dense scene-description dataset
收藏arXiv2026-03-13 更新2026-03-14 收录
下载链接:
https://liuff19.github.io/Spatial-TTT
下载链接
链接失效反馈官方服务:
资源简介:
该数据集由清华大学与腾讯混元联合构建,包含密集的3D空间描述信息,旨在为模型提供结构化全局空间信号。数据内容覆盖场景上下文、物体数量及空间关系,通过视频流中的几何对应性和时间连续性监督模型权重更新。其构建过程结合了长时序视频分析与空间预测机制,应用于增强多模态大模型的流式空间理解能力,解决机器人导航、自动驾驶等场景中的长视野空间推理问题。
This dataset was jointly constructed by Tsinghua University and Tencent Hunyuan, which contains dense 3D spatial description information. It is intended to provide structured global spatial signals for models. The data covers scene context, object quantities and spatial relationships, and supervises model weight updates by leveraging geometric correspondence and temporal consistency within video streams. The dataset's construction integrates long-sequence video analysis and spatial prediction mechanisms, aiming to boost the streaming spatial understanding capabilities of multimodal large language models (LLMs) and address long-horizon spatial reasoning problems in scenarios such as robot navigation and autonomous driving.
提供机构:
清华大学; 腾讯混元; 南洋理工大学
创建时间:
2026-03-13
原始信息汇总
Spatial-TTT 数据集概述
数据集名称
Spatial-TTT
核心目标
用于流式视觉空间智能研究,通过测试时训练(TTT)从流式视频块中维护和更新空间状态,以回答空间问题。
关键方法
- 测试时训练(TTT):使用快速权重作为紧凑的非线性记忆,在长时程自我中心视频上运行。
- 混合架构:结合大块更新与滑动窗口注意力,以实现高效的空间视频处理。
- 空间预测机制:在TTT层中使用3D时空卷积来捕捉几何对应关系和时间连续性。
- 密集场景监督:构建了一个包含密集3D空间描述的数据集,以指导快速权重以结构化方式记忆和组织全局3D空间信号。
主要贡献
- 作为空间记忆的快速权重:自适应快速权重作为紧凑的非线性记忆,通过在线更新持续编码空间证据,实现无界视频流上的亚线性内存增长。
