WritingBench
收藏WritingBench 数据集概述
数据集简介
WritingBench是一个全面的基准测试,用于评估大型语言模型(LLMs)在写作能力方面的表现。该数据集包含1,239个现实世界的查询,涵盖6个主要领域、100个细粒度子领域,并考虑了风格、格式和长度三个核心写作要求。每个查询平均包含1,546个标记。
数据集构成
- 主要领域:学术与工程、金融与商业、政治与法律、文学与艺术、教育、广告与营销
- 子领域:共100个,覆盖上述主要领域的细分
- 写作要求:风格、格式、长度
- 查询平均长度:1,546个标记
构建流程
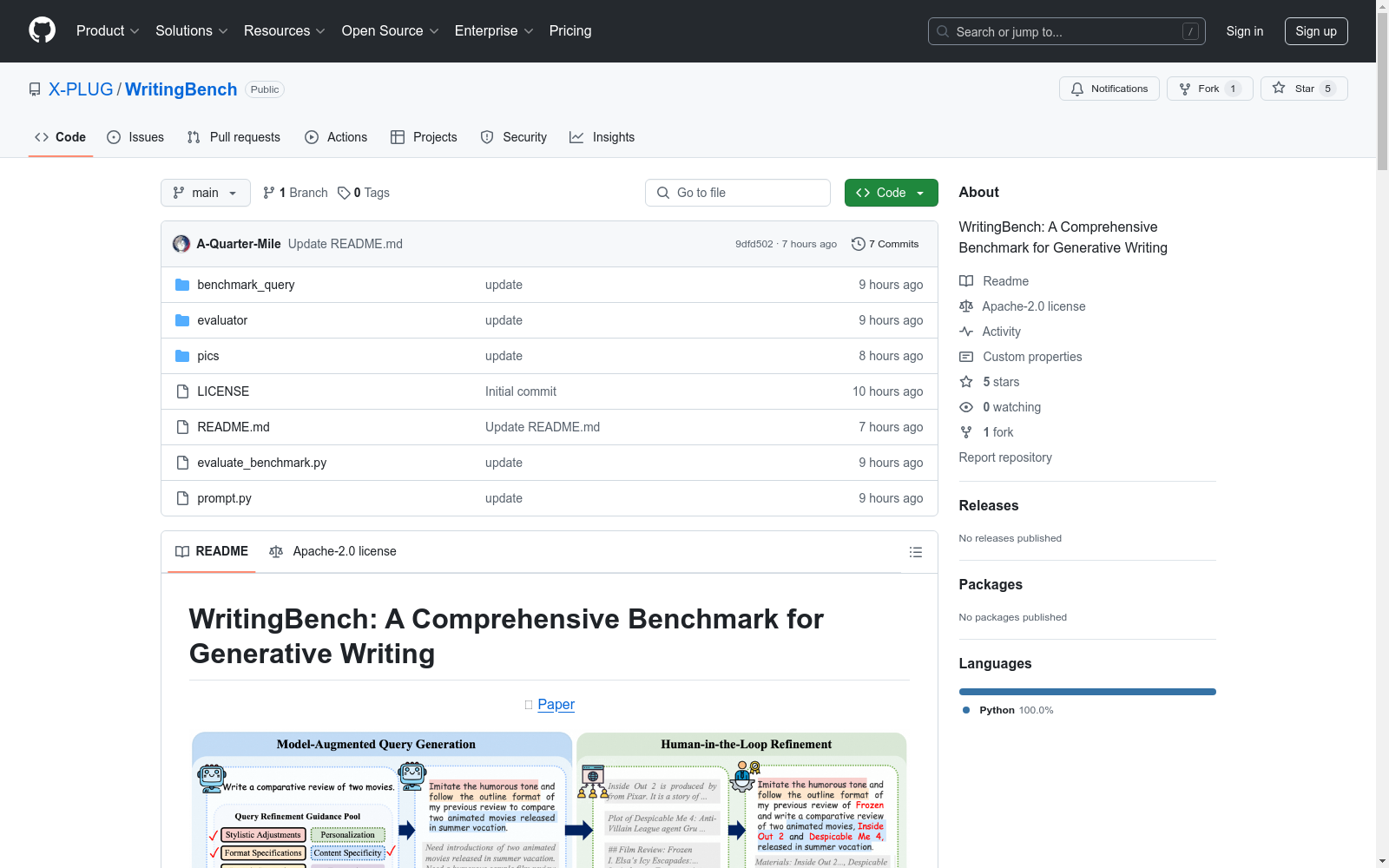
数据集的构建采用了模型增强查询生成和人工在环优化的混合管道,包括以下两个关键阶段:
模型增强查询生成
- 初始查询生成:利用LLMs从基于现实世界写作场景的两层领域池生成查询。
- 查询多样化:通过从查询优化指导池中随机选择策略,增强查询的多样性和实用性。
人工在环优化
- 材料收集:30名训练有素的注释者收集必要的开源材料。
- 专家筛选与优化:5名专家进行细致的两阶段过滤过程,包括查询适应和材料剪枝。
评估框架
评估框架包括动态标准生成和基于量表评分两个阶段。
动态标准生成
对于WritingBench中的每个查询$q$,LLM被提示自动生成一组五个评估标准。
量表评分
对于每个标准$c_i$,评估者独立地为响应$r$分配一个10点量表上的分数。
仓库结构
plaintext . ├── evaluate_benchmark.py # 评估脚本 ├── prompt.py # 模板提示 ├── evaluator/ │ ├── int.py │ └── llm.py # LLM评估接口 └── benchmark_query/ ├── benchmark_all.jsonl # 完整数据集(1239个查询) └── requirement/ ├── style/ # 风格特定子集 ├── format/ # 格式特定子集 └── length/ # 长度特定子集
引用
@misc{wu2025writingbench, title={WritingBench: A Comprehensive Benchmark for Generative Writing}, author={Yuning Wu and Jiahao Mei and Ming Yan and Chenliang Li and SHaopeng Lai and Yuran Ren and Zijia Wang and Ji Zhang and Mengyue Wu and Qin Jin and Fei Huang}, year={2025}, url={https://arxiv.org/abs/2503.05244}, }