silver/personal_dialog
收藏Hugging Face2022-07-10 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/silver/personal_dialog
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- zh
license:
- other
multilinguality:
- monolingual
paperswithcode_id: personaldialog
pretty_name: "PersonalDialog"
size_categories:
- 10M<n<100M
source_datasets:
- original
task_categories:
- conversational
task_ids:
- dialogue-generation
---
# Dataset Card for PersonalDialog
## Table of Contents
- [Dataset Card for PersonalDialog](#dataset-card-for-personaldialog)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.zhengyinhe.com/datasets/
- **Repository:** https://github.com/silverriver/PersonalDilaog
- **Paper:** https://arxiv.org/abs/1901.09672
### Dataset Summary
The PersonalDialog dataset is a large-scale multi-turn Chinese dialogue dataset containing various traits from a large number of speakers.
We are releasing about 5M sessions of carefully filtered dialogues.
Each utterance in PersonalDialog is associated with a speaker marked with traits like Gender, Location, Interest Tags.
### Supported Tasks and Leaderboards
- dialogue-generation: The dataset can be used to train a model for generating dialogue responses.
- response-retrieval: The dataset can be used to train a reranker model that can be used to implement a retrieval-based dialogue model.
### Languages
PersonalDialog is in Chinese
PersonalDialog中的对话是中文的
## Dataset Structure
### Data Instances
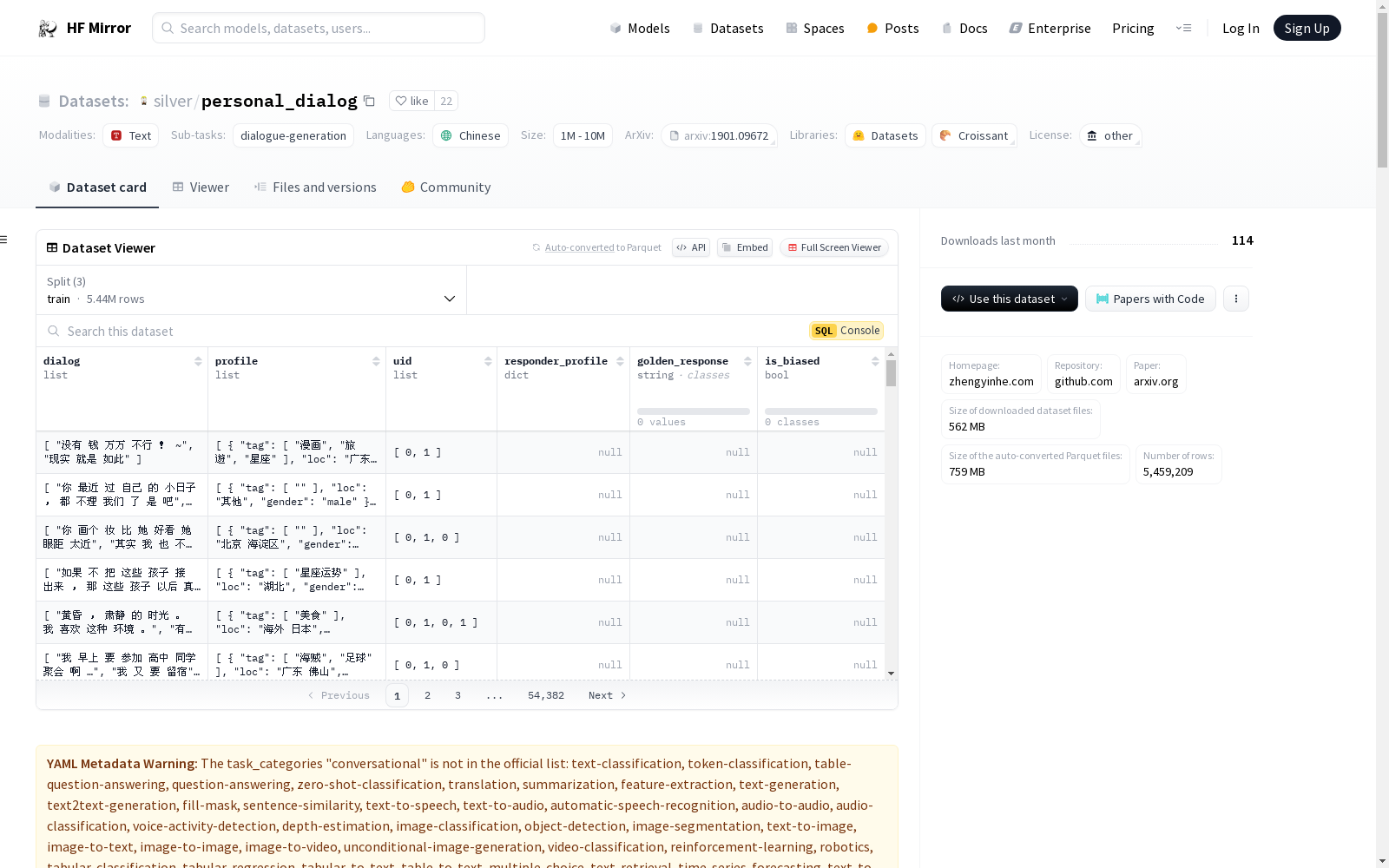
`train` split:
```json
{
"dialog": ["那么 晚", "加班 了 刚 到 家 呀 !", "吃饭 了 么", "吃 过 了 !"],
"profile": [
{
"tag": ["间歇性神经病", "爱笑的疯子", "他们说我犀利", "爱做梦", "自由", "旅游", "学生", "双子座", "好性格"],
"loc": "福建 厦门", "gender": "male"
}, {
"tag": ["设计师", "健康养生", "热爱生活", "善良", "宅", "音樂", "时尚"],
"loc": "山东 济南", "gender": "male"
}
],
"uid": [0, 1, 0, 1],
}
```
`dev` and `test` split:
```json
{
"dialog": ["没 人性 啊 !", "可以 来 组织 啊", "来 上海 陪姐 打 ?"],
"profile": [
{"tag": [""], "loc": "上海 浦东新区", "gender": "female"},
{"tag": ["嘉庚", "keele", "leicester", "UK", "泉州五中"], "loc": "福建 泉州", "gender": "male"},