- 空间预测机制:应用深度3D卷积,使快速权重学习时空上下文之间的预测映射,而非孤立标记,从而捕捉几何对应关系。
- 密集场景监督数据集:构建了一个包含全局上下文、对象与计数、空间关系的密集场景描述数据集,为快速权重更新动态提供丰富的监督。
实验评估
- VSI-Bench:在自我中心视频(ScanNet, ScanNet++, ARKitScenes)上进行通用空间理解评估,报告多项选择题的准确率(ACC)和数值问题的平均相对准确率(MRA)。
- VSI-SUPER: Recall & Count:在长时程视频上进行流式空间感知评估。VSR测试插入对象时间顺序的回忆;VSC测试跨扩展序列的对象计数。
- 内存与计算扩展:与输入长度相关的峰值解码内存和理论TFLOPs。Spatial-TTT实现了近线性扩展;在1024帧时,与Qwen3-VL-2B相比,TFLOPs和内存均减少超过40%。
相关资源
- 论文:https://arxiv.org/abs/2603.12255
- 代码与模型:页面中提供了相关链接(具体地址未在提供内容中给出)。
引用信息
@article{spatialttt2026, title = {Spatial-TTT: Streaming Visual-based Spatial Intelligence with Test-Time Training}, author = {Liu, Fangfu and Wu, Diankun and Chi, Jiawei and Cai, Yimo and Hung, Yi-Hsin and Yu, Xumin and Li, Hao and Hu, Han and Rao, Yongming and Duan, Yueqi}, journal = {arXiv preprint arXiv:2603.12255}, year = {2026} }
搜集汇总
数据集介绍
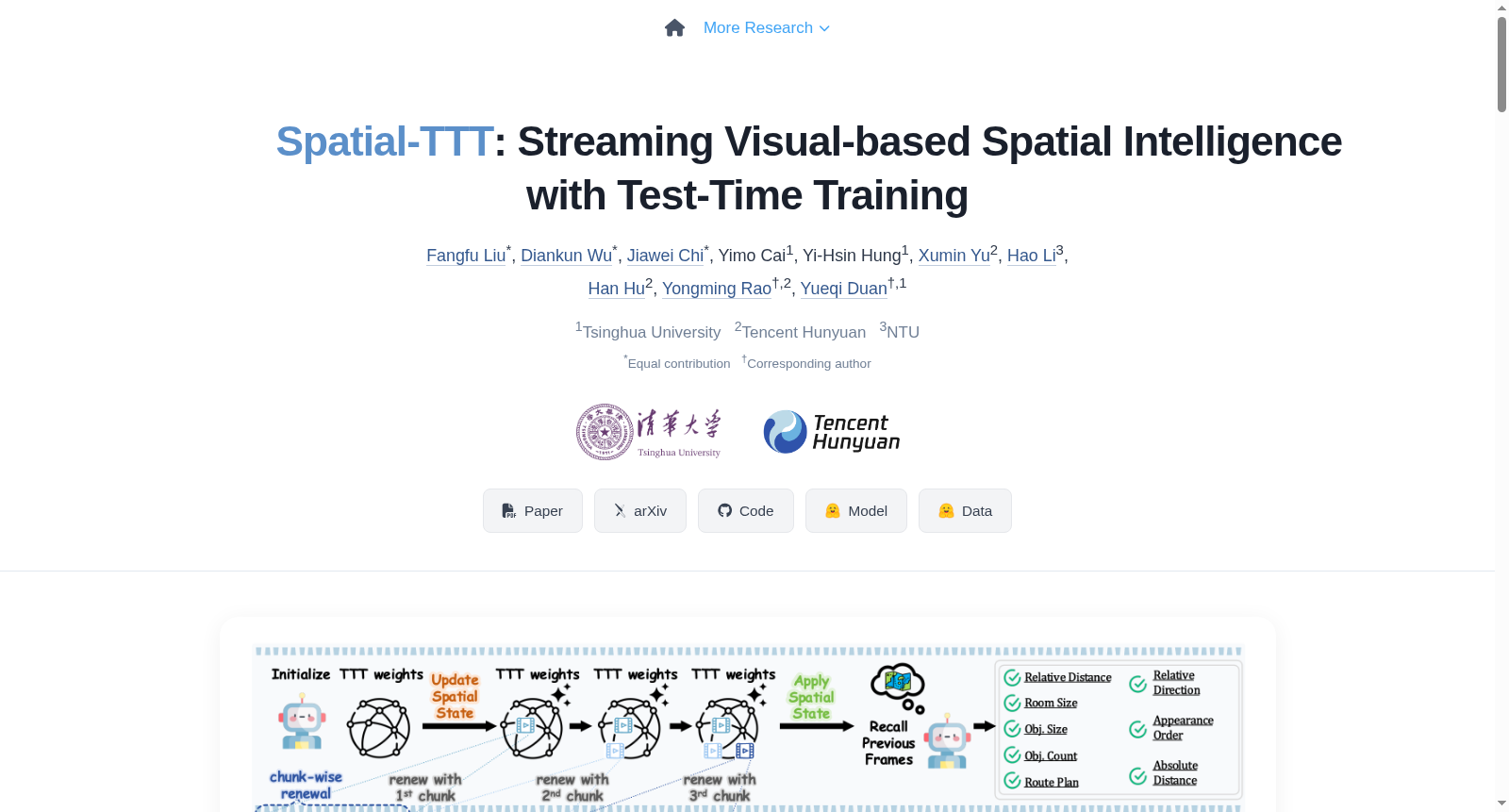
构建方式
在视觉空间智能领域,构建高质量数据集对于模型理解三维场景至关重要。该密集场景描述数据集源自SceneVerse提供的对象中心三维场景图,通过系统化处理ScanNet和ARKitScenes的室内场景重建数据,将原始网格与语义标注对齐,生成包含全局语境、物体类别与数量、空间布局及对象间关系的结构化描述。每个样本将空间视频流与连贯的场景漫游式描述配对,形成约1.6万个样本,为模型提供了覆盖全面的三维场景监督信号。
特点
该数据集的核心特征在于其密集且结构化的监督形式。与传统的稀疏空间问答数据不同,它要求模型生成涵盖场景类型、功能设定、物体枚举与精确计数以及空间关系的完整描述,从而提供高覆盖度的梯度信号。这种设计促使模型在长视频流中构建连贯且持久的三维记忆,特别强化了对全局语义描述符、实例级证据的保留能力以及对几何结构与对象间约束的编码效果,为流式空间理解奠定了坚实基础。
使用方法
在应用层面,该数据集主要用于训练测试时训练框架中的快速权重更新动态。模型接收空间视频流,并以大块更新的方式逐步处理视觉令牌,通过深度监督学习将全局三维场景信息结构化的编码到自适应记忆中。具体而言,数据集在第一阶段训练中初始化快速权重的三维感知能力,随后在第二阶段结合大规模空间视觉问答数据进行微调,使模型学会在流式观测中选择性保留任务相关的空间证据,并在推理时有效回忆与组织累积的空间知识,从而提升长时程空间理解与推理性能。
