Virus-Host-Genomes-updates-v2
收藏Hugging Face2026-03-31 更新2026-04-01 收录
下载链接:
https://huggingface.co/datasets/hiyata/Virus-Host-Genomes-updates-v2
下载链接
链接失效反馈官方服务:
资源简介:
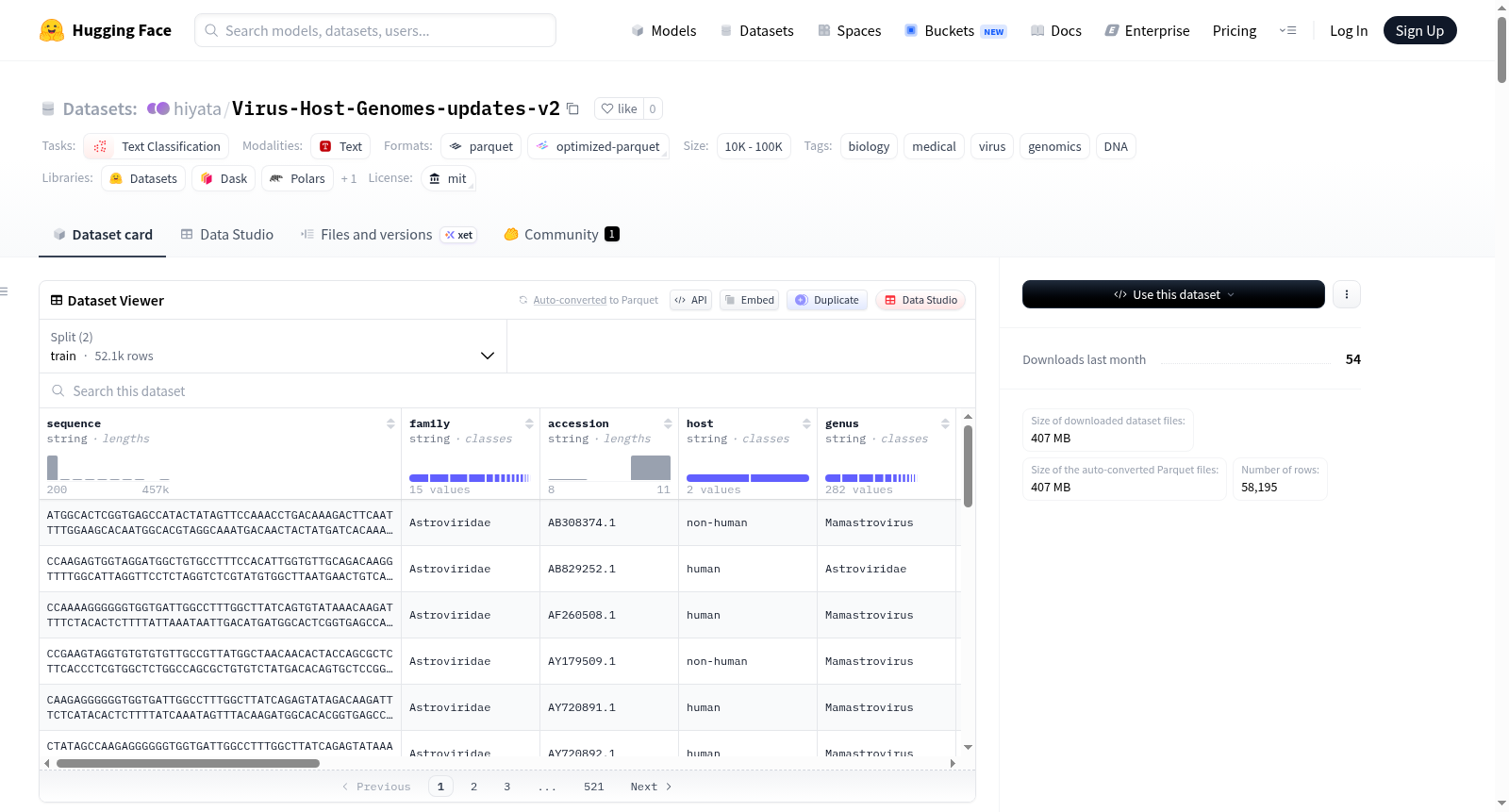
Virus-Host-Genomes 是一个包含病毒基因组序列与宿主信息的综合性数据集,共包含 58,196 条病毒序列。数据集提供了丰富的元数据,包括病毒分类学信息(科、属)、宿主信息、地理数据、分离来源以及多种注释(如人畜共患潜力指标)。该数据集旨在支持宿主特异性遗传决定因素、人畜共患潜力及基于基因组的分类模型的研究。数据集结构包括序列、病毒名称、宿主、人畜共患标志等字段,并分为训练集(52,071 条)和测试集(6,125 条)。数据来源于 NCBI Virus 和 GenBank 等公共数据库,经过序列标准化、宿主信息标准化、地理位置归一化等处理步骤。数据集可能存在采样偏差、时间分布不均、地理偏差等局限性。
创建时间:
2026-03-27
原始信息汇总
病毒-宿主-基因组数据集概述
数据集基本信息
- 数据集名称:Virus-Host-Genomes Dataset
- 最新版本:v1.0.1
- 最后更新日期:2026-03-26
- 许可协议:MIT
- 任务类别:文本分类、文本到文本生成
- 标签:生物学、医学、病毒、基因组学、DNA
- 规模类别:10K < n < 100K
数据集摘要
Virus-Host-Genomes 是一个包含病毒基因组序列及其宿主信息的综合性数据集,共包含 58,196 条病毒序列。该数据集旨在支持对宿主特异性、人畜共患病潜力和基于基因组的分类模型的遗传决定因素的研究。
数据集内容与结构
数据规模
- 总序列数:58,196
- 训练集实例数:52,071
- 测试集实例数:6,125
数据实例
一个典型的数据实例包含病毒基因组序列及其分类和宿主信息,例如: python { sequence: CCATTCCGGG..., virus_name: Human betaherpesvirus 5, host: human, zoonotic: False, }
数据字段
| 字段名 | 类型 | 描述 | 示例 |
|---|---|---|---|
| sequence | 字符串 | 病毒的基因组序列 | "CCATTCCGGG..." |
| family | 字符串 | 病毒的分类学(科) | "Orthoherpesviridae" |
| accession | 字符串 | 数据库登录号 | "AY446894.2" |
| host | 字符串 | 主要宿主(人类或非人类) | "human" |
| genus | 字符串 | 病毒的分类学(属) | "Cytomegalovirus" |
| isolation_date | 字符串 | 病毒分离日期 | "1999" |
| strain_name | 字符串 | 毒株或分离株标识符 | "Merlin" |
| location | 字符串 | 分离的地理位置 | "United Kingdom: Cardiff" |
| virus_name | 字符串 | 病毒的通用名称 | "Human betaherpesvirus 5" |
| isolation_source | 字符串 | 分离的源材料 | "urine from a congenitally infected child" |
| lab_culture | 布尔值 | 是否从实验室培养物中分离 | true/false |
| wastewater_sewage | 布尔值 | 是否从废水中分离 | true/false |
| standardized_host | 字符串 | 标准化的宿主分类学 | "Homo sapiens" |
