collection of real-world queries derived from Google search data. Each
entry in the dataset consists of a user query and the corresponding Wikipedia page containing the answer.
The NQ-open dataset, a subset of the NQ dataset, differs by removing the restriction of linking answers to specific Wikipedia passages, thereby
mimicking a more general information retrieval scenario similar to web searches.
This version of the NQ-open dataset was used in the paper [The Power of Noise: Redefining Retrieval for RAG Systems](https://arxiv.org/abs/2401.14887).
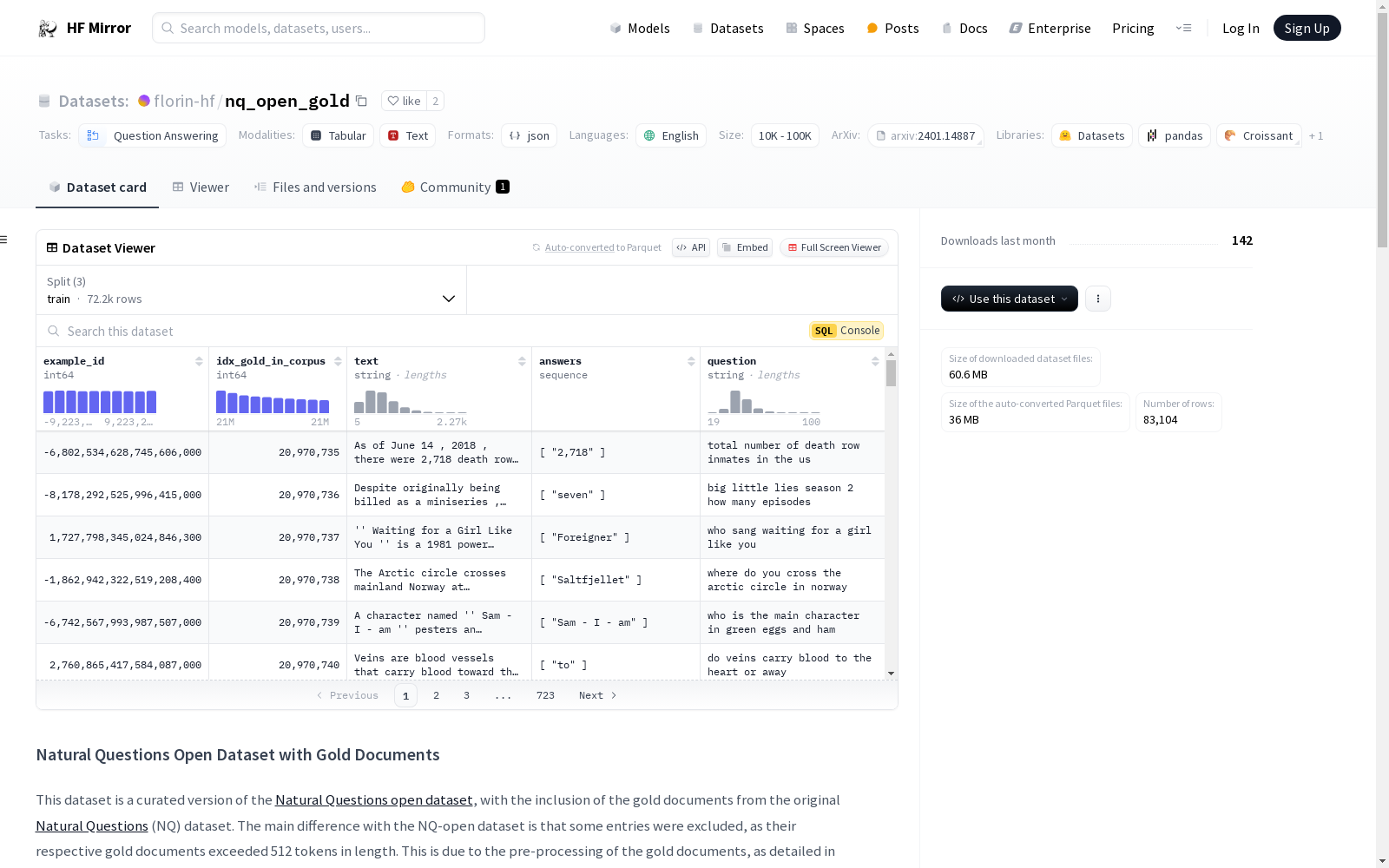
## Dataset Structure
A sample in the dataset has the following format:
```
{
'example_id' (int64): an identifier for the question, consistent with the original NQ dataset,
'question' (str): a question, that is identical to the question in the original NQ,
'answers' (List[str]): the list of correct answers in the original NQ,
'text' (str): gold document, associated with the question, in the original NQ,
'idx_gold_in_corpus' (int64): index of the gold document in the full corpus.