],
"uid": [0, 1, 0],
"responder_profile": {"tag": ["嘉庚", "keele", "leicester", "UK", "泉州五中"], "loc": "福建 泉州", "gender": "male"},
"golden_response": "吴经理 派车来 小 泉州 接 么 ?",
"is_biased": true,
}
```
### Data Fields
- `dialog` (list of strings): List of utterances consisting of a dialogue.
- `profile` (list of dicts): List of profiles associated with each speaker.
- `tag` (list of strings): List of tags associated with each speaker.
- `loc` (string): Location of each speaker.
- `gender` (string): Gender of each speaker.
- `uid` (list of int): Speaker id for each utterance in the dialogue.
- `responder_profile` (dict): Profile of the responder. (Only available in `dev` and `test` split)
- `golden_response` (str): Response of the responder. (Only available in `dev` and `test` split)
- `id_biased` (bool): Whether the dialogue is guranteed to be persona related or not. (Only available in `dev` and `test` split)
### Data Splits
|train|valid|test|
|---:|---:|---:|
|5,438,165 | 10,521 | 10,523 |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
other-weibo
This dataset is collected from Weibo.
You can refer to the [detailed policy](https://weibo.com/signup/v5/privacy) required to use this dataset.
Please restrict the usage of this dataset to non-commerical purposes.
### Citation Information
```bibtex
@article{zheng2019personalized,
title = {Personalized dialogue generation with diversified traits},
author = {Zheng, Yinhe and Chen, Guanyi and Huang, Minlie and Liu, Song and Zhu, Xuan},
journal = {arXiv preprint arXiv:1901.09672},
year = {2019}
}
@inproceedings{zheng2020pre,
title = {A pre-training based personalized dialogue generation model with persona-sparse data},
author = {Zheng, Yinhe and Zhang, Rongsheng and Huang, Minlie and Mao, Xiaoxi},
booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence},
volume = {34},
number = {05},
pages = {9693--9700},
year = {2020}
}
```
### Contributions
Thanks to [Yinhe Zheng](https://github.com/silverriver) for adding this dataset.
