ILSVRC-2012
收藏arXiv2018-04-16 更新2024-06-21 收录
下载链接:
https://auto-da.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
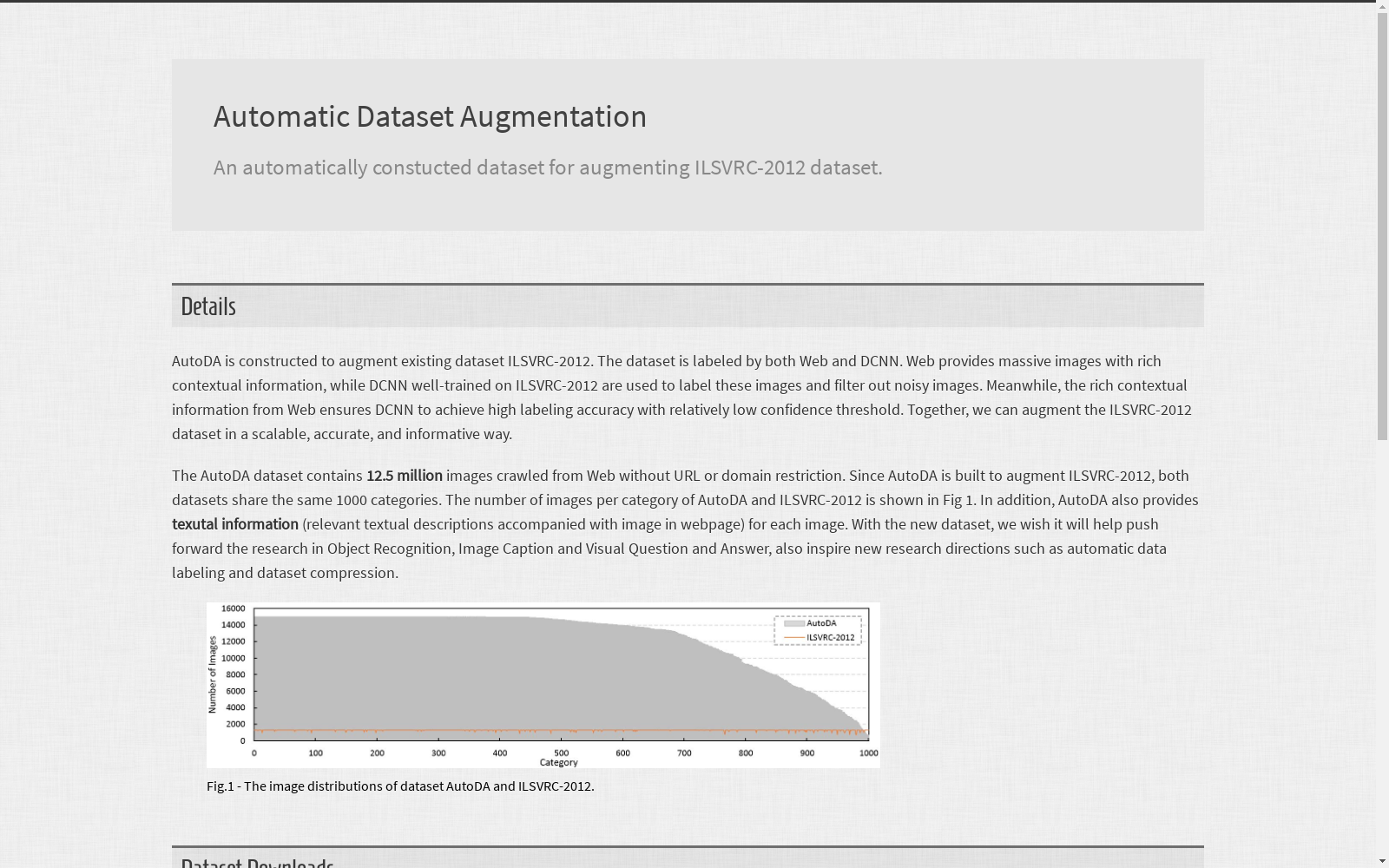
本研究中使用的数据集为ILSVRC-2012,由哈尔滨工业大学等机构创建,旨在通过自动数据增强技术提升图像识别任务的性能。该数据集通过网络获取了额外的1250万张图像,这些图像带有丰富的上下文信息,通过深度卷积神经网络(DCNN)进行自动标注。数据集的创建过程结合了网络的上下文信息和DCNN的视觉信息,以提高标注的准确性和数据集的丰富性。该数据集主要应用于图像识别领域,特别是通过自动增强现有数据集来接近预期误差,解决传统数据标注成本高和比较不公平的问题。
The dataset used in this study is ILSVRC-2012, developed by Harbin Institute of Technology and other institutions. It was constructed with the goal of enhancing the performance of image recognition tasks through automatic data augmentation techniques. The dataset collected an additional 12.5 million images from the web; these images carry rich contextual information and were automatically annotated using Deep Convolutional Neural Networks (DCNNs). The dataset's construction process combines the contextual information of these web-sourced images and the visual information processed by DCNNs, to improve annotation accuracy and enrich the dataset's diversity and comprehensiveness. This dataset is primarily applied in the field of image recognition, specifically to narrow the gap to the expected optimal error by automatically augmenting existing datasets, and to address the issues of high data annotation costs and unfair comparative evaluations in traditional data workflows.
