GPR1200
收藏arXiv2021-11-25 更新2024-06-21 收录
下载链接:
http://visual-computing.com/project/GPR1200
下载链接
链接失效反馈官方服务:
资源简介:
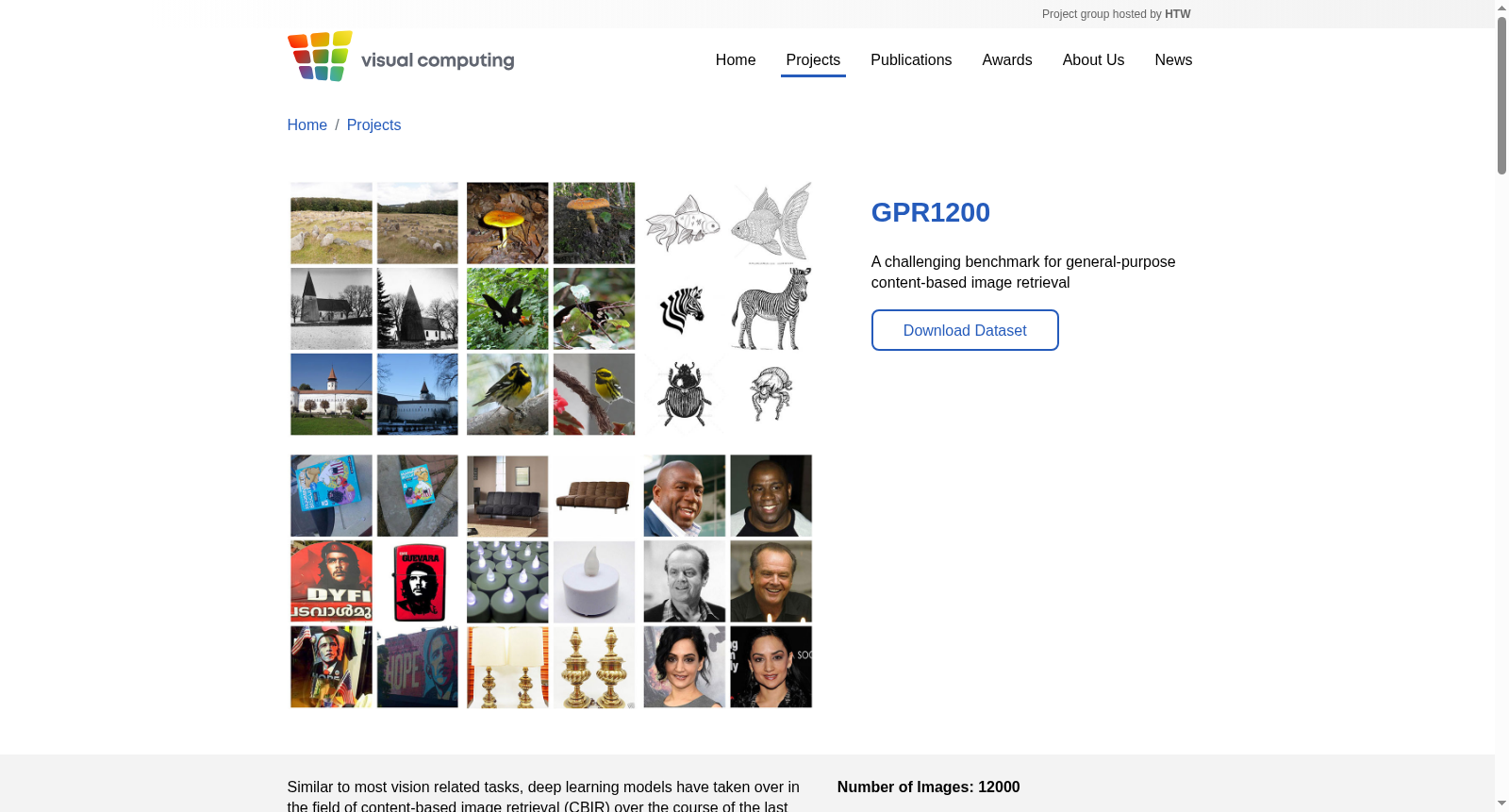
GPR1200是由柏林应用科技大学视觉计算组创建的一个通用目的内容基于图像检索的基准数据集。该数据集包含12000张图像,分为1200个类别,涵盖六个不同的图像领域,旨在评估模型在不同图像类别中的泛化能力。数据集通过手工挑选,确保了类别的平衡和检索任务的可解性。GPR1200的应用领域广泛,包括视觉相似性搜索和视频浏览工具等,旨在解决图像检索中的泛化问题。
GPR1200 is a general-purpose content-based image retrieval benchmark dataset created by the Visual Computing Group of Berlin University of Applied Sciences. This dataset contains 12,000 images divided into 1200 categories, covering six distinct image domains, and is designed to evaluate the generalization capability of models across different image categories. The dataset is manually curated to ensure category balance and the solvability of the retrieval task. GPR1200 has a wide range of application scenarios, including visual similarity search and video browsing tools, and aims to address the generalization challenges in image retrieval.