| host_category | 字符串 | 宿主生物类别 | "Mammal" |
| standardized_location | 字符串 | 标准化的地理位置 | "United Kingdom" |
| zoonotic | 布尔值 | 已知可跨物种传播 | true/false |
| processing_method | 字符串 | 序列处理方法 | "NGS" |
| gemini_annotated | 布尔值 | 是否使用 Gemini AI 进行注释 | true/false |
| is_segmented | 布尔值 | 病毒是否具有分段基因组 | true/false |
| segment_label | 字符串 | 基因组片段标签 | "NA" |
支持的任务
- 宿主预测:使用病毒序列预测潜在宿主。
- 人畜共患病潜力评估:识别具有跨物种传播潜力的病毒。
- 分类学分类:基于基因组序列对病毒进行分类。
- 序列分析:提取序列特征(如 k-mer 频率)用于分析或预处理。
数据集创建
数据来源
该数据集编译自多个公共存储库,包括:
- NCBI Virus
- GenBank
数据处理步骤
- 序列标准化(仅使用明确的 IUPAC 核苷酸字符)。
- 宿主信息标准化。
- 地理位置规范化。
- 添加额外注释,包括人畜共患病潜力标签。
- 质量过滤以去除低质量或不完整的序列。
宿主标签生成方法
- 专家手动标记约 10,000 条序列。
- 第一层自动化标记使用直接字符串匹配已知宿主名称。
- 第二层标记使用物种词典的模式识别。
- 对于无法通过上述两层分类的序列,使用 Google Gemini 分析可用元数据并分配宿主标签。
使用注意事项与局限性
- 采样偏差:可能过度代表具有临床重要性的病毒,而代表性不足的环境病毒。
- 时间分布偏差:较新的病毒(尤其是引起爆发的病毒)可能被过度代表。
- 地理偏差:来自研究基础设施较强地区的样本可能被过度代表。
- 宿主偏差:人类病毒以及来自家养/农业动物的病毒可能被过度代表。
- 注释质量:某些元数据字段不完整或可能包含不确定性。
引用信息
如果使用此数据集,请引用:
@article{carbajo2026sequence, author = {Carbajo, Alan L and Vensko, Taylor A and Pellett, Philip E}, title = {Sequence Based Virus Host Prediction: A Curated Dataset and Generalizable Framework for Training Artificial Intelligence to Identify Viruses of Humans}, journal = {Virus Evolution}, year = {2026}, pages = {veag009}, publisher = {Oxford University Press}, doi = {10.1093/ve/veag009}, url = {https://doi.org/10.1093/ve/veag009} }
更新历史
| 日期 | 版本 | 新增序列 | 总序列数 | 人类宿主序列 | 非人类宿主序列 | 备注 |
|---|---|---|---|---|---|---|
| 2026-03-26 | v1.0.1 | +150 | 58,196 | 89 | 61 | |
| 2026-03-02 | v1.0.0 | +0 | — | — | — | 初始数据集发布 |
搜集汇总
数据集介绍
构建方式
在病毒基因组学领域,构建高质量的数据集对于理解病毒与宿主间的相互作用至关重要。Virus-Host-Genomes-updates-v2数据集通过整合来自NCBI Virus和GenBank等公共数据库的病毒序列,经过严格的标准化处理流程而构建。该流程包括序列标准化,仅保留明确的IUPAC核苷酸字符;宿主信息与地理位置的规范化处理;以及基于专家手动标注与自动化层级标注相结合的宿主标签生成方法。其中,约一万条序列由专家手动标注,其余则通过字符串匹配、模式识别乃至Google Gemini AI分析元数据的方式完成标注,确保了数据的可靠性与一致性。
