strombergnlp/nordic_langid
收藏Hugging Face2022-10-25 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/strombergnlp/nordic_langid
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- found
language_creators:
- found
language:
- da
- nn
- nb
- fo
- is
- sv
license:
- cc-by-sa-3.0
multilinguality:
- multilingual
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- text-classification
task_ids: []
paperswithcode_id: nordic-langid
pretty_name: Nordic Language ID for Distinguishing between Similar Languages
tags:
- language-identification
---
# Dataset Card for nordic_langid
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** [https://github.com/StrombergNLP/NordicDSL](https://github.com/StrombergNLP/NordicDSL)
- **Repository:** [https://github.com/StrombergNLP/NordicDSL](https://github.com/StrombergNLP/NordicDSL)
- **Paper:** [https://aclanthology.org/2021.vardial-1.8/](https://aclanthology.org/2021.vardial-1.8/)
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [René Haas](mailto:renha@itu.dk)
### Dataset Summary
Automatic language identification is a challenging problem. Discriminating
between closely related languages is especially difficult. This paper presents
a machine learning approach for automatic language identification for the
Nordic languages, which often suffer miscategorisation by existing
state-of-the-art tools. Concretely we will focus on discrimination between six
Nordic language: Danish, Swedish, Norwegian (Nynorsk), Norwegian (Bokmål),
Faroese and Icelandic.
This is the data for the tasks. Two variants are provided: 10K and 50K, with
holding 10,000 and 50,000 examples for each language respectively.
For more info, see the paper: [Discriminating Between Similar Nordic Languages](https://aclanthology.org/2021.vardial-1.8/).
### Supported Tasks and Leaderboards
*
### Languages
This dataset is in six similar Nordic language:
- Danish, `da`
- Faroese, `fo`
- Icelandic, `is`
- Norwegian Bokmål, `nb`
- Norwegian Nynorsk, `nn`
- Swedish, `sv`
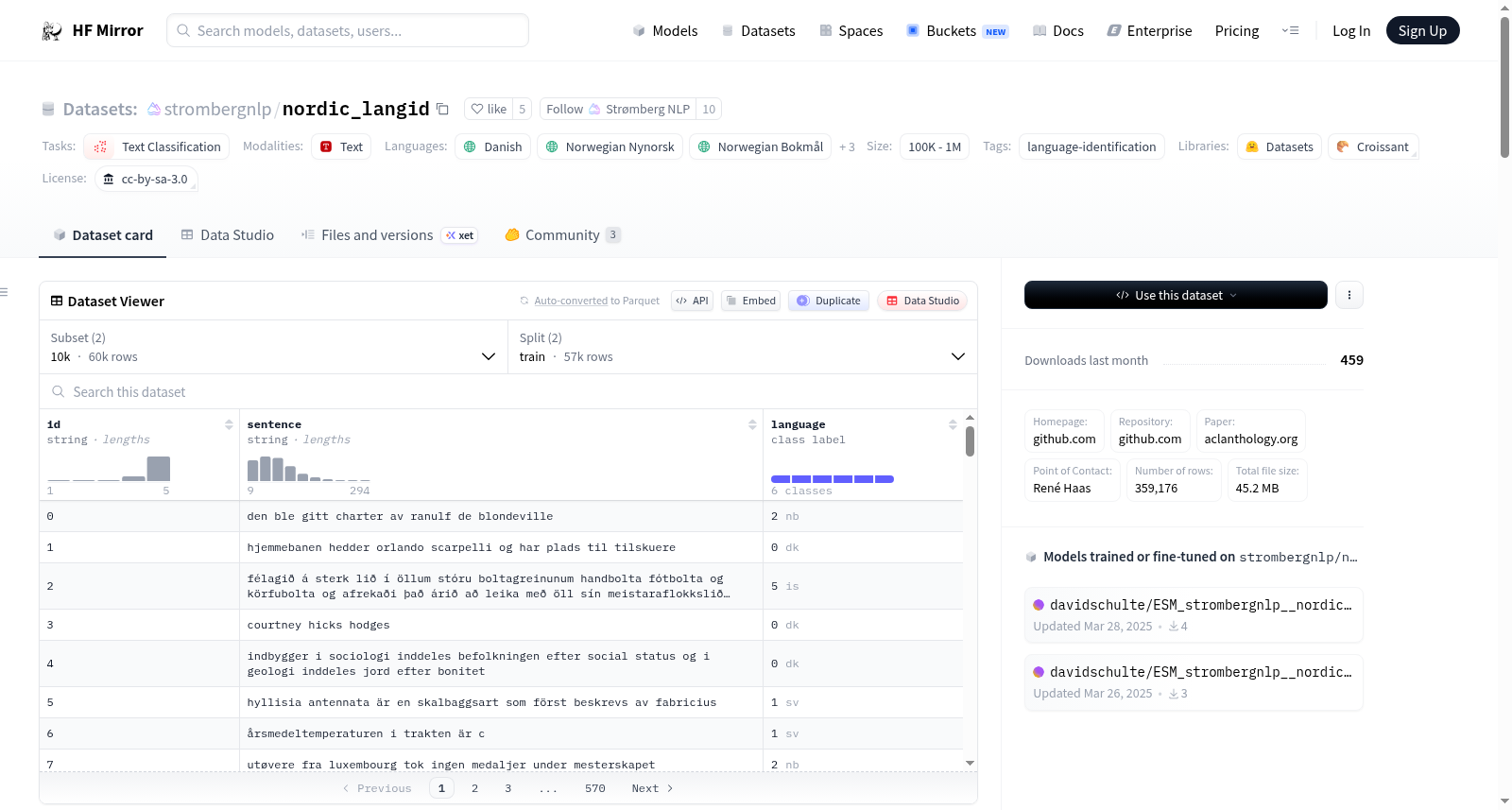
## Dataset Structure
The dataset has two parts, one with 10K samples per language and another with 50K per language.
