VGG Image Annotator
收藏www.robots.ox.ac.uk2024-11-05 收录
下载链接:
http://www.robots.ox.ac.uk/~vgg/software/via/
下载链接
链接失效反馈官方服务:
资源简介:
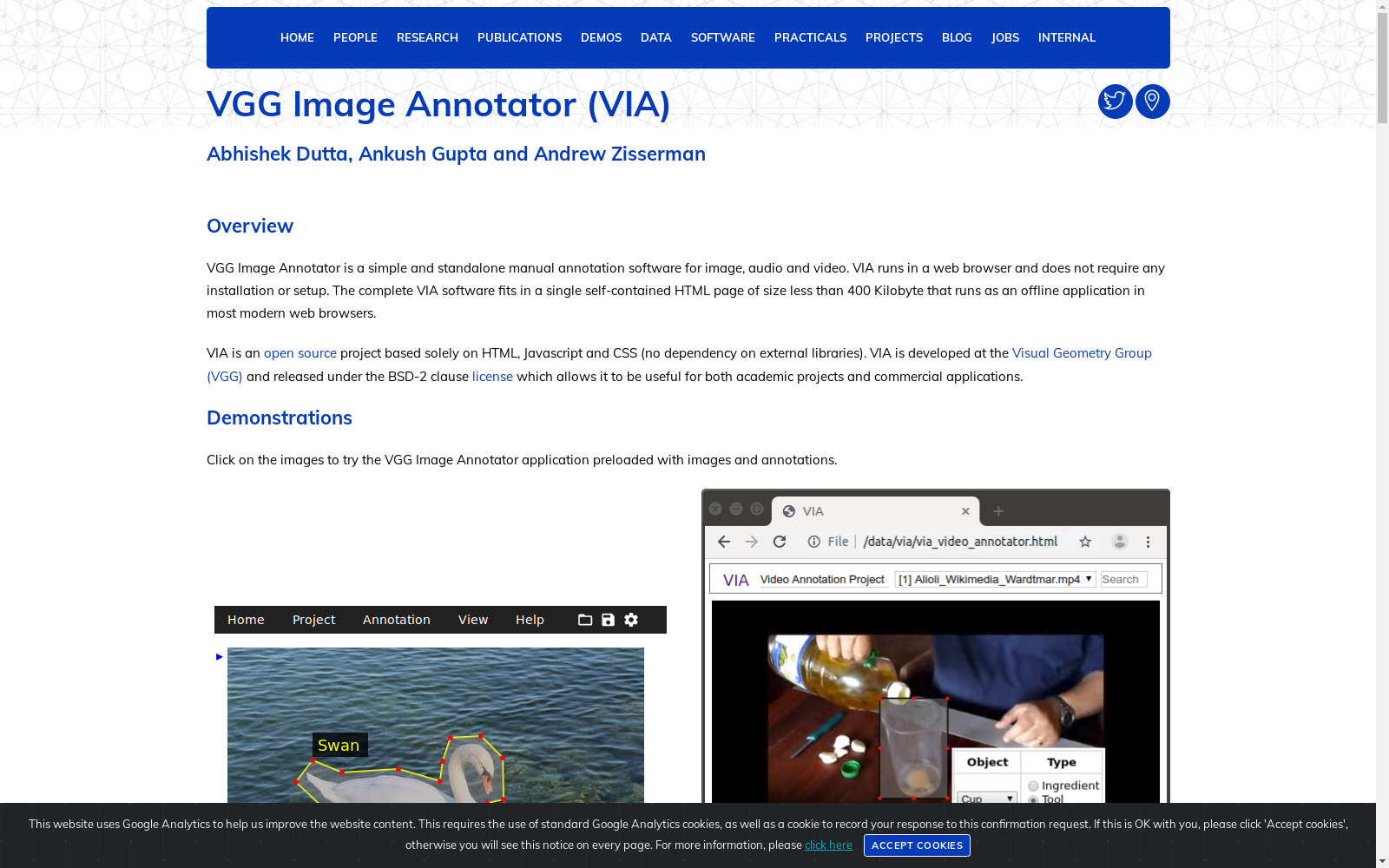
VGG Image Annotator(VIA)是一个用于图像标注的开源工具,用户可以使用它来创建、查看和编辑图像标注。该工具支持多种标注类型,包括矩形、多边形、点和折线等。VIA生成的标注数据可以导出为JSON格式,便于后续的机器学习和数据分析任务。
VGG Image Annotator (VIA) is an open-source tool for image annotation. Users can create, view, and edit image annotations with it. This tool supports various annotation types, including rectangles, polygons, points, polylines, and so forth. The annotation data generated by VIA can be exported in JSON format, which facilitates downstream machine learning and data analysis tasks.
