hamsa-asr-small-21k
收藏Hugging Face2025-12-09 更新2025-12-10 收录
下载链接:
https://huggingface.co/datasets/nadsoft/hamsa-asr-small-21k
下载链接
链接失效反馈官方服务:
资源简介:
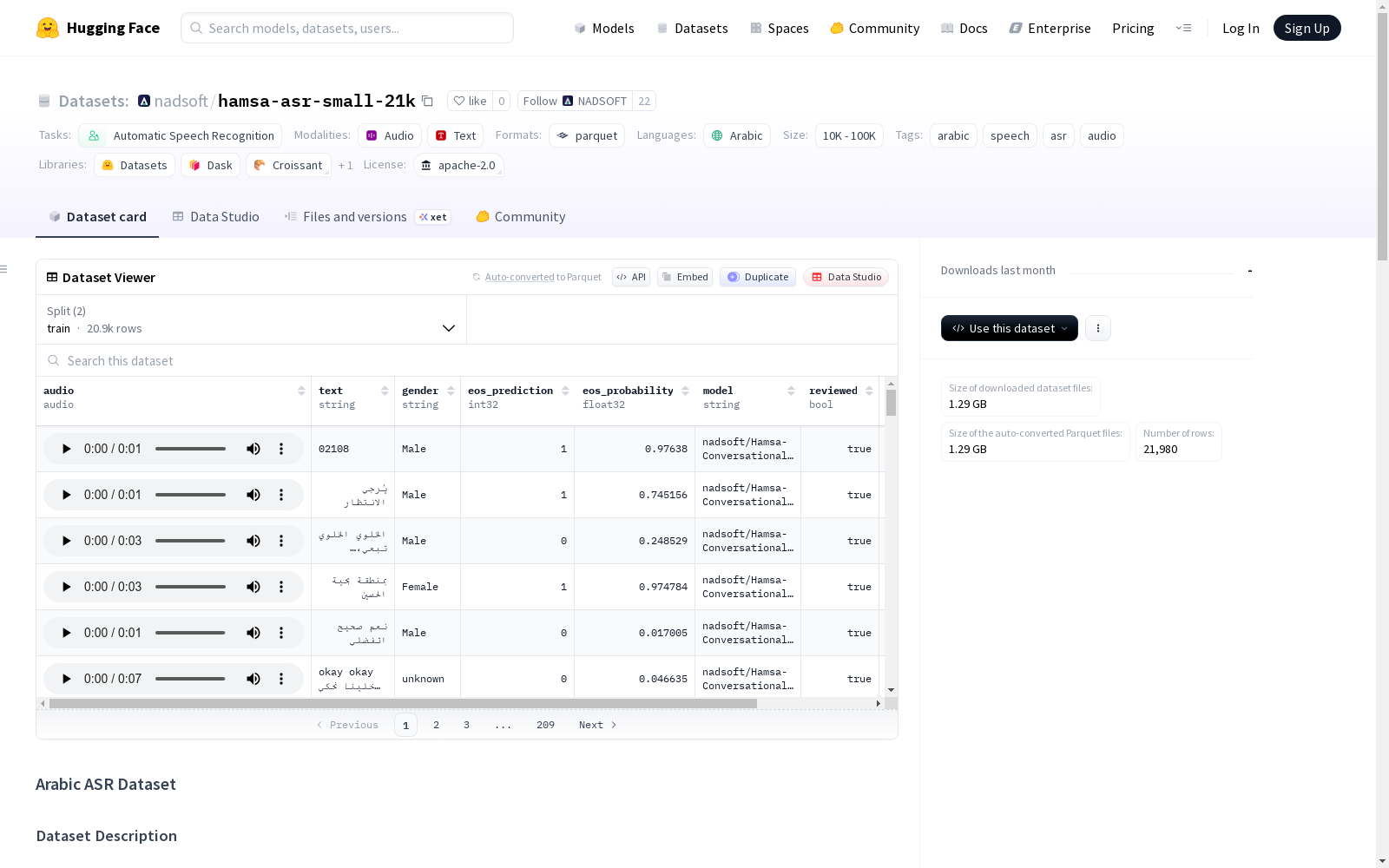
该数据集包含用于自动语音识别(ASR)任务的阿拉伯语语音录音及其转录文本。数据集总样本数为21980个,其中训练样本20880个,测试样本1100个。音频格式为WAV(16kHz采样率)。数据集提供了丰富的特征,包括音频、文本、说话者性别、句子结束预测、模型信息等。转录文本由nadsoft/Hamsa-Conversational-v1.0-mulaw模型生成,部分文本经过人工审核。数据集适用于阿拉伯语语音识别任务。
提供机构:
NADSOFT
创建时间:
2025-12-09
原始信息汇总
数据集概述
基本信息
- 数据集名称: Arabic ASR Dataset
- 数据集标识: nadsoft/hamsa-asr-small-21k
- 语言: 阿拉伯语 (ar)
- 主要任务: 自动语音识别 (Automatic Speech Recognition)
- 许可证: Apache 2.0
- 数据规模: n<1K (样本数少于1,000)
数据集统计
- 总样本数: 21,980
- 训练集样本数: 20,880
- 测试集样本数: 1,100
- 音频格式: WAV
- 采样率: 16kHz
数据特征
| 特征 | 类型 | 描述 |
|---|---|---|
audio |
Audio | 音频录音 (16kHz) |
text |
string | 阿拉伯语转录文本 |
gender |
string | 说话者性别 (Male/Female/Unknown) |
eos_prediction |
int32 | 句子结束预测 (0/1) |
eos_probability |
float32 | 句子结束概率 |
model |
string | 用于预测的模型名称 |
reviewed |
bool | 转录文本是否已被审阅 |
duration |
float32 | 音频时长 (秒) |
ignore |
bool | 是否应忽略此样本 |
音频字段详情
- audio: 一个包含以下内容的字典:
path: 音频文件路径array: 音频数组sampling_rate: 采样率 (16000 Hz)
其他说明
- 转录生成模型:
nadsoft/Hamsa-Conversational-v1.0-mulaw - 忽略样本处理: 当
ignore字段为 True 时,text字段内容为 "no-text"。
搜集汇总
数据集介绍
构建方式
在阿拉伯语自动语音识别领域,数据集的构建通常依赖于高质量的语音采集与精准的文本转录。本数据集通过整合阿拉伯语语音录音及其对应文本,形成了专为ASR任务设计的语料库。其构建过程涉及音频的录制与标准化处理,所有音频均以WAV格式保存,采样率为16kHz,确保了语音信号的清晰与一致。转录文本的生成借助了特定模型nadsoft/Hamsa-Conversational-v1.0-mulaw,部分样本经过人工审核以提升标注质量,同时数据集包含了性别、句子结束预测等元数据,增强了数据的多维可用性。
