qwq-misguided-attention
收藏Hugging Face2024-11-30 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/victor/qwq-misguided-attention
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含来自QwQ-32B-Preview模型对MisguidedAttention提示挑战的响应。MisguidedAttention挑战由精心设计的提示组成,旨在测试大型语言模型在存在误导信息时的推理能力。这些提示是著名思想实验、谜题和悖论的修改版本,要求仔细的逻辑分析而非训练数据的模式匹配。数据集展示了模型在面对这些提示时的表现,包括成功和失败的案例。
创建时间:
2024-11-29
原始信息汇总
数据集概述
该数据集包含QwQ-32B-Preview模型对MisguidedAttention提示挑战的响应。Misguided Attention挑战是一系列精心设计的提示,旨在测试大型语言模型(LLMs)在存在误导信息时的推理能力。
关于Misguided Attention
Misguided Attention挑战由知名思想实验、谜题和悖论的修改版本组成。这些修改虽然微妙但意义重大,需要仔细的逐步逻辑分析,而不是从训练数据中进行模式匹配。
该挑战探索了一个有趣的现象:尽管LLMs具有计算性质,但它们经常表现出类似于人类认知偏差的行为,即Einstellungseffekt——熟悉的模式会触发学习到的响应,即使这些响应不适用于修改后的问题。
在面对这些提示时,理想的响应应展示:
- 对特定问题细节的仔细分析
- 逐步逻辑推理
- 识别问题与经典版本的差异
- 为修改后的场景得出正确解决方案
然而,我们经常观察到模型:
- 依赖于对原始问题的记忆解决方案
- 混合冲突的推理模式
- 未能注意到修改版本中的关键差异
创建自己的数据集
您可以使用observers包轻松创建类似的数据集。
使用Hugging Face Serverless API
该数据集的回答是使用Hugging Face的Serverless Inference API生成的,该API为各种开源模型提供了OpenAI兼容的端点。这意味着您可以使用标准的OpenAI客户端库与Hugging Face模型进行交互。
搜集汇总
数据集介绍
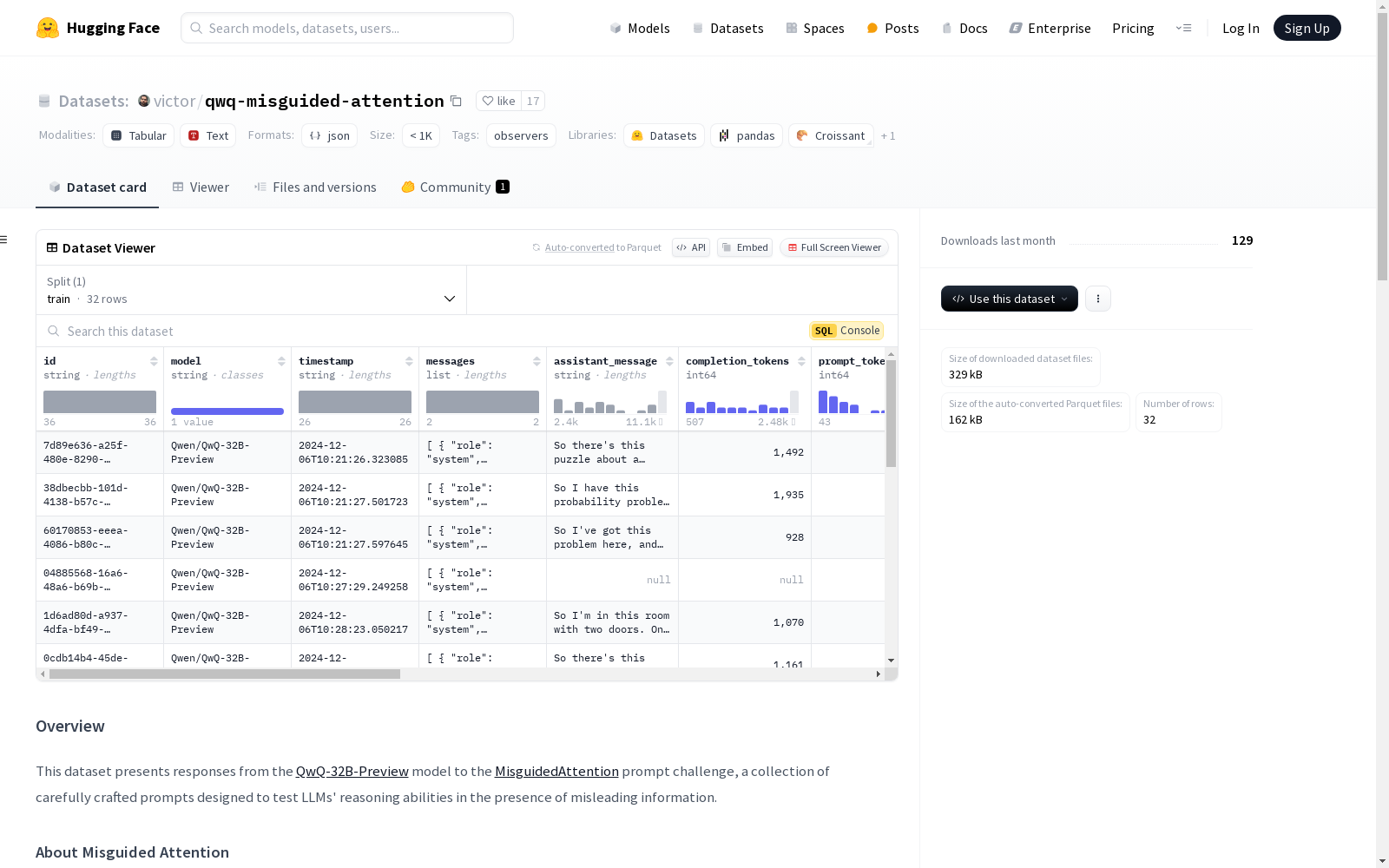
构建方式
qwq-misguided-attention数据集通过精心设计的MisguidedAttention提示挑战,收集了QwQ-32B-Preview模型对一系列经过微妙修改的著名思想实验、谜题和悖论的响应。这些提示旨在测试大型语言模型(LLMs)在面对误导性信息时的推理能力。数据集的构建依赖于对经典问题的细微改动,要求模型进行细致的逻辑分析而非简单的模式匹配。通过使用observers包,用户可以轻松创建类似的响应数据集,该包能够自动收集和存储模型的响应。
特点
