SlovKE
收藏arXiv2026-03-17 更新2026-03-18 收录
下载链接:
https://huggingface.co/datasets/NaiveNeuron/SlovKE
下载链接
链接失效反馈官方服务:
资源简介:
SlovKE是由NaiveNeuron等机构联合构建的斯洛伐克语关键词提取基准数据集,包含22.7万篇经过系统清洗的科学摘要及作者标注的关键短语,规模达到先前最大斯洛伐克语资源的25倍。数据集源自斯洛伐克中央论文注册系统,通过多阶段清洗流程去除重复记录、混合语言内容和不一致元数据,最终保留50-2000字符的摘要和4-15个关键短语。该数据集支持形态复杂语言的关键词提取研究,特别针对低资源斯拉夫语系语言中词形变化导致的表面形式与规范短语不匹配问题,为无监督方法和LLM模型提供了重要评估基准。
提供机构:
维也纳大学; 夸美纽斯大学·数学、物理与信息学院; 思科系统公司; NaiveNeuron
创建时间:
2026-03-17
原始信息汇总
数据集概述
基本信息
- 数据集名称:SlovKE
- 托管平台:Hugging Face
- 发布者:NaiveNeuron
- 许可证:cc-by-nc-4.0(知识共享署名-非商业性使用 4.0 国际许可协议)
许可证说明
- 本数据集采用知识共享署名-非商业性使用 4.0 国际许可协议(CC BY-NC 4.0)进行授权。
- 使用者可以自由地共享、改编本数据集,但必须给出适当的署名,且不得将本数据集用于商业目的。
搜集汇总
数据集介绍
构建方式
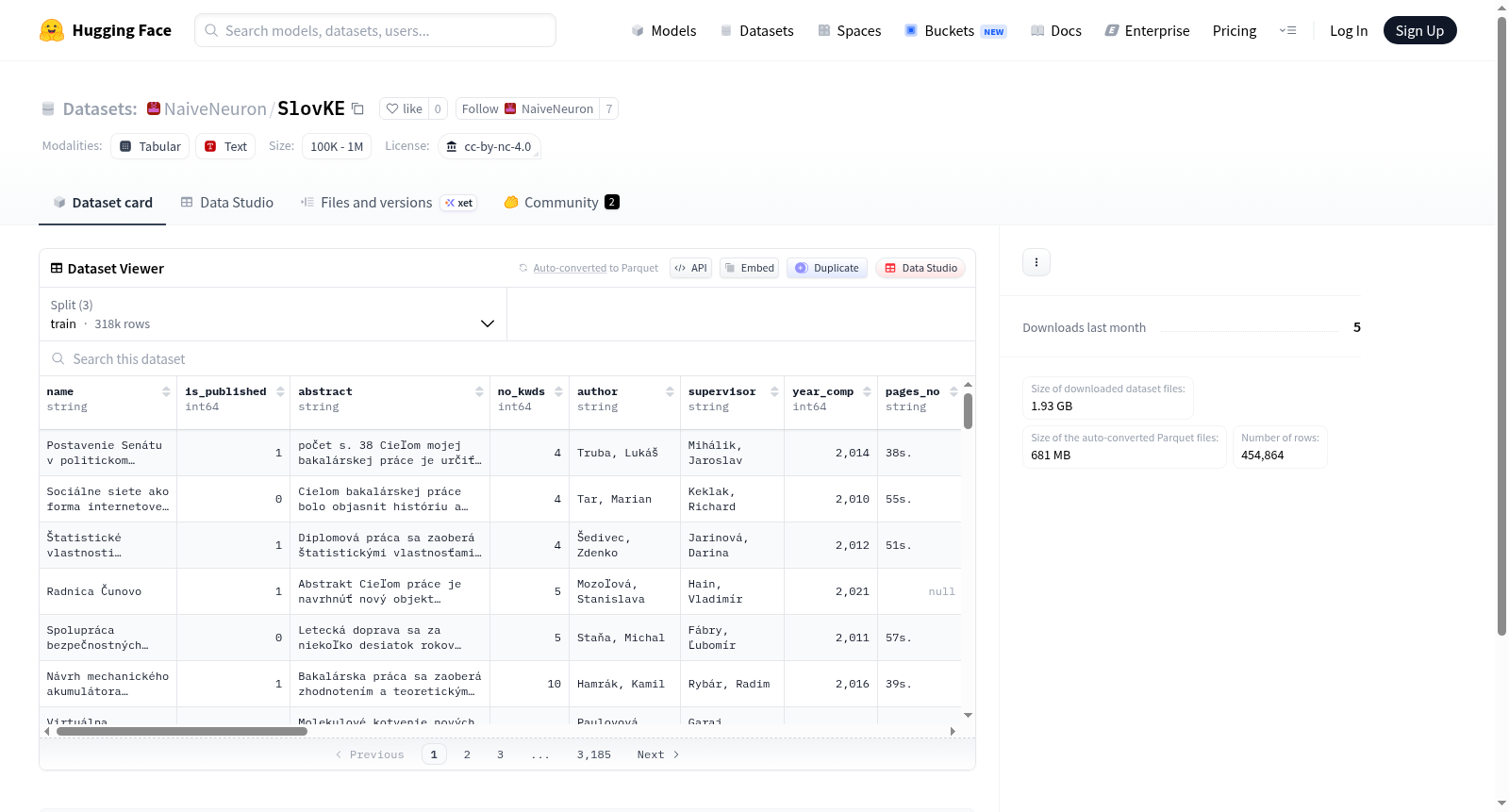
在形态丰富且资源匮乏的语言研究领域,构建高质量的关键词提取数据集面临显著挑战。SlovKE数据集通过系统化流程从斯洛伐克中央论文注册库中收集了793,722条记录,并实施了多阶段清洗策略以提升数据质量。具体步骤包括去除重复记录、修复因大学字段缺失而附加在摘要末尾的关键词、清除摘要中的噪声元数据(如作者姓名和论文类型),以及利用语言检测库识别并过滤非斯洛伐克语内容。此外,通过词性标注工具对关键词进行规范化处理,分割连缀列表并限制关键词最大长度为四个单词,最终基于长度和关键词数量筛选,得到包含227,432条科学摘要的洁净数据集。
特点
SlovKE数据集在规模与结构上呈现出显著特点,其文档数量达到227,432条,相较于先前最大的斯洛伐克语资源扩大了25倍,规模接近英语基准数据集KP20K。该数据集涵盖了丰富的学术摘要,平均每篇摘要包含约134个单词和5个作者标注的关键词,其中37%的关键词在文本中未直接出现,这一比例与英语数据集相近,表明其适用于跨语言关键词生成任务的评估。数据集中的关键词以单双词组合为主,体现了形态丰富语言中词形变化的复杂性,为研究表层形式与规范形式之间的不匹配问题提供了实证基础。
使用方法
该数据集支持无监督与基于大语言模型的关键词提取方法评估,用户可按照公开提供的训练、验证和测试划分进行实验。研究人员能够利用数据集比较统计方法(如YAKE)、图模型(如TextRank)以及嵌入模型(如KeyBERT)在精确匹配和部分匹配指标上的性能差异,从而量化形态变化对评估结果的影响。同时,数据集适用于评估生成式方法(如KeyLLM),探究其生成规范形式关键词的能力。通过结合自动评估与人工评估,用户可深入分析模型在形态丰富语言中的失败模式,并为开发形态感知的评估协议提供数据支持。
背景与挑战
背景概述
