hugfaceguy0001/LightNovelInfo
收藏Hugging Face2024-03-16 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/hugfaceguy0001/LightNovelInfo
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: id
dtype: int64
- name: title
dtype: string
- name: author
dtype: string
- name: introduction
dtype: string
- name: publisher
dtype: string
- name: length
dtype: string
splits:
- name: train
num_bytes: 2544581
num_examples: 3523
download_size: 1869762
dataset_size: 2544581
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: openrail
task_categories:
- text-classification
- question-answering
- summarization
- text2text-generation
- sentence-similarity
language:
- zh
tags:
- literature
- art
pretty_name: LightNovel
size_categories:
- 1K<n<10K
---
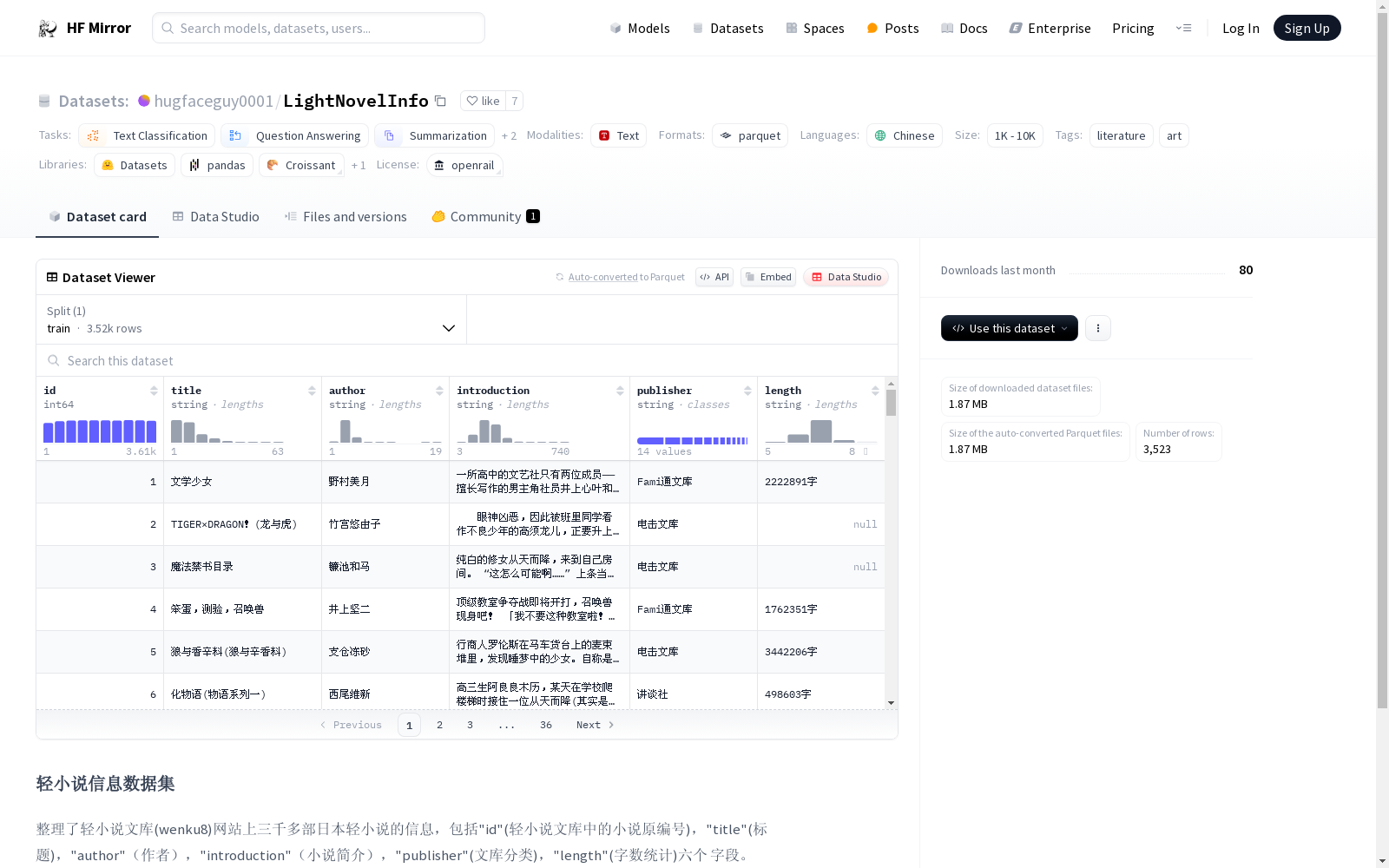
# 轻小说信息数据集
整理了轻小说文库(wenku8)网站上三千多部日本轻小说的信息,包括"id"(轻小说文库中的小说原编号),"title"(标题),"author"(作者),"introduction"(小说简介),"publisher"(文库分类),"length"(字数统计)六个
字段。
可用于信息检索,文本生成等任务。
数据集信息:
特征字段:
- 字段名称:id,数据类型:64位整数(int64)
- 字段名称:title,数据类型:字符串(string)
- 字段名称:author,数据类型:字符串(string)
- 字段名称:introduction,数据类型:字符串(string)
- 字段名称:publisher,数据类型:字符串(string)
- 字段名称:length,数据类型:字符串(string)
数据集划分:
- 划分名称:训练集(train),字节大小:2544581字节,样本数量:3523
下载大小:1869762字节
数据集总大小:2544581字节
配置项:
- 配置名称:默认(default)
数据文件:
- 对应划分:训练集,文件路径:data/train-*
开源协议:OpenRail
支持任务类别:
- 文本分类(text-classification)
- 问答(question-answering)
- 摘要生成(summarization)
- 文本到文本生成(text2text-generation)
- 句子相似度匹配(sentence-similarity)
支持语言:中文(zh)
标签:
- 文学(literature)
- 艺术(art)
展示名:轻小说(LightNovel)
样本规模分类:1000 < 样本量 < 10000
# 轻小说信息数据集
本数据集整理自轻小说文库(wenku8)网站的三千余部日本轻小说信息,包含六个字段:id(轻小说文库内的小说原编号)、title(小说标题)、author(作者)、introduction(小说简介)、publisher(文库分类)、length(字数统计)。
本数据集可应用于信息检索、文本生成等各类自然语言处理任务。
提供机构:
hugfaceguy0001