该数据集的显著特点在于其挑战性提示的设计,这些提示不仅测试了模型的逻辑推理能力,还揭示了模型在面对熟悉模式时的认知偏差,类似于人类的Einstellungseffekt现象。数据集中的响应展示了模型在识别问题差异、进行逐步推理以及得出正确解决方案方面的表现,同时也暴露了模型在处理修改版问题时的常见错误,如依赖记忆的解决方案和混淆推理模式。
使用方法
使用qwq-misguided-attention数据集时,用户可以通过Hugging Face的Serverless Inference API与QwQ-32B-Preview模型进行交互,利用OpenAI兼容的客户端库进行模型响应的生成和分析。此外,用户还可以借助observers包创建自定义数据集,通过配置数据存储和自动收集响应,进一步探索和评估模型在不同提示下的表现。该数据集适用于研究LLMs的推理能力和认知偏差,以及开发更高效的提示设计和模型训练策略。
背景与挑战
背景概述
qwq-misguided-attention数据集由QwQ-32B-Preview模型对MisguidedAttention提示挑战的响应组成,该挑战旨在测试大型语言模型(LLMs)在面对误导性信息时的推理能力。MisguidedAttention挑战包含对著名思想实验、谜题和悖论的微妙修改,这些修改要求模型进行细致的逻辑分析,而非依赖训练数据中的模式匹配。该数据集的创建旨在探索LLMs在处理复杂问题时,如何避免因熟悉模式而产生的认知偏差,如Einstellungseffekt现象。通过这一数据集,研究人员能够评估模型在面对修改后的问题时,是否能够识别差异并进行正确的逻辑推理。
当前挑战
qwq-misguided-attention数据集面临的挑战主要集中在两个方面:一是模型在面对修改后的问题时,往往依赖于记忆中的原始问题解决方案,而非进行细致的逻辑分析;二是模型在推理过程中容易混淆不同的逻辑模式,未能注意到问题中的关键差异。此外,构建此类数据集的过程中,如何设计出既具有挑战性又能有效评估模型推理能力的提示,也是一个重要的技术难题。这些挑战不仅反映了LLMs在复杂推理任务中的局限性,也为未来的模型优化提供了研究方向。
常用场景
经典使用场景
qwq-misguided-attention数据集的经典使用场景在于评估和提升大型语言模型(LLMs)在面对误导性信息时的推理能力。该数据集通过精心设计的提示挑战,测试模型在处理经过微妙修改的著名思想实验、谜题和悖论时的表现。这些提示要求模型进行细致的逻辑分析,而非依赖训练数据中的模式匹配,从而揭示模型在复杂情境下的推理缺陷。
解决学术问题
该数据集解决了大型语言模型在面对误导性信息时常见的推理偏差问题,特别是类似于人类认知偏差中的Einstellungseffekt现象。通过提供经过修改的复杂问题,qwq-misguided-attention数据集帮助研究者识别和纠正模型在处理新问题时的固有偏见,推动了LLMs在逻辑推理和问题解决能力上的学术研究进展。
衍生相关工作
基于qwq-misguided-attention数据集,研究者们进一步开发了多种评估和训练LLMs推理能力的工具和方法。例如,通过observers包,研究者可以轻松创建类似的评估数据集,从而扩展了该领域的研究范围。此外,该数据集还启发了对LLMs在复杂逻辑任务中表现的研究,推动了相关模型架构和训练策略的创新。
以上内容由遇见数据集搜集并总结生成