提供机构:
柏林应用科技大学视觉计算组
创建时间:
2021-11-25
搜集汇总
数据集介绍
构建方式
在通用内容图像检索领域,现有基准数据集往往局限于特定领域,难以全面评估模型的泛化能力。GPR1200的构建旨在填补这一空白,通过精心筛选六个不同图像领域的公开数据集,包括Google Landmarks V2、ImageNet Sketch、iNat、INSTRE、SOP和IMDB Faces,确保覆盖自然景观、素描、动植物、平面图像、商品和人脸等多样化类别。每个领域手动选取200个类别,每类包含10幅图像,总计1200类12000幅图像,严格排除类别重叠,并注重图像的可解性,确保人类标注者能够清晰区分不同类别。这一过程结合了自动特征筛选与人工审核,以平衡数据集的广泛代表性和评估可靠性。
特点
GPR1200数据集的核心特点在于其高度的领域多样性和均衡的类别分布,涵盖了从真实世界照片到人工绘制图像的广泛视觉内容。该数据集设计紧凑而富有挑战性,每个类别均经过手动筛选,确保图像在视觉上具有明确的区分度,避免了层级结构或多对象干扰,从而支持对模型在实例和类别级别检索能力的全面测试。此外,GPR1200提供了统一的评估协议,所有图像既作为查询也作为索引,无需额外划分,使用全平均精度(mAP)作为核心指标,并可计算各子领域的性能,以深入分析模型在不同领域的泛化表现。这种设计使其成为评估通用图像检索模型泛化能力的理想基准。
使用方法
使用GPR1200数据集时,研究人员需遵循其评估协议,将全部12000幅图像同时作为查询集和索引集,计算全平均精度(mAP)以衡量模型性能。模型在测试前不应使用GPR1200的任何组成部分进行训练,但允许使用相关数据集的训练分割进行预训练或微调。描述符后处理技术如L2归一化可被应用,但若涉及参数调优,需在其他独立数据上进行。通过分析各子领域(如地标、素描、自然等)的mAP结果,用户可以深入洞察模型在不同视觉领域的检索能力,从而推动通用内容图像检索模型的优化与创新。
背景与挑战
背景概述
在计算机视觉领域,基于内容的图像检索(CBIR)技术长期依赖于深度神经网络,然而现有研究多聚焦于特定领域(如地标图像)的模型训练与评估,缺乏面向通用场景的检索能力测试基准。为此,柏林工业大学视觉计算小组的Konstantin Schall等人于2021年推出了GPR1200数据集,旨在填补通用图像检索评估协议的空白。该数据集涵盖地标、自然、草图、物体、产品和面部六大领域,包含1200个类别共12000幅图像,通过手动筛选确保类别独立性与可解性,为促进通用CBIR模型的发展提供了标准化测试平台。
当前挑战
GPR1200数据集致力于解决通用图像检索中模型泛化能力不足的核心挑战,即如何使单一网络在多样化的视觉领域(如真实照片与平面图像)中均保持高效检索性能。在构建过程中,研究团队面临多重困难:需从异构数据源(如Google Landmarks V2、ImageNet Sketch等)中协调图像质量与领域覆盖度,同时通过人工标注排除类别重叠与低可解性样本,确保评估结果的严谨性。此外,数据集的平衡性与代表性要求对类别选择策略提出了极高要求,需在有限规模内实现跨域语义的广泛捕捉。
常用场景
经典使用场景
在基于内容的图像检索领域,GPR1200数据集作为一项基准测试工具,主要用于评估深度学习模型在跨域图像检索任务中的泛化能力。该数据集涵盖了地标、自然场景、素描、物体、产品和人脸六大类别,共计1200个类别和12000张图像,其精心设计的类别平衡与图像选择机制,使得研究者能够系统性地检验模型在面对多样化视觉内容时的检索性能。通过这一数据集,研究人员可以对比不同网络架构在通用图像检索任务上的表现,从而推动模型优化与创新。
解决学术问题
GPR1200数据集解决了图像检索研究中长期存在的领域局限性问题。传统检索模型通常在特定领域(如地标或产品图像)上进行训练与测试,导致其泛化能力不足,难以适应现实世界中多变的图像内容。该数据集通过整合多个来源的跨域图像,并确保类别的独特可解性,为评估模型的通用检索性能提供了标准化基准。其意义在于促进了通用目的CBIR模型的发展,推动了检索技术从领域特定向通用化的转变,对计算机视觉研究的进步产生了深远影响。
衍生相关工作
GPR1200数据集的推出激发了多项相关研究,尤其是在通用图像检索模型的训练与评估方面。基于该数据集,研究者探索了大规模预训练(如ImageNet21k)与特定损失函数(如ProxyAnchor损失)的结合,以提升模型的跨域检索性能。此外,一些工作进一步优化了网络架构(如Swin Transformer和EfficientNetV2),并验证了多数据集联合训练策略的有效性。这些衍生研究不仅深化了对通用CBIR模型的理解,也为后续的基准数据集设计和检索算法创新提供了重要参考。
以上内容由遇见数据集搜集并总结生成


