lmms-lab/COCO-Caption2017
收藏Hugging Face2024-03-08 更新2024-04-19 收录
下载链接:
https://hf-mirror.com/datasets/lmms-lab/COCO-Caption2017
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: question_id
dtype: string
- name: image
dtype: image
- name: question
dtype: string
- name: answer
sequence: string
- name: id
dtype: int64
- name: license
dtype: int8
- name: file_name
dtype: string
- name: coco_url
dtype: string
- name: height
dtype: int32
- name: width
dtype: int32
- name: date_captured
dtype: string
splits:
- name: val
num_bytes: 788752747.0
num_examples: 5000
- name: test
num_bytes: 6649116198.0
num_examples: 40670
download_size: 7444321699
dataset_size: 7437868945.0
configs:
- config_name: default
data_files:
- split: val
path: data/val-*
- split: test
path: data/test-*
---
<p align="center" width="100%">
<img src="https://i.postimg.cc/g0QRgMVv/WX20240228-113337-2x.png" width="100%" height="80%">
</p>
# Large-scale Multi-modality Models Evaluation Suite
> Accelerating the development of large-scale multi-modality models (LMMs) with `lmms-eval`
🏠 [Homepage](https://lmms-lab.github.io/) | 📚 [Documentation](docs/README.md) | 🤗 [Huggingface Datasets](https://huggingface.co/lmms-lab)
# This Dataset
This is a formatted version of [COCO-Caption-2017-version](https://cocodataset.org/#home). It is used in our `lmms-eval` pipeline to allow for one-click evaluations of large multi-modality models.
```
@misc{lin2015microsoft,
title={Microsoft COCO: Common Objects in Context},
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
year={2015},
eprint={1405.0312},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
提供机构:
lmms-lab
原始信息汇总
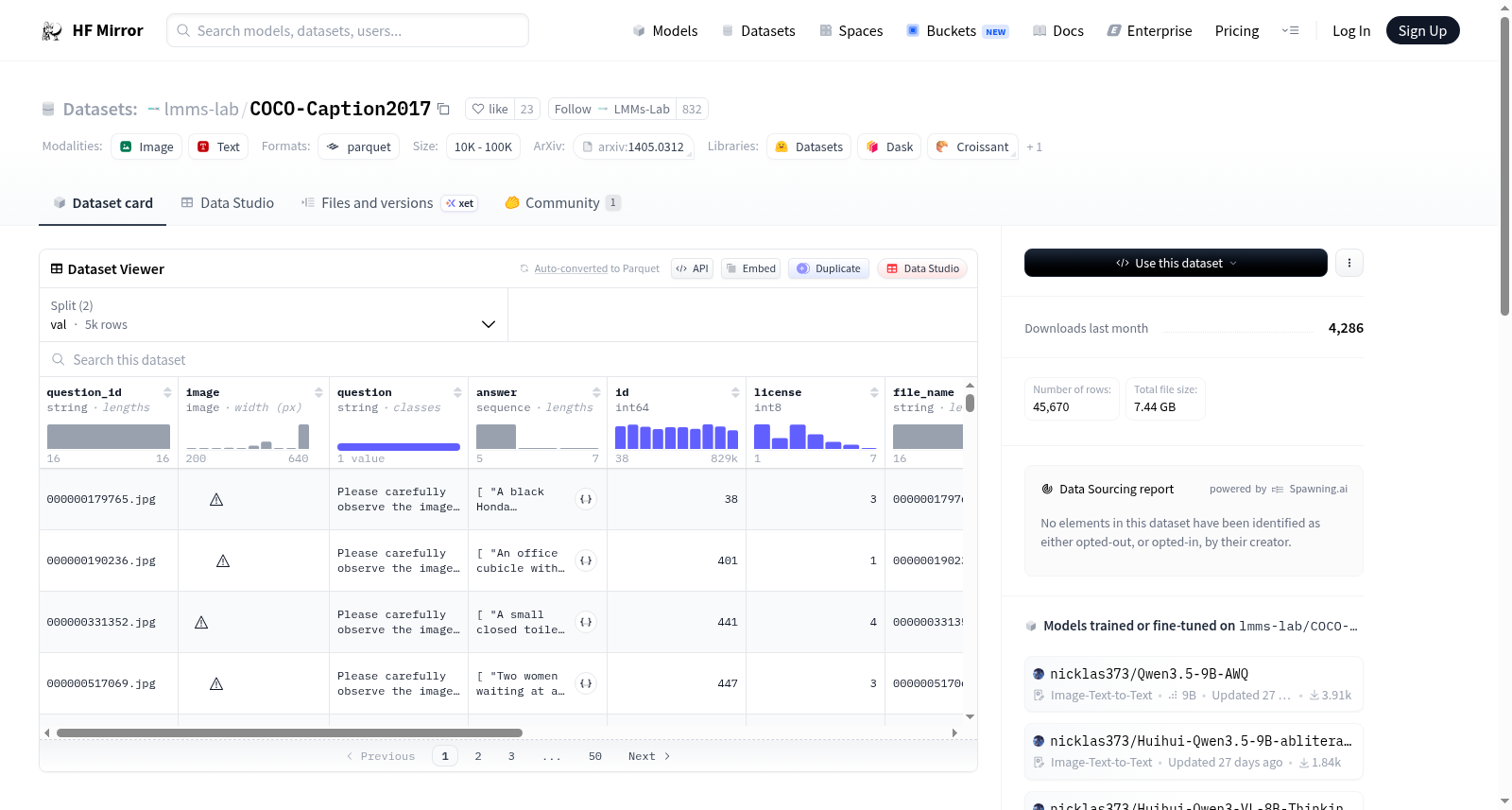
数据集概述
数据集信息
特征
- question_id: 字符串类型
- image: 图像类型
- question: 字符串类型
- answer: 字符串序列
- id: 64位整数类型
- license: 8位整数类型
- file_name: 字符串类型
- coco_url: 字符串类型
- height: 32位整数类型
- width: 32位整数类型
- date_captured: 字符串类型
数据分割
- val:
- 字节数: 788752747.0
- 样本数: 5000
- test:
- 字节数: 6649116198.0
- 样本数: 40670
数据大小
- 下载大小: 7444321699
- 数据集大小: 7437868945.0
配置
- default:
- val: data/val-*
- test: data/test-*
数据集来源
- 该数据集是COCO-Caption-2017-version的格式化版本,用于
lmms-eval流水线中,以便一键评估大型多模态模型。
搜集汇总
数据集介绍
背景与挑战
背景概述
This dataset is a curated collection of image-caption pairs from COCO-Caption-2017, optimized for evaluating multi-modality models. It includes diverse images each paired with multiple descriptive captions, facilitating comprehensive model assessment in image understanding and caption generation tasks.
以上内容由遇见数据集搜集并总结生成