特点
该数据集以其全面性与精细标注而著称,涵盖了58,196条病毒基因组序列,并配以丰富的元数据,如病毒分类学信息、宿主详情、地理分布及人畜共患潜力指标等。特别值得注意的是,数据集不仅包含标准字段,还针对疱疹病毒目序列额外添加了GC含量、CpG O/E比值等专业注释。数据经过严格的质量过滤,剔除了不完整或低质量序列,并划分为训练集与测试集,为机器学习模型提供了结构化的基准。然而,数据集亦存在采样、时空及地理分布上的潜在偏差,需在使用时予以考量。
使用方法
该数据集主要支持基于序列的宿主预测、人畜共患潜力评估及病毒分类等任务。典型的使用流程始于通过Hugging Face的`datasets`库加载数据,随后可将基因组序列转化为k-mer频率特征向量,作为机器学习模型的输入。提供的示例代码展示了从数据加载、k-mer向量化、特征标准化到神经网络模型训练与评估的完整流程。用户可依据此框架,利用训练集构建分类模型,并在独立的测试集上评估性能,例如通过马修斯相关系数等指标衡量宿主预测的准确性,从而推动病毒宿主特异性遗传决定因素的研究。
背景与挑战
背景概述
在病毒学与生物信息学交叉领域,基因组数据的系统化整合对于解析病毒-宿主互作机制至关重要。Virus-Host-Genomes数据集由Alan L. Carbajo、Taylor A. Vensko和Philip E. Pellett等研究人员于2026年构建,其核心研究问题聚焦于利用病毒基因组序列预测宿主特异性、评估人畜共患潜力以及实现基于序列的病毒分类。该数据集汇集了来自NCBI等公共数据库的58,196条病毒基因组序列,并附有详细的宿主、分类与地理元数据,为开发人工智能驱动的宿主预测模型提供了关键资源,显著推动了计算病毒学与基因组流行病学的发展。
当前挑战
该数据集旨在解决病毒宿主预测与分类这一复杂领域问题,其核心挑战在于病毒基因组的高度变异性与宿主范围的动态演化,使得从序列中提取稳健的判别特征变得异常困难。在构建过程中,研究团队面临多重挑战:首先,原始数据的异质性与不完整性要求对宿主标签进行多层级标准化处理,包括人工标注与自动化模式识别;其次,数据固有的采样偏差,如临床重要病毒与特定地理区域的过度代表,可能影响模型的泛化能力;此外,部分序列元数据缺失,需借助人工智能系统进行补充注释,这引入了额外的质量控制需求。
常用场景
经典使用场景
在病毒基因组学与生物信息学领域,Virus-Host-Genomes-updates-v2数据集为研究病毒与宿主间的相互作用提供了关键资源。其最经典的使用场景是训练机器学习模型进行病毒宿主预测,即依据病毒的基因组序列特征,精准推断其潜在的宿主类别。研究者常利用该数据集中的序列数据与宿主标签,构建分类模型,以探索病毒基因组中决定宿主特异性的遗传标记,这为理解病毒跨物种传播的分子基础奠定了数据基石。
衍生相关工作
围绕该数据集已衍生出多项经典研究工作。例如,Carbajo等人(2026)在《Virus Evolution》上发表的论文,构建了一个用于病毒宿主预测的通用人工智能框架。此外,基于该数据集的疱疹病毒特定子集也被进一步标注和扩展,增加了GC含量、CpG O/E比率等特征,专门用于疱疹病毒科的深入分析,推动了该病毒家族在潜伏感染和细胞嗜性方面的计算生物学研究。
数据集最近研究
最新研究方向
在病毒基因组学与宿主预测领域,Virus-Host-Genomes-updates-v2数据集正推动前沿研究向深度与广度拓展。当前研究焦点集中于利用人工智能模型,特别是基于Transformer架构的预训练语言模型,对病毒基因组序列进行端到端的特征学习,以精准预测宿主范围并评估跨物种传播风险。伴随全球新发传染病监测需求的提升,该数据集支持构建可解释的机器学习框架,用于识别病毒基因组中与宿主特异性及人畜共患潜力相关的遗传标记。这些进展不仅增强了病毒分类与溯源能力,也为公共卫生预警系统提供了关键的基因组学证据。
以上内容由遇见数据集搜集并总结生成


