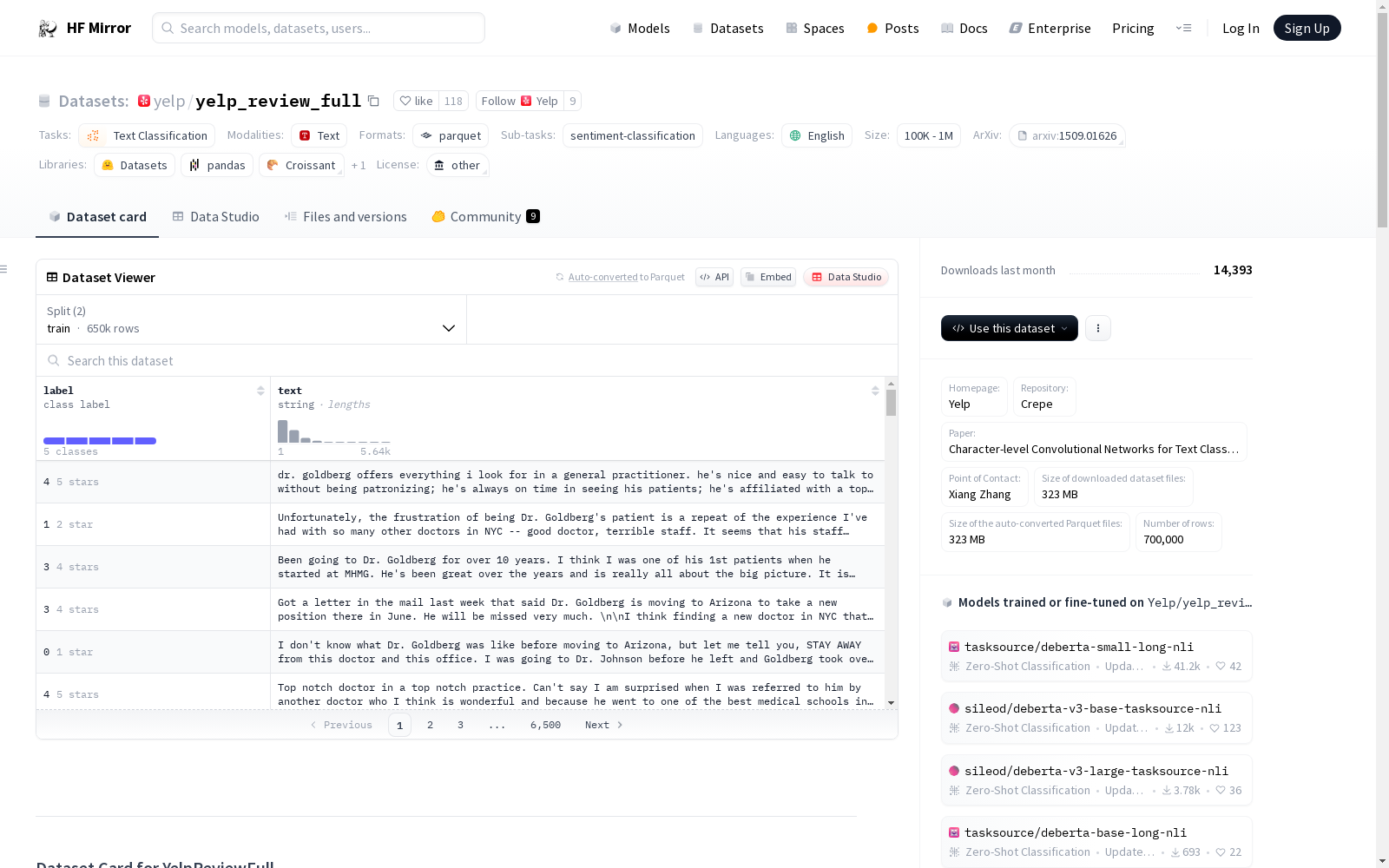
资源简介:
---
annotations_creators:
- crowdsourced
language_creators:
- crowdsourced
language:
- en
license:
- other
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- sentiment-classification
pretty_name: YelpReviewFull
license_details: yelp-licence
dataset_info:
config_name: yelp_review_full
features:
- name: label
dtype:
class_label:
names:
'0': 1 star
'1': 2 star
'2': 3 stars
'3': 4 stars
'4': 5 stars
- name: text
dtype: string
splits:
- name: train
num_bytes: 483811554
num_examples: 650000
- name: test
num_bytes: 37271188
num_examples: 50000
download_size: 322952369
dataset_size: 521082742
configs:
- config_name: yelp_review_full
data_files:
- split: train
path: yelp_review_full/train-*
- split: test
path: yelp_review_full/test-*
default: true
train-eval-index:
- config: yelp_review_full
task: text-classification
task_id: multi_class_classification
splits:
train_split: train
eval_split: test
col_mapping:
text: text
label: target
metrics:
- type: accuracy
name: Accuracy
- type: f1
name: F1 macro
args:
average: macro
- type: f1
name: F1 micro
args:
average: micro
- type: f1
name: F1 weighted
args:
average: weighted
- type: precision
name: Precision macro
args:
average: macro
- type: precision
name: Precision micro
args:
average: micro
- type: precision
name: Precision weighted
args:
average: weighted
- type: recall
name: Recall macro
args:
average: macro
- type: recall
name: Recall micro
args:
average: micro
- type: recall
name: Recall weighted
args:
average: weighted
---
---
# Dataset Card for YelpReviewFull
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [Yelp](https://www.yelp.com/dataset)
- **Repository:** [Crepe](https://github.com/zhangxiangxiao/Crepe)
- **Paper:** [Character-level Convolutional Networks for Text Classification](https://arxiv.org/abs/1509.01626)
- **Point of Contact:** [Xiang Zhang](mailto:xiang.zhang@nyu.edu)
### Dataset Summary
The Yelp reviews dataset consists of reviews from Yelp.