The original splits and data allocation used in the paper is presented here.
### Data Instances
[Needs More Information]
### Data Fields
- `id`: the sentence's unique identifier, `string`
- `sentence`: the test to be classifier, a `string`
- `language`: the class, one of `da`, `fo`, `is`, `nb`, `no`, `sv`.
### Data Splits
Train and Test splits are provided, divided using the code provided with the paper.
## Dataset Creation
### Curation Rationale
Data is taken from Wikipedia and Tatoeba from each of these six languages.
### Source Data
#### Initial Data Collection and Normalization
**Data collection** Data was scraped from Wikipedia. We downloaded summaries for randomly chosen Wikipedia
articles in each of the languages, saved as raw text
to six .txt files of about 10MB each.
The 50K section is extended with Tatoeba data, which provides a different register to Wikipedia text, and then topped up with more Wikipedia data.
**Extracting Sentences** The first pass in sentence
tokenisation is splitting by line breaks. We then extract shorter sentences with the sentence tokenizer
(sent_tokenize) function from NLTK (Loper
and Bird, 2002). This does a better job than just
splitting by ’.’ due to the fact that abbreviations,
which can appear in a legitimate sentence, typically
include a period symbol.
**Cleaning characters** The initial data set has
many characters that do not belong to the alphabets of the languages we work with. Often the
Wikipedia pages for people or places contain names
in foreign languages. For example a summary
might contain Chinese or Russian characters which
are not strong signals for the purpose of discriminating between the target languages.
Further, it can be that some characters in the
target languages are mis-encoded. These misencodings are also not likely to be intrinsically
strong or stable signals.
To simplify feature extraction, and to reduce the
size of the vocabulary, the raw data is converted
to lowercase and stripped of all characters which
are not part of the standard alphabet of the six
languages using a character whitelist.
#### Who are the source language producers?
The source language is from Wikipedia contributors and Tatoeba contributors.