}
Ex.
{
'example_id': -3440030035760311385,
'question': 'who owned the millennium falcon before han solo',
'answers': [Lando Calrissian],
'text': "Han Solo won the Millennium Falcon from Lando Calrissian in the card game ' sabacc ' several years before the events of the film A New Hope..."
'idx_gold_in_corpus': 20995349
}
```
## Dataset Splits
- **Train set**: 72,209 (50,2 MB)
- **Validation set**: 8,006 (5,57 BM)
- **Test set**: 2889 (1,96 MB)
## Citation Information
```
@article{doi:10.1162/tacl\_a\_00276,
author = {Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and Toutanova, Kristina and Jones, Llion and Kelcey, Matthew and Chang, Ming-Wei and Dai, Andrew M. and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav},
title = {Natural Questions: A Benchmark for Question Answering Research},
journal = {Transactions of the Association for Computational Linguistics},
volume = {7},
number = {},
pages = {453-466},
year = {2019},
doi = {10.1162/tacl\_a\_00276},
URL = {
https://doi.org/10.1162/tacl_a_00276
},
eprint = {
https://doi.org/10.1162/tacl_a_00276
},
abstract = { We present the Natural Questions corpus, a question answering data set. Questions consist of real anonymized, aggregated queries issued to the Google search engine. An annotator is presented with a question along with a Wikipedia page from the top 5 search results, and annotates a long answer (typically a paragraph) and a short answer (one or more entities) if present on the page, or marks null if no long/short answer is present. The public release consists of 307,373 training examples with single annotations; 7,830 examples with 5-way annotations for development data; and a further 7,842 examples with 5-way annotated sequestered as test data. We present experiments validating quality of the data. We also describe analysis of 25-way annotations on 302 examples, giving insights into human variability on the annotation task. We introduce robust metrics for the purposes of evaluating question answering systems; demonstrate high human upper bounds on these metrics; and establish baseline results using competitive methods drawn from related literature. }
}
@inproceedings{lee-etal-2019-latent,
title = "Latent Retrieval for Weakly Supervised Open Domain Question Answering",
author = "Lee, Kenton and
Chang, Ming-Wei and
Toutanova, Kristina",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P19-1612",
doi = "10.18653/v1/P19-1612",
pages = "6086--6096",
abstract = "Recent work on open domain question answering (QA) assumes strong supervision of the supporting evidence and/or assumes a blackbox information retrieval (IR) system to retrieve evidence candidates. We argue that both are suboptimal, since gold evidence is not always available, and QA is fundamentally different from IR. We show for the first time that it is possible to jointly learn the retriever and reader from question-answer string pairs and without any IR system. In this setting, evidence retrieval from all of Wikipedia is treated as a latent variable. Since this is impractical to learn from scratch, we pre-train the retriever with an Inverse Cloze Task. We evaluate on open versions of five QA datasets. On datasets where the questioner already knows the answer, a traditional IR system such as BM25 is sufficient. On datasets where a user is genuinely seeking an answer, we show that learned retrieval is crucial, outperforming BM25 by up to 19 points in exact match.",