It is extracted from the Yelp Dataset Challenge 2015 data.
### Supported Tasks and Leaderboards
- `text-classification`, `sentiment-classification`: The dataset is mainly used for text classification: given the text, predict the sentiment.
### Languages
The reviews were mainly written in english.
## Dataset Structure
### Data Instances
A typical data point, comprises of a text and the corresponding label.
An example from the YelpReviewFull test set looks as follows:
```
{
'label': 0,
'text': 'I got \'new\' tires from them and within two weeks got a flat. I took my car to a local mechanic to see if i could get the hole patched, but they said the reason I had a flat was because the previous patch had blown - WAIT, WHAT? I just got the tire and never needed to have it patched? This was supposed to be a new tire. \\nI took the tire over to Flynn\'s and they told me that someone punctured my tire, then tried to patch it. So there are resentful tire slashers? I find that very unlikely. After arguing with the guy and telling him that his logic was far fetched he said he\'d give me a new tire \\"this time\\". \\nI will never go back to Flynn\'s b/c of the way this guy treated me and the simple fact that they gave me a used tire!'
}
```
### Data Fields
- 'text': The review texts are escaped using double quotes ("), and any internal double quote is escaped by 2 double quotes (""). New lines are escaped by a backslash followed with an "n" character, that is "\n".
- 'label': Corresponds to the score associated with the review (between 1 and 5).
### Data Splits
The Yelp reviews full star dataset is constructed by randomly taking 130,000 training samples and 10,000 testing samples for each review star from 1 to 5.
In total there are 650,000 trainig samples and 50,000 testing samples.
## Dataset Creation
### Curation Rationale
The Yelp reviews full star dataset is constructed by Xiang Zhang (xiang.zhang@nyu.edu) from the Yelp Dataset Challenge 2015. It is first used as a text classification benchmark in the following paper: Xiang Zhang, Junbo Zhao, Yann LeCun. Character-level Convolutional Networks for Text Classification. Advances in Neural Information Processing Systems 28 (NIPS 2015).
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
You can check the official [yelp-dataset-agreement](https://s3-media3.fl.yelpcdn.com/assets/srv0/engineering_pages/bea5c1e92bf3/assets/vendor/yelp-dataset-agreement.pdf).
### Citation Information
Xiang Zhang, Junbo Zhao, Yann LeCun. Character-level Convolutional Networks for Text Classification. Advances in Neural Information Processing Systems 28 (NIPS 2015).
### Contributions
Thanks to [@hfawaz](https://github.com/hfawaz) for adding this dataset.
annotations_creators:
- 众包(crowdsourced)
language_creators:
- 众包(crowdsourced)
language:
- 英语(en)
license:
- 其他(other)
multilinguality:
- 单语言(monolingual)
size_categories:
- 100K<n<1M
source_datasets:
- 原创数据集(original)
task_categories:
- 文本分类(text-classification)
task_ids:
- 情感分类(sentiment-classification)
pretty_name: 完整Yelp评论数据集(YelpReviewFull)
license_details: Yelp许可协议(yelp-licence)
dataset_info:
config_name: yelp_review_full
features:
- name: label
dtype:
class_label:
names:
'0': 1星
'1': 2星
'2': 3星
'3': 4星
'4': 5星
- name: text
dtype: 字符串(string)
splits:
- name: 训练集(train)
num_bytes: 483811554
num_examples: 650000
- name: 测试集(test)
num_bytes: 37271188
num_examples: 50000
download_size: 322952369
dataset_size: 521082742
configs:
- config_name: yelp_review_full
data_files:
- split: 训练集(train)