原始信息汇总
数据集概述
数据集名称
- 名称: 轻小说信息数据集
数据集特征
- 字段:
- id: int64
- title: string
- author: string
- introduction: string
- publisher: string
- length: string
数据集大小
- 训练集大小:
- 字节数: 2544581
- 示例数: 3523
- 下载大小: 1869762
- 数据集总大小: 2544581
数据集配置
- 默认配置:
- 训练数据路径: data/train-*
许可信息
- 许可证: openrail
任务类别
- 文本分类
- 问答
- 摘要生成
- 文本到文本生成
- 句子相似度
语言
- 中文 (zh)
标签
- 文学
- 艺术
数据集别名
- 别名: LightNovel
数据集规模
- 规模: 1K<n<10K
搜集汇总
数据集介绍
构建方式
该数据集的构建基于轻小说文库(wenku8)网站上丰富的日本轻小说资源,通过整合三千余部作品的信息,形成了包含'id'、'title'、'author'、'introduction'、'publisher'和'length'六个字段的综合性数据集。构建过程中,数据提取严格遵循轻小说文库的数据结构,确保了数据的一致性和准确性。
特点
本数据集具有鲜明的文学艺术特色,涵盖了轻小说的标题、作者、简介等关键信息,不仅便于信息检索,还为文本生成等任务提供了丰富的文本素材。其数据规模适中,便于各类文本处理任务的开展。此外,数据集遵循openrail协议,保证了数据的开放性和可访问性。
使用方法
用户可依据数据集提供的字段,进行文本分类、问答、摘要生成、文本到文本生成以及句子相似度等任务的研究与开发。使用时,需遵循数据集的许可协议,合法合规地利用数据。数据集可通过HuggingFace平台提供的接口进行下载和加载,为研究工作提供了便捷的数据处理流程。
背景与挑战
背景概述
在文本分类、信息检索以及自然语言处理领域,高质量的数据集对于算法模型的训练至关重要。LightNovelInfo数据集,创建于近年,由轻小说文库网站提供原始数据,主要研究人员不详,该数据集汇集了三千余部日本轻小说的详细信息,包括但不限于小说标题、作者、简介、分类及字数等,为研究者和开发者提供了一种宝贵资源。其影响力在文学信息处理和文本分析任务中逐渐显现,为相关领域的研究提供了坚实基础。
当前挑战
尽管LightNovelInfo数据集为研究提供了便利,但在构建和应用过程中也面临诸多挑战。首先,数据集的规模相较于大规模文本数据集而言较小,可能无法充分满足大规模模型训练的需求。其次,数据集的标注质量、一致性和准确性需要进一步验证。此外,如何从轻小说特有的文学特征中提取有效信息,以及如何将此数据集应用于更广泛的自然语言处理任务中,也是当前面临的挑战。
常用场景
经典使用场景
在文本生成领域,hugfaceguy0001/LightNovelInfo数据集以其丰富的轻小说资源,成为文本生成模型训练的宝贵素材。通过对该数据集的学习,模型能够捕捉到轻小说的语言风格和叙事结构,进而生成具有类似风格的新文本。
衍生相关工作
基于该数据集,研究者们开展了一系列相关工作,如情感分析、风格迁移、作者识别等,这些研究不仅丰富了文学研究领域的方法论,也为人工智能在文学领域的应用提供了新的视角和思路。
数据集最近研究
最新研究方向
在文本处理与自然语言理解的领域,hugfaceguy0001/LightNovelInfo数据集近期被广泛应用于文本分类、问题回答、文本摘要、文本生成以及句子相似度等任务。该数据集以其独特的文学性与艺术性,成为研究者在探讨文学文本处理方面的宝贵资源。当前,前沿研究方向聚焦于运用深度学习技术对轻小说文本进行情感分析、风格模仿及个性化推荐系统的研究,这不仅推动了文学作品的智能化分析,也为文化产品的数字化传播提供了新的视角。与此同时,此类研究在提升用户体验、丰富网络文学内容方面具有重要影响和意义。
以上内容由遇见数据集搜集并总结生成


