Multi-Dimensional Insights (MDI) Benchmark
收藏arXiv2024-12-17 更新2024-12-19 收录
下载链接:
https://mdi-benchmark.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
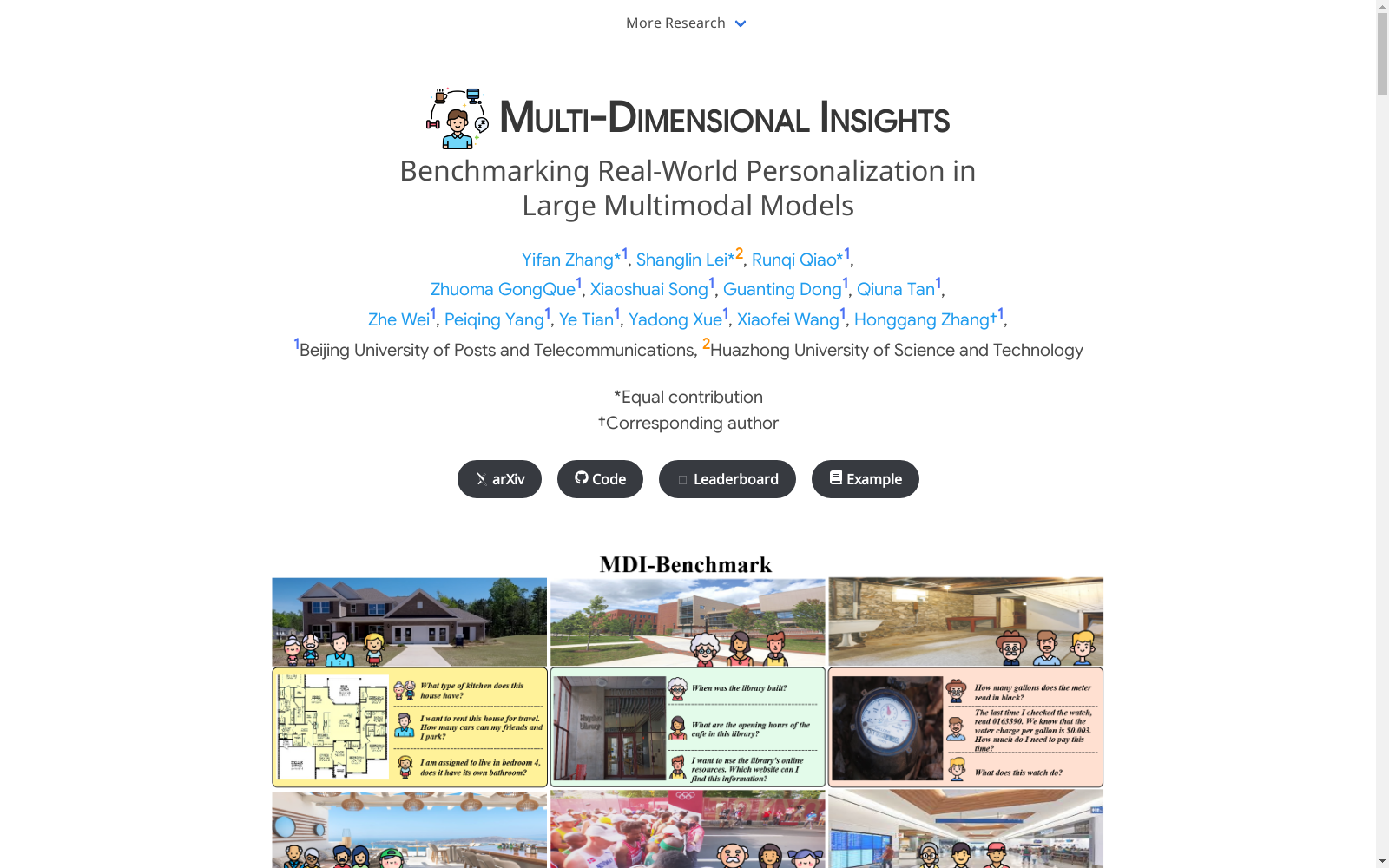
Multi-Dimensional Insights (MDI) Benchmark 是一个用于评估大型多模态模型(LMMs)在真实世界场景中个性化能力的数据集。该数据集包含超过500张真实世界的图像和1298个人工提出的问题,涵盖了六个主要的生活场景。数据集通过复杂性和年龄两个维度进行分类,旨在评估模型在不同年龄段和问题复杂度下的表现。数据集的创建过程包括图像收集、问题生成和多轮验证,确保数据的多样性和平衡性。该数据集主要用于解决LMMs在实际应用中对不同用户需求的个性化响应问题。
Multi-Dimensional Insights (MDI) Benchmark is a dataset developed to evaluate the personalized capabilities of large multimodal models (LMMs) in real-world scenarios. It comprises over 500 real-world images and 1,298 manually authored questions, spanning six core daily life scenarios. The dataset is categorized along two dimensions: question complexity and age cohort, with the objective of assessing model performance across different age groups and varying levels of question complexity. The construction of this benchmark involves three key phases: image collection, question generation, and multi-round validation, to guarantee the diversity and balanced distribution of the collected data. This benchmark is primarily intended to address the challenge of enabling LMMs to deliver personalized responses tailored to diverse user requirements in practical real-world applications.