path: yelp_review_full/train-*
- split: 测试集(test)
path: yelp_review_full/test-*
default: true
train-eval-index:
- config: yelp_review_full
task: 文本分类(text-classification)
task_id: 多类别分类(multi_class_classification)
splits:
train_split: 训练集(train)
eval_split: 测试集(test)
col_mapping:
text: text
label: 目标标签(target)
metrics:
- type: 准确率(accuracy)
name: 准确率(Accuracy)
- type: F1值(f1)
name: 宏平均F1值(F1 macro)
args:
average: 宏平均(macro)
- type: F1值(f1)
name: 微平均F1值(F1 micro)
args:
average: 微平均(micro)
- type: F1值(f1)
name: 加权平均F1值(F1 weighted)
args:
average: 加权平均(weighted)
- type: 精确率(precision)
name: 宏平均精确率(Precision macro)
args:
average: 宏平均(macro)
- type: 精确率(precision)
name: 微平均精确率(Precision micro)
args:
average: 微平均(micro)
- type: 精确率(precision)
name: 加权平均精确率(Precision weighted)
args:
average: 加权平均(weighted)
- type: 召回率(recall)
name: 宏平均召回率(Recall macro)
args:
average: 宏平均(macro)
- type: 召回率(recall)
name: 微平均召回率(Recall micro)
args:
average: 微平均(micro)
- type: 召回率(recall)
name: 加权平均召回率(Recall weighted)
args:
average: 加权平均(weighted)
---
# 完整Yelp评论数据集(YelpReviewFull)数据集卡片
## 目录
- [数据集概述](#dataset-description)
- [数据集摘要](#dataset-summary)
- [支持任务与基准榜单](#supported-tasks-and-leaderboards)
- [使用语言](#languages)
- [数据集结构](#dataset-structure)
- [数据实例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集构建](#dataset-creation)
- [数据集构建理据](#curation-rationale)
- [源数据](#source-data)
- [标注信息](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据集使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏差分析](#discussion-of-biases)
- [其他已知局限性](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集维护者](#dataset-curators)
- [许可信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献者](#contributions)
## 数据集概述
- **主页**:[Yelp](https://www.yelp.com/dataset)
- **代码仓库**:[Crepe](https://github.com/zhangxiangxiao/Crepe)
- **相关论文**:[《字符级卷积网络用于文本分类》](https://arxiv.org/abs/1509.01626)(原标题:Character-level Convolutional Networks for Text Classification)
- **联系人**:[张翔(Xiang Zhang)](mailto:xiang.zhang@nyu.edu)
### 数据集摘要
完整Yelp评论数据集包含来自Yelp平台的用户评论,其数据源自2015年Yelp数据集挑战赛的公开数据。
### 支持任务与基准榜单
- `文本分类(text-classification)`、`情感分类(sentiment-classification)`:本数据集主要用于文本分类任务,即给定评论文本,预测其对应的情感星级评分。
### 使用语言
本数据集的评论主体均以英语撰写。
## 数据集结构
### 数据实例
一条典型的数据样本由评论文本与对应的标签组成。以下为来自测试集的示例样本:
json
{
'label': 0,
'text': '我从他们这里购买了“全新”轮胎,但仅两周后就出现了爆胎。我将车辆开到当地汽修店,尝试修补轮胎上的孔洞,但维修人员表示爆胎原因是之前的补丁脱落了——等等,什么?我刚买的轮胎,之前根本不需要修补?这明明应该是全新轮胎。
我把轮胎送到Flynn汽修店,他们告诉我有人先扎破了我的轮胎,之后又试图进行修补。难道存在心怀不满的轮胎破坏者?这实在令人难以置信。与店员争执后,我指出他的逻辑完全站不住脚,他最终表示“这次”会给我更换全新轮胎。
由于这名店员的服务态度,以及他们给我更换了二手轮胎的事实,我绝不会再光顾Flynn汽修店!'
}
### 数据字段
- `text`:评论文本使用双引号进行转义,内部的双引号会通过两个连续双引号转义;换行符则通过反斜杠加字符`n`(即`
`)进行转义。
- `label`:对应评论的星级评分,取值范围为1至5星。
### 数据划分
完整Yelp评论数据集的构建方式为:针对1至5星的每一类评论,随机选取13万条作为训练样本,1万条作为测试样本。最终总训练样本数为65万条,测试样本数为5万条。
## 数据集构建
### 数据集构建理据
完整Yelp评论数据集由张翔(xiang.zhang@nyu.edu)从2015年Yelp数据集挑战赛数据中整理而来,首次作为文本分类基准数据集出现在以下论文中:Xiang Zhang, Junbo Zhao, Yann LeCun. Character-level Convolutional Networks for Text Classification. Advances in Neural Information Processing Systems 28 (NIPS 2015).
### 源数据
#### 初始数据收集与标准化
[需补充更多信息]
#### 源语言创作者信息
[需补充更多信息]
### 标注信息
#### 标注流程
[需补充更多信息]
#### 标注人员信息
[需补充更多信息]
### 个人与敏感信息
[需补充更多信息]
## 数据集使用注意事项
### 数据集的社会影响
[需补充更多信息]
### 偏差分析
[需补充更多信息]
### 其他已知局限性
[需补充更多信息]
## 附加信息
### 数据集维护者
[需补充更多信息]
### 许可信息
可查阅官方的[Yelp数据集许可协议](https://s3-media3.fl.yelpcdn.com/assets/srv0/engineering_pages/bea5c1e92bf3/assets/vendor/yelp-dataset-agreement.pdf)。
### 引用信息
Xiang Zhang, Junbo Zhao, Yann LeCun. 字符级卷积网络用于文本分类. 神经信息处理系统进展 28 (NIPS 2015).
### 贡献者
感谢[@hfawaz](https://github.com/hfawaz)为本数据集的收录提供支持。