特点
该数据集在阿拉伯语语音识别资源中展现出显著特点,其规模适中,包含21,980个样本,划分为20,880个训练样本和1,100个测试样本,便于模型训练与评估。数据特征丰富,不仅提供音频和阿拉伯语文本,还涵盖说话者性别、句子结束预测概率及审核状态等信息,这些元数据支持更精细的语音分析。音频格式统一为16kHz采样率的WAV文件,保证了数据处理的便捷性,而ignore标志则允许用户灵活筛选样本,适应不同研究需求。
使用方法
对于研究人员和开发者而言,使用本数据集进行阿拉伯语语音识别实验十分便捷。通过Hugging Face的datasets库,可直接加载数据集并访问训练与测试分割。加载后,用户可轻松提取音频数组和对应文本,进行模型训练或评估。示例代码展示了如何访问首个样本的音频和转录内容,同时元数据如性别和审核状态可用于数据过滤或分析,为构建高效ASR系统提供了坚实基础。
背景与挑战
背景概述
阿拉伯语自动语音识别(ASR)作为自然语言处理领域的重要分支,其发展长期受限于高质量标注数据的稀缺性。HAMSA-ASR-SMALL-21K数据集由NADSoft机构构建,旨在为阿拉伯语ASR任务提供结构化的语音-文本配对资源。该数据集包含约2.2万条标注样本,覆盖男女声等多维度特征,其核心研究问题聚焦于提升阿拉伯语语音转写的准确性与鲁棒性,对推动中东地区语言技术平等化进程具有实质性意义。
当前挑战
阿拉伯语ASR领域面临方言多样性、音素复杂性及标注标准不统一等固有挑战,该数据集需解决非标准发音与书面语差异导致的识别误差问题。在构建过程中,数据采集受限于录音设备异构性,语音质量参差不齐;转录环节依赖自动模型生成初稿,虽经部分人工审核,但仍存在语义歧义校正与噪声过滤的双重压力,同时性别平衡与口音覆盖的全面性亦构成数据代表性的潜在制约。
常用场景
经典使用场景
在阿拉伯语语音识别领域,该数据集为研究人员提供了高质量的语音-文本对齐资源,经典使用场景包括训练和评估端到端自动语音识别模型。通过包含超过两万条标注样本,它支持从声学建模到语言建模的全流程实验,尤其在处理阿拉伯语特有的语音变体和口音方面展现出重要价值,为构建鲁棒的ASR系统奠定了数据基础。
解决学术问题
该数据集有效解决了阿拉伯语ASR研究中数据稀缺和质量不均的学术难题。它通过提供大规模、结构化的语音转录对,促进了低资源语言语音技术的公平发展,并支持跨性别、跨口音的模型泛化研究。其细致的元数据标注,如句子边界预测和人工审核标志,为探索语音分段、噪声鲁棒性等核心问题提供了实证支撑,推动了多模态语言处理的理论进展。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作,包括基于Hamsa-Conversational模型的语音识别流水线优化,以及针对阿拉伯语语音特征的声学模型适配。这些工作进一步探索了多说话人场景下的识别鲁棒性,并利用其句子边界预测特征开发了端到端语音分段算法,为后续的低资源语言ASR研究提供了可复现的基准和创新的方法论启示。
以上内容由遇见数据集搜集并总结生成