---
annotations_creators:
- 无标注(no-annotation)
language_creators:
- 公开获取(found)
language:
- 中文(zh)
license:
- 其他(other)
multilinguality:
- 单语言(monolingual)
paperswithcode_id: personaldialog
pretty_name: "PersonalDialog"
size_categories:
- 1000万 < 数据量 < 1亿
source_datasets:
- 原始数据集(original)
task_categories:
- 对话式(conversational)
task_ids:
- 对话生成(dialogue-generation)
---
# PersonalDialog 数据集卡片
## 目录
- [PersonalDialog 数据集卡片](#dataset-card-for-personaldialog)
- [目录](#table-of-contents)
- [数据集描述](#dataset-description)
- [数据集概述](#dataset-summary)
- [支持任务与基准榜单](#supported-tasks-and-leaderboards)
- [使用语言](#languages)
- [数据集结构](#dataset-structure)
- [数据样例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集构建](#dataset-creation)
- [构建依据](#curation-rationale)
- [源数据](#source-data)
- [初始数据采集与标准化](#initial-data-collection-and-normalization)
- [语言生产者是谁?](#who-are-the-source-language-producers)
- [标注信息](#annotations)
- [标注流程](#annotation-process)
- [标注者是谁?](#who-are-the-annotators)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据集使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏差讨论](#discussion-of-biases)
- [其他已知局限性](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集提供者](#dataset-curators)
- [许可信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献致谢](#contributions)
## 数据集描述
- **主页:** https://www.zhengyinhe.com/datasets/
- **代码仓库:** https://github.com/silverriver/PersonalDilaog
- **论文链接:** https://arxiv.org/abs/1901.09672
### 数据集概述
PersonalDialog 数据集是一款大规模多轮中文对话数据集,涵盖了大量对话者的多样化身份特征。
本次发布的数据集包含约500万轮经过严格筛选的对话会话。
PersonalDialog 中的每一轮话语(utterance)均关联至一位对话者,并附带性别、所在地、兴趣标签等身份特征。
### 支持任务与基准榜单
- 对话生成(dialogue-generation):该数据集可用于训练对话回复生成模型。
- 回复检索(response-retrieval):该数据集可用于训练重排序模型(reranker model),以实现基于检索的对话模型(retrieval-based dialogue model)。
### 使用语言
PersonalDialog 采用中文
PersonalDialog 中的对话均为中文
## 数据集结构
### 数据样例
`训练集`划分:
json
{
"dialog": ["那么 晚", "加班 了 刚 到 家 呀 !", "吃饭 了 么", "吃 过 了 !"],
"profile": [
{
"tag": ["间歇性神经病", "爱笑的疯子", "他们说我犀利", "爱做梦", "自由", "旅游", "学生", "双子座", "好性格"],
"loc": "福建 厦门", "gender": "male"
}, {
"tag": ["设计师", "健康养生", "热爱生活", "善良", "宅", "音樂", "时尚"],
"loc": "山东 济南", "gender": "male"
}
],
"uid": [0, 1, 0, 1],
}
`验证集与测试集`划分:
json
{
"dialog": ["没 人性 啊 !", "可以 来 组织 啊", "来 上海 陪姐 打 ?"],
"profile": [
{"tag": [""], "loc": "上海 浦东新区", "gender": "female"},
{"tag": ["嘉庚", "keele", "leicester", "UK", "泉州五中"], "loc": "福建 泉州", "gender": "male"},
],
"uid": [0, 1, 0],
"responder_profile": {"tag": ["嘉庚", "keele", "leicester", "UK", "泉州五中"], "loc": "福建 泉州", "gender": "male"},
"golden_response": "吴经理 派车来 小 泉州 接 么 ?",
"is_biased": true,
}
### 数据字段
- `dialog`(字符串列表):组成一段对话的话语轮次(utterance)列表。
- `profile`(字典列表):每位对话者对应的用户画像列表。
- `tag`(字符串列表):对话者对应的身份标签列表。
- `loc`(字符串):对话者的所在地。
- `gender`(字符串):对话者的性别。
- `uid`(整数列表):对话中每一轮话语对应的对话者ID。
- `responder_profile`(字典):回复者的用户画像。(仅在验证集与测试集划分中可用)
- `golden_response`(字符串):回复者的标准回复。(仅在验证集与测试集划分中可用)
- `is_biased`(布尔值):该对话是否确保与对话者人设相关。(仅在验证集与测试集划分中可用)
### 数据划分
|训练集|验证集|测试集|
|---:|---:|---:|
|5,438,165 | 10,521 | 10,523 |
## 数据集构建
### 构建依据
[Needs More Information]
### 源数据
#### 初始数据采集与标准化
[Needs More Information]
