AI Language Proficiency Monitor
收藏arXiv2025-07-11 更新2025-07-15 收录
下载链接:
https://huggingface.co/spaces/fair-forward/evals-for-every-language
下载链接
链接失效反馈官方服务:
资源简介:
AI Language Proficiency Monitor是一个全面的跨语言基准,系统地评估了LLM在多达200种语言上的性能,特别关注低资源语言。该基准聚合了包括翻译、问答、数学和推理在内的多样化任务,使用了FLORES+、MMLU、GSM8K、TruthfulQA和ARC等数据集。我们提供了一个开源的自动更新排行榜和仪表板,以支持研究人员、开发人员和政策制定者识别模型性能的强项和差距。除了对模型进行排名,该平台还提供了描述性见解,如全球能力图和随时间推移的趋势。通过补充和扩展先前的多语言基准,我们的工作旨在促进多语言人工智能的透明度、包容性和进步。该系统可在https://huggingface.co/spaces/fair-forward/evals-for-every-language访问。
AI Language Proficiency Monitor is a comprehensive cross-lingual benchmark that systematically evaluates the performance of Large Language Models (LLMs) across up to 200 languages, with a particular focus on low-resource languages. This benchmark aggregates diverse tasks including translation, question answering, mathematics, and reasoning, utilizing datasets such as FLORES+, MMLU, GSM8K, TruthfulQA, and ARC. We provide an open-source, automatically updated leaderboard and dashboard to support researchers, developers, and policymakers in identifying the strengths and gaps in model performance. In addition to ranking models, the platform also offers descriptive insights such as global capability maps and temporal trends. By complementing and expanding prior multilingual benchmarks, our work aims to advance transparency, inclusivity, and progress in multilingual artificial intelligence. The system is accessible at https://huggingface.co/spaces/fair-forward/evals-for-every-language.
提供机构:
德国人工智能研究中心(DFKI)
创建时间:
2025-07-11
搜集汇总
数据集介绍
构建方式
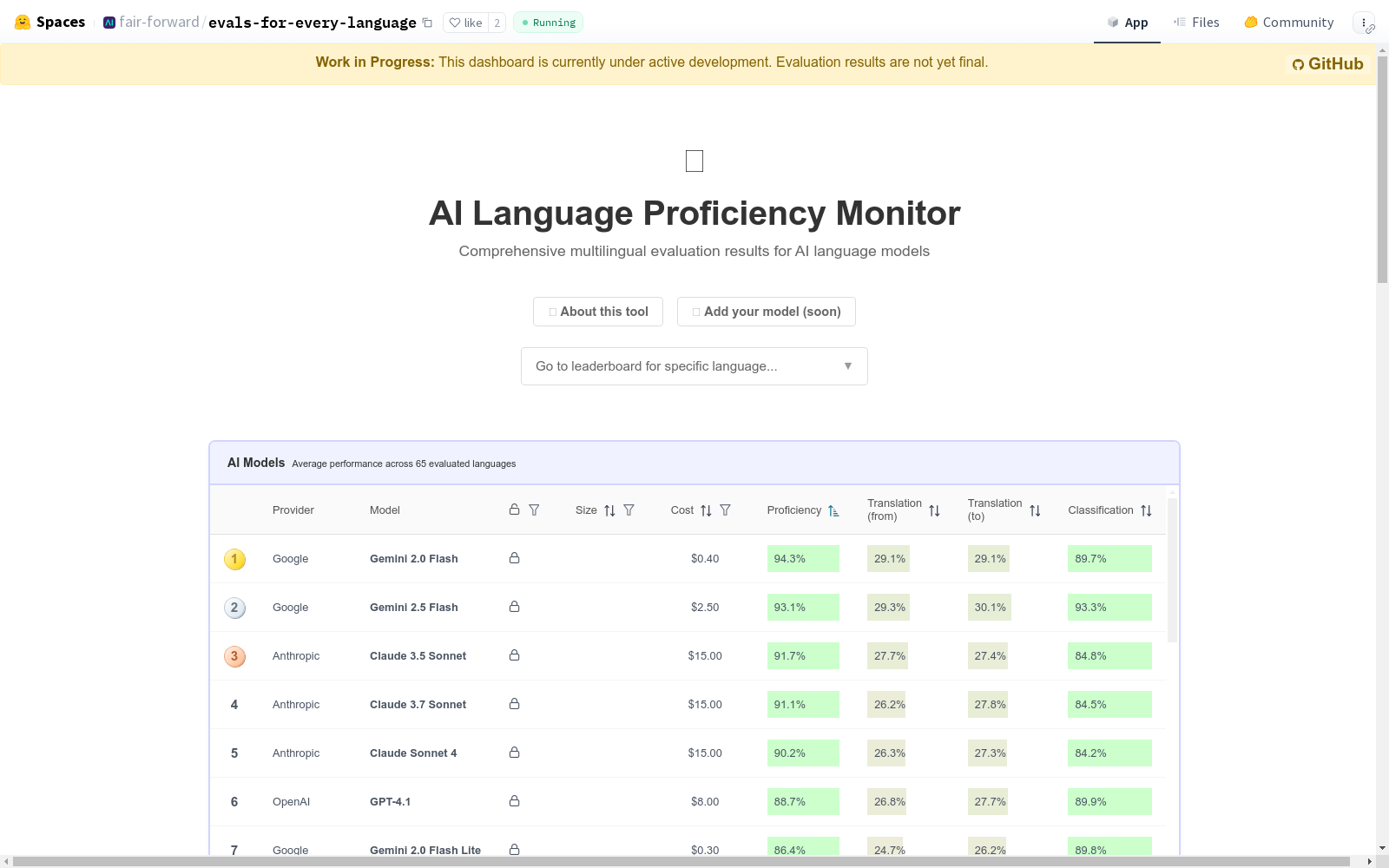