}
@misc{cuconasu2024power,
title={The Power of Noise: Redefining Retrieval for RAG Systems},
author={Florin Cuconasu and Giovanni Trappolini and Federico Siciliano and Simone Filice and Cesare Campagnano and Yoelle Maarek and Nicola Tonellotto and Fabrizio Silvestri},
year={2024},
eprint={2401.14887},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
```
---
任务类别:
- 问答任务
语言:
- 英语
数据规模:
- 10K<n<100K
---
# 带黄金文档的自然问题开放数据集
本数据集是[自然问题开放数据集](https://huggingface.co/datasets/nq_open)的精选版本,额外纳入了原始[自然问题(Natural Questions)](https://huggingface.co/datasets/natural_questions)(下称NQ)数据集的黄金文档。与NQ-open数据集的核心差异在于:本数据集剔除了部分条目,原因是其对应黄金文档的Token长度超过512。该预处理规则详见相关数据集[wiki_dump2018_nq_open](https://huggingface.co/datasets/florin-hf/wiki_dump2018_nq_open)。
本数据集旨在推动问答系统的相关研究,尤其聚焦于在训练与测试环节集成黄金文档的应用场景。
## 数据集来源
自然问题(Natural Questions)数据集是基于谷歌搜索数据构建的大规模真实查询集合,数据集中的每条条目均包含用户查询与包含答案的对应维基百科页面。
NQ-open数据集作为NQ数据集的子集,移除了将答案绑定至特定维基百科段落的限制,从而更贴近类似网页搜索的通用信息检索场景。
本版本的NQ-open数据集曾被用于论文《[噪声的力量:重新定义RAG系统的检索范式](https://arxiv.org/abs/2401.14887)》。
## 数据集结构
本数据集的样本格式如下:
{
'example_id' (int64): 问题标识符,与原始NQ数据集保持一致,
'question' (str): 与原始NQ数据集完全一致的用户查询,
'answers' (List[str]): 原始NQ数据集中的正确答案列表,
'text' (str): 原始NQ数据集中与该问题关联的黄金文档,
'idx_gold_in_corpus' (int64): 黄金文档在全语料库中的索引。
}
示例:
{
'example_id': -3440030035760311385,
'question': '汉·索罗之前谁拥有千年隼号',
'answers': ['兰多·卡瑞辛'],
'text': "汉·索罗在《新希望》电影剧情发生数年前的萨巴克纸牌游戏中,从兰多·卡瑞辛手中赢得了千年隼号……",
'idx_gold_in_corpus': 20995349
}
## 数据集划分
- **训练集**:72209条(50.2 MB)
- **验证集**:8006条(5.57 MB)
- **测试集**:2889条(1.96 MB)
## 引用信息
@article{doi:10.1162/tacl\_a\_00276,
作者:Kwiatkowski, Tom 与 Palomaki, Jennimaria 及 Redfield, Olivia 等,
标题:《自然问题:问答研究的基准测试集》,
期刊:《计算语言学协会会刊》,
卷:7,
页码:453-466,
年份:2019,
DOI:10.1162/tacl\_a\_00276,
URL:https://doi.org/10.1162/tacl_a_00276,
摘要:本文提出自然问题语料库,一款问答数据集。数据集的问题均来自谷歌搜索引擎的真实匿名聚合查询。标注人员将收到一则查询与搜索结果前五名对应的维基百科页面,随后标注长答案(通常为段落)与短答案(一个或多个实体,若页面中存在);若无对应答案,则标记为空。公开版本包含307373条带单标注的训练样本、7830条带五重标注的开发样本,以及7842条带五重标注的封存测试样本。本文验证了该数据集的质量,同时分析了302个样本的25重标注结果,以洞察标注任务中的人类标注差异。本文还提出了用于评估问答系统的鲁棒性指标,证明了这些指标上的高人类上限,并通过相关文献中的竞争方法建立了基准结果。
}
@inproceedings{lee-etal-2019-latent,
标题:《弱监督开放域问答的隐式检索》,
作者:Lee, Kenton 与 Chang, Ming-Wei 及 Toutanova, Kristina,
会议:《第57届计算语言学协会年会论文集》,
月份:7月,
年份:2019,
地点:意大利佛罗伦萨,
出版社:计算语言学协会,
URL:https://www.aclweb.org/anthology/P19-1612,
DOI:10.18653/v1/P19-1612,
页码:6086-6096,
摘要:近期开放域问答(QA)研究通常假设对支撑证据拥有强监督,或依赖黑箱信息检索(IR)系统获取候选证据。本文指出这两种方案均非最优,因为黄金证据并非始终可用,且问答任务本质上不同于信息检索。本文首次证明,无需任何IR系统,仅通过问答字符串对即可联合学习检索器与阅读器。在此设定下,从全维基百科中检索证据被视为隐变量。由于从零开始学习该任务不切实际,本文通过逆完形任务预训练检索器。本文在五个QA数据集的开放版本上进行了评估。在提问者已知答案的数据集上,传统IR系统(如BM25)即可满足需求;而在用户真正寻求答案的数据集上,本文证明学习到的检索器至关重要,其精确匹配性能比BM25高出最高19个百分点。
}
@misc{cuconasu2024power,
标题:《噪声的力量:重新定义RAG系统的检索范式》,
作者:Florin Cuconasu 与 Giovanni Trappolini 及 Federico Siciliano 等,
年份:2024,
arXiv编号:2401.14887,
预印本平台:arXiv,
分类:cs.IR
}