### Annotations
#### Annotation process
The annotations were found.
#### Who are the annotators?
The annotations were found. They are determined by which language section a contributor posts their content to.
### Personal and Sensitive Information
The data hasn't been checked for PII, and is already all public. Tatoeba is is based on translations of synthetic conversational turns and is unlikely to bear personal or sensitive information.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is intended to help correctly identify content in the languages of six minority languages. Existing systems often confuse these, especially Bokmål and Danish or Icelandic and Faroese. However, some dialects are missed (for example Bornholmsk) and the closed nature of the classification task thus excludes speakers of these languages without recognising their existence.
### Discussion of Biases
The text comes from only two genres, so might not transfer well to other domains.
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
The data here is licensed CC-BY-SA 3.0. If you use this data, you MUST state its origin.
### Citation Information
````
@inproceedings{haas-derczynski-2021-discriminating,
title = "Discriminating Between Similar Nordic Languages",
author = "Haas, Ren{\'e} and
Derczynski, Leon",
booktitle = "Proceedings of the Eighth Workshop on NLP for Similar Languages, Varieties and Dialects",
month = apr,
year = "2021",
address = "Kiyv, Ukraine",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.vardial-1.8",
pages = "67--75",
}
```
提供机构:
strombergnlp
原始信息汇总
数据集概述
数据集名称
- 名称: Nordic Language ID for Distinguishing between Similar Languages
- 别名: nordic_langid
数据集基本信息
- 语言: 丹麦语 (
da), 法罗语 (fo), 冰岛语 (is), 挪威博克马尔语 (nb), 挪威新挪威语 (nn), 瑞典语 (sv) - 许可证: CC-BY-SA-3.0
- 多语言性: 多语言
- 大小: 100K<n<1M
- 源数据集: 原始数据
- 任务类别: 文本分类
- 任务ID: []
- 论文代码ID: nordic-langid
- 标签: 语言识别
数据集描述
- 概述: 该数据集用于区分六种相似的北欧语言:丹麦语、法罗语、冰岛语、挪威博克马尔语、挪威新挪威语和瑞典语。数据集提供了两种变体:10K和50K,分别包含每种语言10,000和50,000个示例。
- 支持的任务: 语言识别
- 语言: 数据集包含六种北欧语言。
数据集结构
- 数据实例: 每个数据实例包含三个字段:
id(字符串,句子唯一标识符)、sentence(字符串,待分类的文本)、language(字符串,类别,包括da,fo,is,nb,nn,sv)。 - 数据分割: 提供训练和测试分割。
数据集创建
- 数据来源: 数据从维基百科和Tatoeba收集,每种语言的数据分别存储在六个大约10MB的.txt文件中。
- 数据预处理: 数据经过清洗,转换为小写,并去除所有非标准字母表中的字符。
- 注释: 注释是通过确定贡献者发布内容的语言部分来确定的。
使用数据集的注意事项
- 社会影响: 该数据集旨在帮助正确识别六种少数语言的内容,但可能未涵盖所有方言。
- 偏见讨论: 文本仅来自两种类型,可能不适用于其他领域。
- 其他已知限制: 需要更多信息。
附加信息
- 许可证信息: 数据集根据CC-BY-SA 3.0许可证发布,使用时必须声明其来源。
- 引用信息: 引用时请参考论文 "Discriminating Between Similar Nordic Languages",作者为René Haas和Leon Derczynski。
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集专注于六种相似北欧语言的自动识别任务,包括丹麦语、瑞典语、挪威尼诺斯克语、挪威博克马尔语、法罗语和冰岛语,旨在解决现有工具对这些语言常出现的误分类问题。数据来源于Wikipedia和Tatoeba,提供两个版本(每个语言10K和50K样本),总样本量约359,176行,并包含训练和测试分割,适用于文本分类和语言识别研究。
以上内容由遇见数据集搜集并总结生成