提供机构:
哈尔滨工业大学
创建时间:
2017-08-28
搜集汇总
数据集介绍
构建方式
ILSVRC-2012数据集的构建基于大规模图像数据的自动增强方法。该方法结合了网络爬取和深度卷积神经网络(DCNN)的自动标注技术。首先,从互联网上爬取大量带有丰富上下文信息的图像,随后利用预训练的DCNN对这些图像进行自动标注。通过这种方式,数据集得以显著扩展,且标注成本大幅降低。实验表明,该方法能够从数十亿网页中高效地扩展数据集,并显著提升物体识别任务的性能。
特点
ILSVRC-2012数据集的特点在于其规模庞大且标注精度高。通过自动增强技术,数据集从原有的120万张图像扩展至1250万张,涵盖了1000个物体类别。此外,数据集的标注过程结合了网络上下文信息和DCNN的视觉信息,确保了标注的准确性和多样性。这种自动增强方法不仅降低了人工标注的成本,还显著提升了模型的泛化能力,使其在物体识别任务中表现优异。
使用方法
ILSVRC-2012数据集的使用方法主要包括训练深度卷积神经网络(DCNN)和评估模型性能。研究人员可以使用该数据集进行端到端的模型训练,并通过验证集评估模型的分类精度。此外,数据集还可用于研究自动标注技术的效果,以及探索大规模数据集对模型性能的影响。通过结合网络上下文信息和DCNN的视觉信息,研究人员可以进一步优化模型的训练过程,提升其在复杂场景下的识别能力。
背景与挑战
背景概述
ILSVRC-2012数据集是计算机视觉领域中一个具有里程碑意义的数据集,首次发布于2012年,由ImageNet项目团队创建。该数据集包含超过120万张标注图像,涵盖1000个类别,广泛应用于图像分类任务的研究。ILSVRC-2012的推出极大地推动了深度学习模型的发展,尤其是卷积神经网络(CNN)的进步。AlexNet在2012年的ILSVRC竞赛中取得了突破性成绩,标志着深度学习在计算机视觉领域的崛起。该数据集不仅为研究者提供了丰富的训练数据,还通过其年度竞赛促进了模型优化和创新。
当前挑战
ILSVRC-2012数据集在构建和应用过程中面临多重挑战。首先,图像分类任务本身具有较高的复杂性,尤其是在处理大规模、多样化的图像数据时,模型需要具备强大的泛化能力。其次,数据集的构建依赖于大量的人工标注,这导致了高昂的成本和时间消耗。此外,尽管数据集规模庞大,但其类别分布不均衡,某些类别的样本数量较少,可能影响模型的训练效果。最后,随着图像数据的不断更新,数据集的时效性也成为一大挑战,如何利用现有数据集提升模型对新数据的适应能力仍需进一步探索。
常用场景
经典使用场景
ILSVRC-2012数据集是计算机视觉领域中最为经典的图像分类基准数据集之一,广泛应用于深度卷积神经网络(DCNN)的训练与评估。该数据集包含超过120万张标注图像,涵盖1000个类别,为研究者提供了一个标准化的平台,用于验证和改进图像分类算法的性能。其经典使用场景包括模型训练、性能评估以及算法对比,尤其是在ImageNet大规模视觉识别挑战赛(ILSVRC)中,ILSVRC-2012数据集成为了推动深度学习技术发展的关键驱动力。
实际应用
ILSVRC-2012数据集在实际应用中具有广泛的影响力。首先,它为工业界提供了高质量的预训练模型,这些模型可以迁移到其他视觉任务中,如目标检测、图像分割和图像生成等。其次,基于该数据集训练的模型被广泛应用于图像搜索引擎、自动驾驶、医疗影像分析等领域。例如,在自动驾驶中,ILSVRC-2012数据集训练的模型能够帮助车辆识别道路上的行人、车辆和交通标志,从而提高驾驶安全性。此外,该数据集还为社交媒体平台提供了强大的图像分类能力,帮助用户更高效地管理和检索图像内容。
衍生相关工作
ILSVRC-2012数据集催生了许多经典的衍生研究工作。首先,基于该数据集,研究者提出了多种深度卷积神经网络架构,如AlexNet、VGGNet、GoogLeNet和ResNet,这些网络在图像分类任务中取得了突破性进展。其次,该数据集还推动了数据增强技术的发展,研究者通过自动化的方式从互联网中扩展数据集规模,从而进一步提升模型性能。此外,ILSVRC-2012还为细粒度图像分类、跨域迁移学习等新兴研究方向提供了基础数据支持。例如,基于该数据集的研究成果被广泛应用于鸟类识别、车辆分类等细粒度任务中,进一步拓展了计算机视觉的应用边界。
以上内容由遇见数据集搜集并总结生成


