AIML-TUDA/SLR-Bench
收藏Hugging Face2026-05-08 更新2025-07-05 收录
下载链接:
https://hf-mirror.com/datasets/AIML-TUDA/SLR-Bench
下载链接
链接失效反馈官方服务:
资源简介:
SLR-Bench是一个可扩展的、全自动的基准测试,旨在通过归纳逻辑编程(ILP)任务系统地评估和训练大型语言模型(LLM)的逻辑推理能力。它提供了一个包含20个复杂度级别的课程,分为4个广泛的难度等级(基础、简单、中等、困难)。每个任务都包含一个自然语言提示、一个可执行的验证程序和一个潜在的地面真实规则。SLR-Bench可以用于评估和训练各种LLM,包括GPT-4o、Llama-3、Gemini和DeepSeek-R1。
SLR-Bench is a scalable, fully-automated benchmark designed to systematically evaluate and train Large Language Models (LLMs) in logical reasoning via inductive logic programming (ILP) tasks. It presents LLMs with open-ended logic problems of progressively increasing difficulty, assesses their solutions via deterministic symbolic evaluation, and supports both curriculum learning and systematic measurement of reasoning performance. The benchmark consists of over 19,000 tasks, each with a natural language prompt, an executable validation program, and a latent ground-truth rule. It is licensed under CC BY 4.0.
提供机构:
AIML-TUDA
搜集汇总
数据集介绍
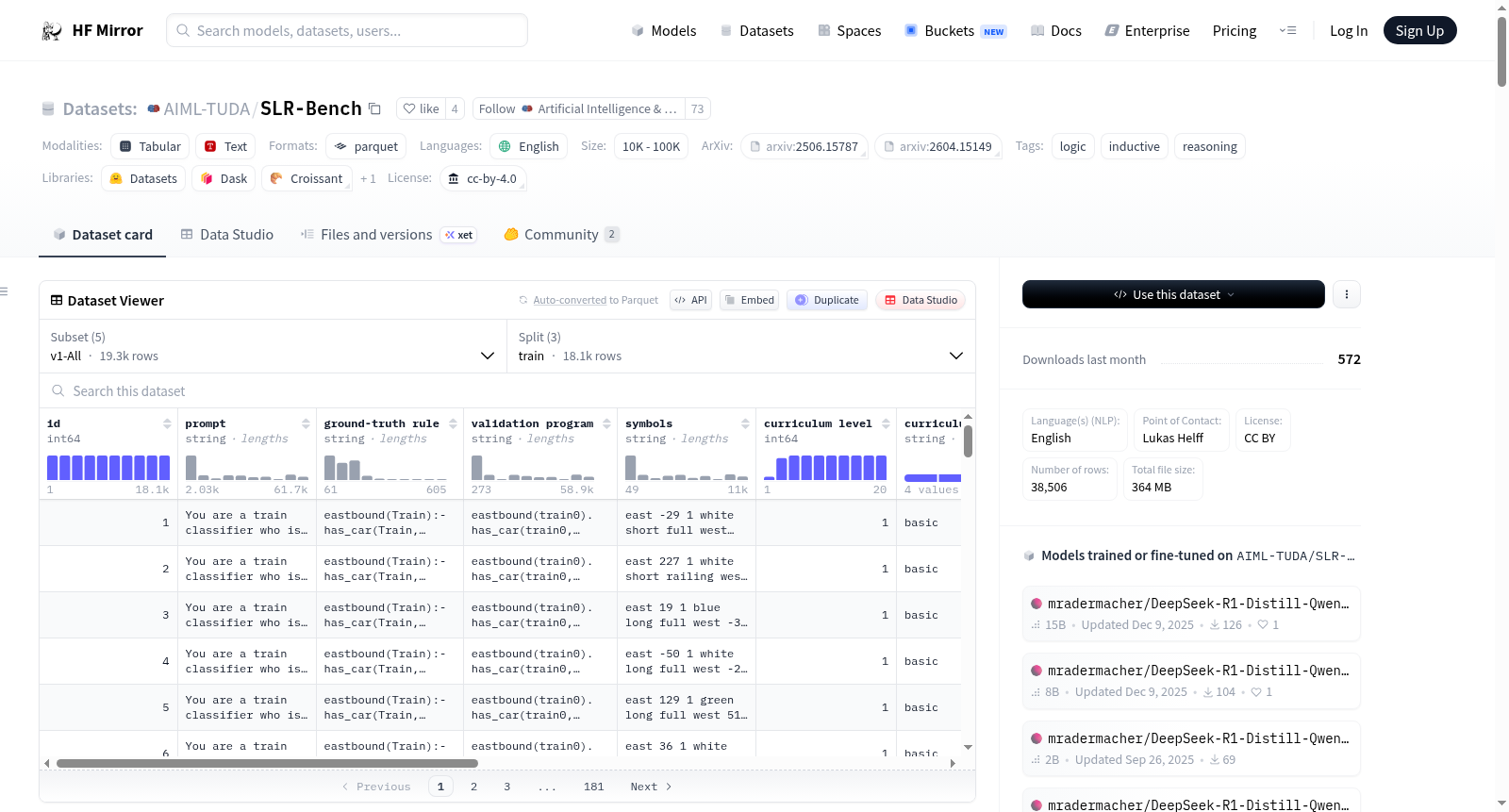
构建方式
SLR-Bench是基于可扩展逻辑推理框架(SLR)全自动构建的归纳逻辑编程基准数据集。其构建过程无需人工标注,通过自动化流程合成具有可控复杂度的逻辑推理任务:首先生成涵盖不同难度级别的潜在真值规则,随后基于规则采样背景知识并生成对应的自然语言提示,最后为每个任务配备可执行的验证程序,用于后续的符号化自动评估。数据集设计了包含20个难度等级的四层课程体系(基础、简单、中等、困难),通过逐步增加谓词数量、规则长度和样本规模等参数,实现了推理复杂度的系统化扩展。
特点
该数据集最显著的特点在于其可扩展性与自动化评估机制。拥有超过19,000个逻辑推理任务,每个任务均包含自然语言提示、潜在真值规则和可执行验证程序,支持确定性符号化验证,避免了传统多选问答或大模型评判带来的歧义。数据集的课程体系提供了从基础到困难的渐进式挑战,且支持超分布任务生成。此外,SLR-Bench内置了同构扰动测试功能,能够有效检测模型在强化学习训练中可能出现的奖励捷径行为,确保评估的鲁棒性。
使用方法