提供机构:
www.robots.ox.ac.uk
搜集汇总
数据集介绍
构建方式
VGG Image Annotator(VIA)数据集的构建基于用户手动标注的图像数据。该数据集通过集成一个用户友好的图像标注工具,允许研究者和开发者对图像进行多边形、矩形、圆形等多种形状的标注。标注过程支持多种图像格式,并能实时保存标注结果,确保数据的完整性和一致性。通过这种方式,VIA数据集能够为计算机视觉任务提供高质量的标注数据,支持图像分类、目标检测和图像分割等多种应用。
特点
VGG Image Annotator数据集的主要特点在于其灵活性和易用性。该数据集支持多种标注形状,包括但不限于矩形、多边形和点,满足了不同应用场景的需求。此外,VIA工具的界面设计简洁直观,使得非专业用户也能轻松上手。数据集还支持自定义属性标注,增强了数据的语义信息。这些特点使得VIA数据集在计算机视觉领域中具有广泛的应用前景。
使用方法
使用VGG Image Annotator数据集时,用户首先需要通过VIA工具对图像进行标注,生成包含标注信息的JSON文件。随后,这些标注数据可以导入到各种机器学习框架中,如TensorFlow或PyTorch,用于训练模型。在实际应用中,VIA数据集常用于图像分类、目标检测和图像分割等任务。通过结合深度学习模型,VIA数据集能够显著提升计算机视觉任务的性能,为实际应用提供强有力的支持。
背景与挑战
背景概述
VGG Image Annotator(VIA)是由牛津大学视觉几何组(Visual Geometry Group, VGG)开发的一款开源图像标注工具,首次发布于2016年。该工具旨在解决大规模图像数据集标注中的效率和准确性问题,特别是在计算机视觉领域,如目标检测、图像分割和实例识别等任务中。VIA的出现极大地简化了图像标注流程,使得研究人员和工程师能够更快速地构建高质量的标注数据集,从而推动了相关研究的进展。
当前挑战
尽管VGG Image Annotator在图像标注领域取得了显著的成功,但其构建过程中仍面临诸多挑战。首先,用户界面的设计需要兼顾易用性和功能性,以满足不同用户的需求。其次,数据标注的一致性和准确性是一个持续的难题,尤其是在处理复杂场景和多类别目标时。此外,随着数据集规模的扩大,如何有效地管理和存储标注数据,以及如何确保标注过程的可追溯性和透明性,也是VIA需要解决的重要问题。
发展历史
创建时间与更新
VGG Image Annotator(VIA)数据集由牛津大学视觉几何组于2016年创建,旨在提供一个简单而强大的图像标注工具。该数据集自创建以来,经历了多次更新,最近一次重大更新是在2021年,进一步优化了用户界面和标注功能。
重要里程碑
VIA数据集的重要里程碑包括其在2017年首次公开发布,迅速成为图像标注领域的标准工具之一。2018年,VIA增加了对视频标注的支持,极大地扩展了其应用范围。2020年,VIA引入了基于Web的版本,使得用户无需安装即可在线使用,这一改进显著提升了其用户友好性和可访问性。
当前发展情况
当前,VGG Image Annotator数据集继续在图像和视频标注领域发挥重要作用。其开源性质和持续的更新确保了其在学术界和工业界的广泛应用。VIA不仅支持多种标注类型,还提供了丰富的插件和扩展功能,满足了不同用户的需求。此外,VIA的社区支持活跃,用户可以通过GitHub等平台获取最新的更新和帮助,进一步推动了其在相关领域的贡献和影响力。
发展历程
- VGG Image Annotator (VIA) 首次发布,由牛津大学视觉几何组开发,旨在提供一个简单易用的图像标注工具。
- VIA 2.0版本发布,引入了更多的标注功能和用户界面改进,增强了用户体验。
- VIA 3.0版本发布,增加了对视频标注的支持,扩展了其应用范围。
- VIA 4.0版本发布,进一步优化了性能,并增加了对多种图像格式的支持。
- VIA 5.0版本发布,引入了协作标注功能,使得团队合作更加高效。
- VIA 6.0版本发布,增加了对深度学习模型的集成,提升了自动化标注的能力。
常用场景
经典使用场景
在计算机视觉领域,VGG Image Annotator(VIA)数据集常用于图像标注任务。其经典使用场景包括目标检测、图像分割和实例分类等。通过VIA,研究人员可以高效地标注图像中的对象边界框、多边形区域和像素级掩码,从而为深度学习模型提供高质量的训练数据。
解决学术问题
VGG Image Annotator数据集解决了计算机视觉研究中数据标注的瓶颈问题。传统的手动标注方法耗时且易出错,而VIA提供了用户友好的界面和高效的标注工具,显著提升了标注效率和准确性。这使得研究人员能够更专注于模型设计和算法优化,推动了计算机视觉领域的快速发展。
衍生相关工作
基于VGG Image Annotator数据集,衍生了许多经典工作。例如,研究人员开发了自动标注工具,利用预训练模型辅助标注过程;还有工作探索了多模态数据融合,结合图像和文本信息进行更精准的标注。这些衍生工作进一步扩展了VIA的应用范围,推动了计算机视觉技术的进步。
以上内容由遇见数据集搜集并总结生成