#### 语言生产者是谁?
[Needs More Information]
### 标注信息
#### 标注流程
[Needs More Information]
#### 标注者是谁?
[Needs More Information]
### 个人与敏感信息
[Needs More Information]
## 数据集使用注意事项
### 数据集的社会影响
[Needs More Information]
### 偏差讨论
[Needs More Information]
### 其他已知局限性
[Needs More Information]
## 附加信息
### 数据集提供者
[Needs More Information]
### 许可信息
other-weibo
本数据集采集自微博平台。
您可参考[详细使用政策](https://weibo.com/signup/v5/privacy)以合规使用本数据集。
请仅将本数据集用于非商业用途。
### 引用信息
bibtex
@article{zheng2019personalized,
title = {Personalized dialogue generation with diversified traits},
author = {Zheng, Yinhe and Chen, Guanyi and Huang, Minlie and Liu, Song and Zhu, Xuan},
journal = {arXiv preprint arXiv:1901.09672},
year = {2019}
}
@inproceedings{zheng2020pre,
title = {A pre-training based personalized dialogue generation model with persona-sparse data},
author = {Zheng, Yinhe and Zhang, Rongsheng and Huang, Minlie and Mao, Xiaoxi},
booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence},
volume = {34},
number = {05},
pages = {9693--9700},
year = {2020}
}
### 贡献致谢
感谢 [Yinhe Zheng](https://github.com/silverriver) 贡献本数据集。
提供机构:
silver
原始信息汇总
数据集概述
数据集名称
- 名称: PersonalDialog
- 别名: PersonalDilaog
数据集属性
- 语言: 中文
- 许可证: other
- 多语言性: 单语种
- 大小: 10M<n<100M
- 源数据: 原始数据
- 任务类别: 对话生成
- 任务ID: dialogue-generation
数据集描述
- 摘要: PersonalDialog是一个大规模的多轮中文对话数据集,包含大量说话者的各种特征。数据集包含约5M个精心筛选的对话会话。每个话语都与一个带有性别、位置、兴趣标签等特征的说话者关联。
- 支持的任务:
- 对话生成: 用于训练生成对话响应的模型。
- 响应检索: 用于训练重排序模型,实现基于检索的对话模型。
数据集结构
- 数据实例:
train分割: 包含对话、说话者个人资料和说话者ID。dev和test分割: 除了基础信息外,还包括响应者的个人资料、黄金响应和偏见标识。
- 数据字段:
dialog: 对话列表。profile: 说话者个人资料列表。tag: 说话者标签列表。loc: 说话者位置。gender: 说话者性别。uid: 说话者ID列表。responder_profile: 响应者个人资料(仅在dev和test分割中)。golden_response: 响应者的黄金响应(仅在dev和test分割中)。is_biased: 对话是否保证与个人相关(仅在dev和test分割中)。
数据集创建
- 许可证信息: 数据集收集自微博,使用需遵守详细政策,仅限于非商业用途。
- 贡献者: 感谢Yinhe Zheng添加此数据集。
引用信息