背景与挑战
背景概述
密集场景描述数据集由腾讯混元与清华大学的研究团队于2026年提出,旨在支持流式视觉空间智能的研究。该数据集构建于SceneVerse标注之上,包含约1.6万个样本,覆盖ScanNet与ARKitScenes等室内场景的三维重建数据。其核心研究问题在于解决现有空间问答数据监督稀疏、局部性强的问题,通过提供密集、全局的场景描述——包括场景类型、物体类别与数量、空间关系等结构化信息——为模型学习如何在长视频流中有效更新并维持三维空间记忆提供丰富梯度信号。这一数据集的创建显著推动了多模态大语言模型在流式空间理解任务上的进展,为机器人导航、增强现实等应用奠定了坚实基础。
当前挑战
该数据集致力于解决流式视觉空间智能中三维场景理解与记忆的挑战,其核心在于如何从长时、无界的视频流中持续积累并组织三维空间证据。具体挑战包括:在领域层面,现有空间问答数据通常仅针对局部区域或少量帧进行监督,答案简短且覆盖范围有限,导致模型难以学习构建连贯、持久的全局三维记忆;在构建过程中,需要从原始三维场景图生成全面、连贯的场景描述,确保描述既能涵盖全局上下文与物体实例,又能精确表达空间布局与几何关系,同时需保持与视频流的时序对齐,以提供有效的训练信号。
常用场景
经典使用场景
在视觉空间智能研究领域,密集场景描述数据集的核心应用场景在于训练和评估多模态大语言模型的长时程空间记忆与推理能力。该数据集通过提供包含全局场景类型、物体类别与数量、空间布局与关系等维度的密集三维场景描述,引导模型从连续的视频流中学习如何选择、组织和保留空间证据。具体而言,模型需要处理来自ScanNet和ARKitScenes等真实世界室内场景的长视频序列,并生成结构化的场景描述,这要求其具备从分散在数千帧中的空间线索进行渐进式聚合与记忆的能力。
衍生相关工作
该数据集的构建理念与方法衍生并推动了视觉空间智能领域一系列相关研究。其核心思想——通过密集监督引导模型学习长时程空间记忆更新——为后续研究提供了重要范式。基于类似的密集描述或结构化监督思路,研究者们开发了更多专注于特定空间能力(如跨视图一致性、遮挡推理)的数据集与训练方法。同时,该数据集所服务的Spatial-TTT框架本身,作为将测试时训练范式应用于视觉空间任务的先驱工作,也激励了后续研究探索更高效的在线适应架构、更优的时空归纳偏置注入方法,以及如何将类似的记忆更新机制扩展到其他需要长程上下文理解的视觉任务中。
数据集最近研究
最新研究方向
在视觉空间智能领域,密集场景描述数据集正成为推动流式空间理解的关键前沿。该数据集通过提供涵盖全局场景类型、物体计数与空间关系的密集三维描述,为模型在长时域视频流中构建结构化空间记忆提供了丰富监督信号。当前研究热点集中于结合测试时训练范式,使模型能够在线更新快速权重以动态累积空间证据,从而应对实际应用中因视角变化与物体遮挡带来的挑战。这一方向不仅显著提升了模型在VSI-Bench等空间基准上的性能,也为具身机器人、自动驾驶等需要持续空间感知的应用奠定了坚实基础,标志着空间智能从静态感知向动态流式理解的范式转变。
相关研究论文
- 1Spatial-TTT: Streaming Visual-based Spatial Intelligence with Test-Time Training清华大学; 腾讯混元; 南洋理工大学 · 2026年
以上内容由遇见数据集搜集并总结生成