提供机构:
北京邮电大学, 华中科技大学
创建时间:
2024-12-17
搜集汇总
数据集介绍
构建方式
Multi-Dimensional Insights (MDI) Benchmark 数据集通过精心设计的流程构建,涵盖了六个常见的生活场景,包括建筑、教育、家务、社会服务、体育和交通。数据集包含超过500张真实世界的图像和1200多个由人类提出的问题,这些问题根据复杂性分为两级:基础级和复杂级。此外,问题还根据年龄段分为年轻人、中年人和老年人三个类别,以评估多模态模型在不同年龄群体中的适应性。数据收集过程中,研究团队首先确定了场景维度信息,并通过人工和模型生成的描述作为关键词,从互联网上搜索相关图像。随后,志愿者对图像进行分类,并生成与图像内容相关的问题和答案,确保数据集的多样性和平衡性。
特点
MDI-Benchmark 数据集的主要特点在于其多维度的评估设计,涵盖了场景、问题复杂性和年龄三个维度。首先,数据集通过六个真实生活场景的图像,确保了评估的实际应用性。其次,问题分为基础和复杂两级,分别评估模型的基础理解和高级推理能力。最后,通过年龄分层,数据集能够细致地评估模型在不同年龄群体中的表现,从而反映其在个性化需求上的适应能力。这种多维度的设计使得MDI-Benchmark成为评估多模态模型在实际应用中表现的综合工具。
使用方法
MDI-Benchmark 数据集适用于评估和训练多模态模型,特别是那些旨在处理复杂任务和个性化需求的模型。使用该数据集时,研究人员可以通过提供的图像和问题对模型进行测试,评估其在不同场景、问题复杂性和年龄段中的表现。具体使用方法包括:首先,将图像和问题输入模型,要求模型生成答案;其次,根据预设的评分标准对模型的回答进行评估,计算其在基础和复杂问题上的准确率;最后,通过分析模型在不同维度上的表现,研究人员可以识别模型的优势和不足,进而优化模型的设计和训练策略。
背景与挑战
背景概述
随着大规模多模态模型(LMMs)领域的迅速发展,涌现出众多具备卓越能力的模型。然而,现有基准测试未能全面、客观且准确地评估这些模型在现实场景中是否能够满足人类的多样化需求。为此,北京邮电大学和华中科技大学的研究团队于2024年提出了Multi-Dimensional Insights (MDI) Benchmark。该数据集包含超过500张涵盖六种常见生活场景的图像,并设计了两类问题:简单问题用于评估模型的基本理解能力,复杂问题则用于评估其分析和推理能力。此外,MDI-Benchmark还根据不同年龄段的需求,将问题分为年轻人、中年人和老年人三类,以全面评估模型在不同年龄群体中的适应性。该数据集的提出为LMMs在现实场景中的个性化应用提供了新的评估标准,推动了多模态模型在实际应用中的进一步发展。
当前挑战
MDI-Benchmark的构建面临多重挑战。首先,如何设计能够全面评估LMMs在现实场景中适应性的问题是一个关键难题。其次,数据集的构建过程中,如何确保图像和问题的多样性以及不同年龄段需求的准确反映,也是一项复杂的任务。此外,现有LMMs在处理复杂问题和跨年龄段需求时仍存在显著不足,GPT-4o在年龄相关任务上的准确率仅为79%,表明现有模型在应对现实应用时仍有较大提升空间。未来研究需进一步解决模型在复杂推理、跨年龄段适应性以及多场景应用中的能力提升问题。
常用场景
经典使用场景
MDI-Benchmark 数据集的经典使用场景在于评估大型多模态模型(LMMs)在现实世界中的个性化能力。该数据集通过包含超过500张涵盖六个常见生活场景的图像,以及针对不同年龄段(年轻人、中年人和老年人)的复杂问题,全面评估模型在图像理解、逻辑推理和知识应用等方面的能力。
解决学术问题
MDI-Benchmark 数据集解决了现有基准在评估大型多模态模型时无法全面反映其在现实世界中个性化需求的问题。通过引入年龄维度和问题复杂度维度,该数据集能够更细致地评估模型在不同年龄段和复杂任务中的表现,为学术界提供了研究模型个性化能力的新途径。
衍生相关工作
MDI-Benchmark 数据集的提出激发了大量相关研究,特别是在多模态模型评估和个性化AI助手开发领域。例如,后续研究通过扩展数据集的场景和任务类型,进一步提升了模型的泛化能力。此外,基于该数据集的研究还推动了多模态模型在教育、医疗和社交服务等领域的实际应用。
以上内容由遇见数据集搜集并总结生成