bibtex @article{zheng2019personalized, title = {Personalized dialogue generation with diversified traits}, author = {Zheng, Yinhe and Chen, Guanyi and Huang, Minlie and Liu, Song and Zhu, Xuan}, journal = {arXiv preprint arXiv:1901.09672}, year = {2019} }
@inproceedings{zheng2020pre, title = {A pre-training based personalized dialogue generation model with persona-sparse data}, author = {Zheng, Yinhe and Zhang, Rongsheng and Huang, Minlie and Mao, Xiaoxi}, booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence}, volume = {34}, number = {05}, pages = {9693--9700}, year = {2020} }
搜集汇总
数据集介绍
构建方式
PersonalDialog数据集的构建基于大规模的多轮中文对话,涵盖了大量说话者的多种特质。该数据集通过精心筛选,包含了约500万条对话会话。每个对话中的每条发言都与一个带有性别、地点、兴趣标签等特质的说话者相关联。数据集的构建过程包括对话的收集、筛选和标准化,确保了数据的高质量和多样性。
特点
PersonalDialog数据集的主要特点在于其丰富的上下文信息和说话者特质。每条对话不仅包含多轮发言,还附有说话者的详细个人资料,如性别、地点和兴趣标签。这种设计使得数据集在对话生成和响应检索任务中具有显著优势。此外,数据集的规模和多样性也为模型训练提供了广泛的基础。
使用方法
PersonalDialog数据集适用于多种对话生成任务,包括对话生成和响应检索。用户可以通过加载数据集的训练、验证和测试部分来训练和评估模型。数据集的结构清晰,包含对话内容、说话者资料和标识符等字段,便于直接用于模型输入。使用时需注意遵循数据集的非商业用途限制,并参考相关引用信息进行学术引用。
背景与挑战
背景概述
在自然语言处理领域,对话生成技术一直是研究的热点。PersonalDialog数据集由Yinhe Zheng等人于2019年创建,旨在提供一个大规模的多轮中文对话数据集,包含来自大量说话者的各种特征。该数据集的核心研究问题是如何在对话生成中融入个性化的特质,从而提升对话系统的自然度和用户满意度。PersonalDialog数据集的发布,不仅为对话生成模型的训练提供了丰富的资源,还推动了个性化对话系统的发展,对相关领域的研究产生了深远的影响。
当前挑战
PersonalDialog数据集在构建过程中面临多项挑战。首先,数据集的规模庞大,涉及500万条对话,如何高效地收集和处理这些数据是一个技术难题。其次,对话中的个性化特质标注需要精确,以确保模型能够准确捕捉和利用这些信息。此外,数据集中可能存在的偏见和敏感信息,需要在数据使用时进行谨慎处理,以避免对用户产生不良影响。最后,数据集的开放性和使用限制,如仅限于非商业用途,也对研究者的使用提出了一定的约束。
常用场景
经典使用场景
在对话生成领域,PersonalDialog数据集以其丰富的多轮对话和详细的说话者特征标记而著称。该数据集的经典使用场景包括训练对话生成模型,使其能够根据说话者的性别、地理位置和兴趣标签生成个性化的对话响应。此外,该数据集还可用于训练响应检索模型,以实现基于检索的对话系统,从而提高对话的连贯性和个性化。
解决学术问题
PersonalDialog数据集解决了对话生成中的个性化问题,通过提供带有详细特征标记的对话数据,帮助研究者开发能够生成符合说话者个性特征的对话模型。这一问题的解决不仅提升了对话系统的自然度和用户满意度,还为个性化对话生成技术的发展提供了重要的数据支持,推动了该领域的学术研究进展。
衍生相关工作
基于PersonalDialog数据集,研究者们开发了多种个性化对话生成模型,如基于预训练的个性化对话生成模型(Zheng et al., 2020)。这些模型通过结合大规模预训练语言模型和个性化特征,显著提升了对话生成的质量和个性化程度。此外,该数据集还促进了对话系统中偏见和公平性问题的研究,推动了对话生成技术的伦理和实际应用的平衡发展。
以上内容由遇见数据集搜集并总结生成


