hssd_train_dataset
收藏Hugging Face2025-04-28 更新2025-04-29 收录
下载链接:
https://huggingface.co/datasets/limingme/hssd_train_dataset
下载链接
链接失效反馈官方服务:
资源简介:
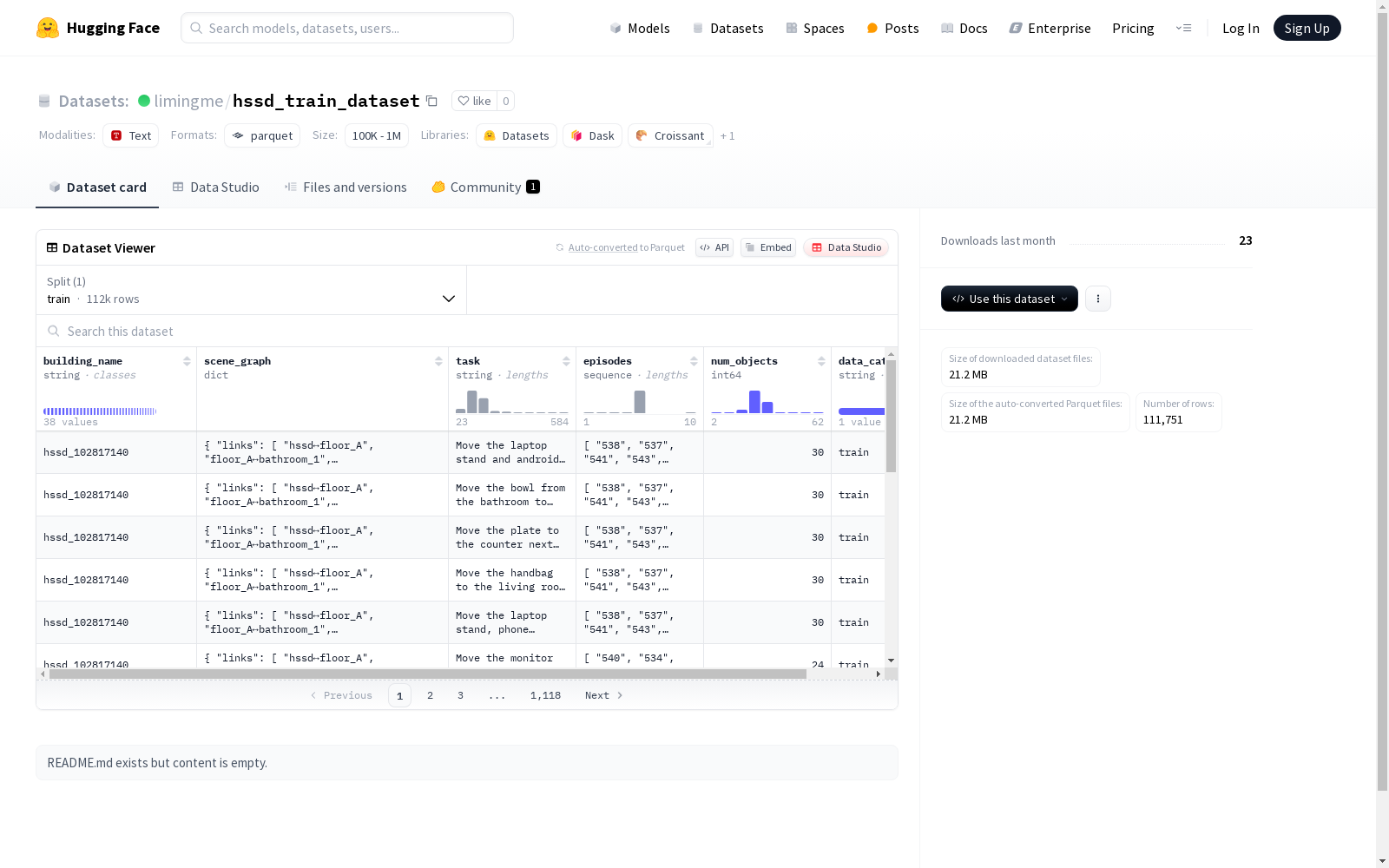
该数据集是一个包含建筑场景信息的集合,其中包括建筑名称(building_name)、场景图(scene_graph,包含links和nodes)、任务类型(task)、剧集(episodes)、对象数量(num_objects)和数据类别(data_category)。场景图中的nodes包含代理人(agent)、资产(asset)、建筑(building)、楼层(floor)、物体(object)和房间(room)等信息,每个信息包含不同的属性,如ID、位置、可用性、状态等。数据集分为训练集,其大小为769,336,508字节,共有111,751个示例。
创建时间:
2025-04-27
原始信息汇总
数据集概述
基本信息
- 数据集名称: limingme/hssd_train_dataset
- 下载大小: 21,227,081 bytes
- 数据集大小: 769,336,508 bytes
- 训练集样本数: 111,751
- 训练集大小: 769,336,508 bytes
数据结构
特征
-
building_name
- 类型: string
-
scene_graph
- links
- 类型: sequence of string
- nodes
- agent
- id: string
- location: string
- asset
- affordances: sequence of string
- attributes: sequence of null
- id: string
- room: string
- building
- id: string
- floor
- id: string
- object
- affordances: sequence of string
- id: string
- parent: string
- room: string
- states
- is_clean: bool
- is_filled: bool
- is_powered_on: bool
- type: string
- room
- id: string
- agent
- links
-
task
- 类型: string
-
episodes
- 类型: sequence of string
-
num_objects
- 类型: int64
-
data_category
- 类型: string
数据划分
- 训练集: 包含111,751个样本
搜集汇总
数据集介绍
构建方式
hssd_train_dataset的构建基于对建筑场景的深度结构化解析,采用场景图(scene graph)作为核心数据表示形式。研究团队通过多维度标注体系,将建筑环境分解为agent、asset、building等实体节点,并建立节点间的语义关联。每个实体节点均包含ID、位置等基础属性,对象节点还标注了affordances功能属性和states状态属性,形成层次化的三维场景表征。数据采集过程严格遵循标准化协议,确保场景信息的完整性和一致性。