AI Language Proficiency Monitor数据集的构建基于多语言基准测试的整合,涵盖了翻译、文本分类、问答和数学推理等多种自然语言处理任务。研究团队精选了包括FLORES+、MMLU、GSM8K、TruthfulQA和ARC在内的多个数据集,并通过人工翻译与机器翻译相结合的方式,扩展至200种语言,尤其关注低资源语言。为确保数据质量,优先采用人工翻译版本,并在同一语言存在多种文字体系时,选用使用人数较多的文字版本。此外,针对未被现有基准覆盖的语言,采用Google Neural Machine Translation进行机器翻译补充,以实现全球语言的广泛覆盖。
特点
该数据集的核心特点在于其全面性和动态更新机制。它不仅覆盖多达200种语言,还特别注重低资源语言的代表性,语言覆盖范围占全球人口的80%-95%。数据集通过自动化流水线每日更新,确保评估结果始终反映最新模型性能。此外,数据集提供了多维度的评估指标,包括翻译准确率、分类准确率、问答正确率等,并通过归一化处理生成统一的“语言熟练度分数”,便于跨语言和跨任务的性能比较。可视化仪表盘进一步增强了数据的可访问性,为不同背景的用户提供了直观的性能分析工具。
使用方法
该数据集主要服务于三类用户群体:研究人员和模型开发者可通过“语言熟练度分数”评估模型的多语言能力;实践者能够根据特定语言和任务筛选最适合的模型;政策制定者则能识别亟需资源投入的低资源语言。使用方式上,用户可通过开源的HuggingFace空间访问交互式排行榜和仪表盘,支持按模型类型、语言或任务进行筛选。评估采用少样本提示(few-shot prompting)方法,以减少翻译偏差对结果的影响。对于数学任务,还定义了标准化的响应格式以统一评估标准。
背景与挑战
背景概述
AI Language Proficiency Monitor数据集由David Pomerenke、Jonas Nothnagel和Simon Ostermann等研究人员于2025年创建,旨在系统评估大型语言模型(LLMs)在多达200种语言中的表现,尤其关注低资源语言。该数据集整合了多种任务,包括翻译、问答、数学和推理等,并提供了开源、自动更新的排行榜和仪表板,帮助研究人员、开发者和政策制定者识别模型在不同语言中的优势和不足。该数据集通过全球熟练度地图和时间趋势分析,为多语言AI的透明度和包容性发展提供了重要支持。
当前挑战
AI Language Proficiency Monitor面临的挑战主要包括:1) 领域问题方面,如何准确评估低资源语言中LLMs的表现,尤其是在缺乏高质量基准数据的情况下;2) 构建过程中,如何解决机器翻译带来的偏差问题,以及如何确保不同语言任务的公平性和可比性。此外,数据集还需不断扩展以涵盖更多语言和任务,同时保持评估的实时性和计算效率。
常用场景
经典使用场景
在自然语言处理领域,AI Language Proficiency Monitor数据集被广泛用于评估大型语言模型(LLMs)在多语言环境下的表现。该数据集通过整合翻译、问答、数学和推理等多种任务,覆盖多达200种语言,尤其关注低资源语言,为研究人员提供了一个全面的多语言基准测试平台。其经典使用场景包括模型性能的横向比较、语言能力的动态追踪以及跨语言任务的系统性评估。
解决学术问题
该数据集有效解决了多语言模型评估中的资源不均衡问题,特别是针对低资源语言的性能量化难题。通过标准化多任务评估框架,它填补了传统基准测试在语言覆盖率和任务多样性上的空白,为学术界提供了可比较的模型性能指标。其意义在于推动了多语言AI研究的透明化进程,并为模型优化方向提供了数据支撑,从而促进语言技术在全球范围内的公平发展。
衍生相关工作
该数据集催生了多个重要研究方向,包括低资源语言适配技术、多语言评估指标优化等。其衍生的经典工作如AfroBench非洲语言基准测试、欧洲多语言排行榜等区域性评估体系,均借鉴了其标准化框架。同时,基于该数据提出的语言能力量化指标被后续研究广泛采用,推动了XLM-R、mBERT等模型的多语言能力优化。
以上内容由遇见数据集搜集并总结生成