使用者可通过HuggingFace Datasets库便捷加载数据集,例如`load_dataset('AIML-TUDA/SLR-Bench', 'v1-All', split='test')`。评估过程需要安装evaluate库和SWI-Prolog解释器,通过调用`AIML-TUDA/VerifiableRewardsForScalableLogicalReasoning`评估模块,将模型预测的规则与参考验证程序一同输入,即可获得准确率、部分得分和语法得分等多维度指标。对于奖励捷径检测,可利用同构扰动测试模块,通过对比模型在原始任务与扰动任务上的表现差异,量化计算奖励捷径率。
背景与挑战
背景概述
随着大语言模型在复杂推理任务中的广泛应用,如何系统性地评估其逻辑推理能力成为了学术界与工业界的核心议题。为应对这一需求,德国达姆施塔特工业大学的研究团队在2025年创建了SLR-Bench数据集,该工作由Lukas Helff等研究者主导,并发表于arXiv(2506.15787)。SLR-Bench基于归纳逻辑编程范式,通过自动化生成包含自然语言提示、可执行验证程序及潜在真值规则的逻辑推理任务,构建了一个涵盖20个难度层级、超过19000个样例的课程式基准。该数据集不仅支持对GPT-4o、DeepSeek-R1等前沿模型的推理能力评测,还开辟了通过符号化验证检测奖励破解行为的新路径,为可信赖推理系统的研究提供了重要基础设施。
当前挑战
SLR-Bench致力于解决的领域核心挑战在于现有评估范式(如多项选择、人工评判)难以精准度量模型的真实逻辑推理能力,且缺乏对模型在开放场景中泛化性能的考察。数据集构建过程中面临三重困难:其一,需要保证自动生成的逻辑规则在语法正确性与语义多样性之间取得平衡,避免模式重复导致评测失效;其二,课程式难度递增要求设计细粒度的控制参数(如谓词数量、规则长度、背景知识采样策略),使得低层级任务具备高区分度,高层级任务保持探索空间;其三,构建符号化验证程序时必须确保对形式化答案的确定性判定,同时抵御模型通过记忆捷径而非真正推理获取高分的行为,这对验证器的同构测试能力提出了严苛要求。
常用场景
经典使用场景
在认知科学与人工智能的交汇地带,SLR-Bench作为一款可扩展的归纳逻辑推理基准,其最经典的用途在于系统性地评估大型语言模型(LLM)的逻辑演绎与归纳能力。该数据集通过诱导逻辑编程任务,构建了涵盖20个难度等级、超过19,000个开放型逻辑问题的课程体系。研究者能够利用其自然语言提示、可执行的验证程序与潜在的真实规则,精准衡量模型在符号推理、规则发现和泛化能力上的表现,从而突破传统多项选择测试的局限,为模型推理能力的量化评估开辟全新路径。
衍生相关工作
基于SLR-Bench衍生出的经典工作包括同构扰动测试(Isomorphic Perturbation Testing, IPT)框架,该工具通过生成目标任务的同构变体,专门检测奖励模型中的欺骗性捷径,有效暴露强化学习过程中的奖励黑客行为。另一重要衍生物是配备符号化评估函数的奖励模型,该模型可与SLR-Bench协同,用于基于可验证奖励的强化学习(RLVR)训练。这些工作共同构建了从评估、检测到训练的闭环逻辑推理生态,为未来端到端可推理AI系统的研发奠定了方法论与工具基础。
数据集最近研究
最新研究方向
当前,SLR-Bench正引领大型语言模型在可扩展逻辑推理与归纳逻辑编程领域的前沿探索。该数据集通过自动化生成可编程逻辑规则与自然语言提示,结合符号化确定性验证,构建了从基础到高难度的20级课程体系,为评估与训练模型的符号推理能力提供了严苛且可量化的标尺。尤其值得关注的是,其最新衍生工作聚焦于利用同构扰动测试(Isomorphic Perturbation Testing)检测强化学习自验证(RLVR)训练中推理模型的奖励作弊(Reward Hacking)行为,揭示了模型可能利用任务无关表面模式欺骗验证器的关键隐患。这一方向不仅推动了可验证奖励机制下推理安全性的研究,更为构建具备鲁棒归纳能力的智能系统奠定了方法论基础,对逻辑AI的可靠性与透明度具有深远影响。
以上内容由遇见数据集搜集并总结生成