特点
该数据集以111,751个训练样本构成,其突出特点在于精细的场景图结构和丰富的语义标注。每个样本包含建筑物名称、任务描述和场景交互序列,其中对象节点具备功能属性(affordances)和动态状态(is_clean/is_powered_on等)双重标注。数据采用层次化组织方式,从建筑、楼层到房间形成空间嵌套关系,对象间通过parent字段建立拓扑连接。特别值得注意的是对物体功能性的量化描述,为场景理解研究提供了多维度的分析基准。
使用方法
使用该数据集时,建议通过HuggingFace数据加载器按train分割读取数据文件。典型应用场景包括场景图生成、三维场景理解等计算机视觉任务。研究人员可利用scene_graph字段中的节点关系构建图神经网络,结合objects的affordances属性进行功能推理。对于动态状态分析,可通过states字段研究环境交互逻辑。数据集的episodes序列为时序相关研究提供了连续帧的上下文信息,适合用于具身智能等前沿领域的算法验证。
背景与挑战
背景概述
hssd_train_dataset是一个专注于室内场景理解与任务导向型智能体交互的数据集,由专业研究团队构建,旨在推动智能体在复杂室内环境中的感知与决策能力。该数据集通过精细标注的建筑名称、场景图以及任务描述等特征,为研究者提供了丰富的结构化数据,涵盖了智能体、物体、房间等多层次语义信息。其核心研究问题聚焦于如何让智能体在动态变化的室内场景中理解物体功能、空间关系以及任务上下文,对智能家居、服务机器人等领域的算法开发具有重要价值。
当前挑战
该数据集面临的挑战主要体现在两个方面:在领域问题层面,如何准确建模物体功能属性(affordances)与动态状态(如清洁度、电源状态)的复杂关联,以及如何解析多层级场景图(包含建筑、楼层、房间、物体等)中的空间与逻辑关系;在构建过程层面,数据标注涉及大量细粒度物体属性与状态信息,需要克服标注一致性与完整性的难题,同时场景图的复杂结构对数据存储与检索效率提出了较高要求。
常用场景
经典使用场景
在智能家居与室内场景理解领域,hssd_train_dataset以其丰富的场景图结构和多维度物体属性标注,成为研究空间语义解析的首选基准数据集。该数据集通过构建包含建筑、楼层、房间、物体的层次化场景图,支持对复杂室内环境中物体功能、空间关系及状态变化的系统性研究。研究者可基于场景图节点间的拓扑连接,分析智能体在动态环境中的行为模式与物体交互逻辑。
解决学术问题
该数据集有效解决了室内场景理解中三维空间语义建模的难题,其细粒度的物体功能标注(affordances)和状态变量(is_clean/is_powered_on等)为可操作物体识别研究提供了量化基准。通过融合建筑学拓扑结构与计算机视觉特征,推动了具身智能领域在真实场景中的导航、物体操作等任务的算法验证,填补了传统数据集在功能语义与物理状态联合建模方面的空白。
衍生相关工作
该数据集已催生多个具身智能领域的创新研究,包括基于图神经网络的场景理解框架SceneGraphNet、融合功能语义的强化学习算法AffordanceRL等。在CVPR等顶会中,多篇论文利用其层次化标注体系开发了联合建模空间拓扑与物体功能的混合模型,推动了室内场景数字化重建技术的标准化进程。
以上内容由遇见数据集搜集并总结生成