在自然语言处理领域,关键词提取作为文档主题表征的核心任务,对于科学文献的发现与分类至关重要。然而,针对形态丰富且资源匮乏的语言,如斯洛伐克语,相关研究长期面临数据稀缺的制约。为填补这一空白,David Števaňák与Marek Šuppa等研究人员于2024年构建了SlovKE数据集,该数据集从斯洛伐克中央论文注册系统中爬取并系统清洗了227,432篇科学摘要及其作者标注的关键词,规模较先前最大的斯洛伐克语资源扩大了25倍,并接近KP20K等英语基准数据集的体量。SlovKE的创建不仅为斯洛伐克语关键词提取提供了首个大规模评估基准,也为形态丰富语言的NLP研究奠定了重要的数据基础,推动了跨语言模型与方法的发展。
当前挑战
SlovKE数据集旨在解决形态丰富低资源语言中关键词提取的评估难题,其核心挑战在于如何准确匹配文本中屈折变化的表面形式与作者标注的规范形式。传统抽取式方法如YAKE、TextRank和KeyBERT在精确匹配上面临显著困难,最高仅达到11.6%的F1@6分数,而部分匹配则可达51.5%,这揭示了形态不匹配是统计方法的主要失败模式。在数据构建过程中,研究人员需克服多阶段清洗的复杂性,包括去除重复记录、恢复缺失关键词、清理噪声元数据、进行语言验证以过滤非斯洛伐克语内容,以及对关键词进行归一化处理。此外,数据源中存在的格式不一致、多语言混杂及作者标注的主观性,进一步增加了数据集构建的挑战。
常用场景
经典使用场景
在自然语言处理领域,特别是针对形态丰富的低资源语言,关键词提取任务面临着数据稀缺的严峻挑战。SlovKE数据集以其超过22万篇斯洛伐克语科学摘要的庞大规模,为这一领域提供了关键的评估基准。该数据集最经典的使用场景在于系统评估无监督与基于大语言模型的关键词提取方法在斯洛伐克语上的性能表现,例如对比YAKE、TextRank、KeyBERT等传统方法与KeyLLM等生成式模型在处理词形变化时的差异,从而揭示形态复杂性对自动化评估指标的根本性影响。
衍生相关工作
围绕SlovKE数据集,已衍生出一系列探索形态丰富语言关键词提取的经典研究工作。这些工作不仅包括对无监督基线模型(如YAKE、TextRank)的深入评估与改进,更关键的是推动了基于大语言模型(如GPT-3.5-turbo)的KeyLLM方法在斯洛伐克语上的首次系统应用与性能分析。相关研究进一步扩展到跨语言迁移学习,尝试将基于SlovKE的洞见应用于捷克语、波兰语等类型学相似的斯拉夫语言,并激发了关于设计更公平的、考虑形态变化的自动化评估指标(如结合精确与部分匹配的混合指标)的学术讨论。
数据集最近研究
最新研究方向
在形态丰富的低资源语言关键短语提取领域,SlovKE数据集的发布标志着研究重心正从传统提取方法向大语言模型驱动范式转移。前沿探索聚焦于利用生成式模型应对形态学变异挑战,通过KeyLLM等架构直接生成规范形式的关键短语,显著缩小了精确匹配与部分匹配间的性能鸿沟。这一进展不仅为斯洛伐克语,也为其他斯拉夫语、芬兰-乌戈尔语等形态复杂语言提供了评估基准,推动了跨语言关键短语提取中形态感知评估协议的发展,并促进了监督式模型在大型标注数据上的微调与应用。
相关研究论文
- 1SlovKE: A Large-Scale Dataset and LLM Evaluation for Slovak Keyphrase Extraction维也纳大学; 夸美纽斯大学·数学、物理与信息学院; 思科系统公司; NaiveNeuron · 2026年
以上内容由遇见数据集搜集并总结生成


