bitmind/nano-banana
收藏Hugging Face2025-08-30 更新2025-09-13 收录
下载链接:
https://hf-mirror.com/datasets/bitmind/nano-banana
下载链接
链接失效反馈官方服务:
资源简介:
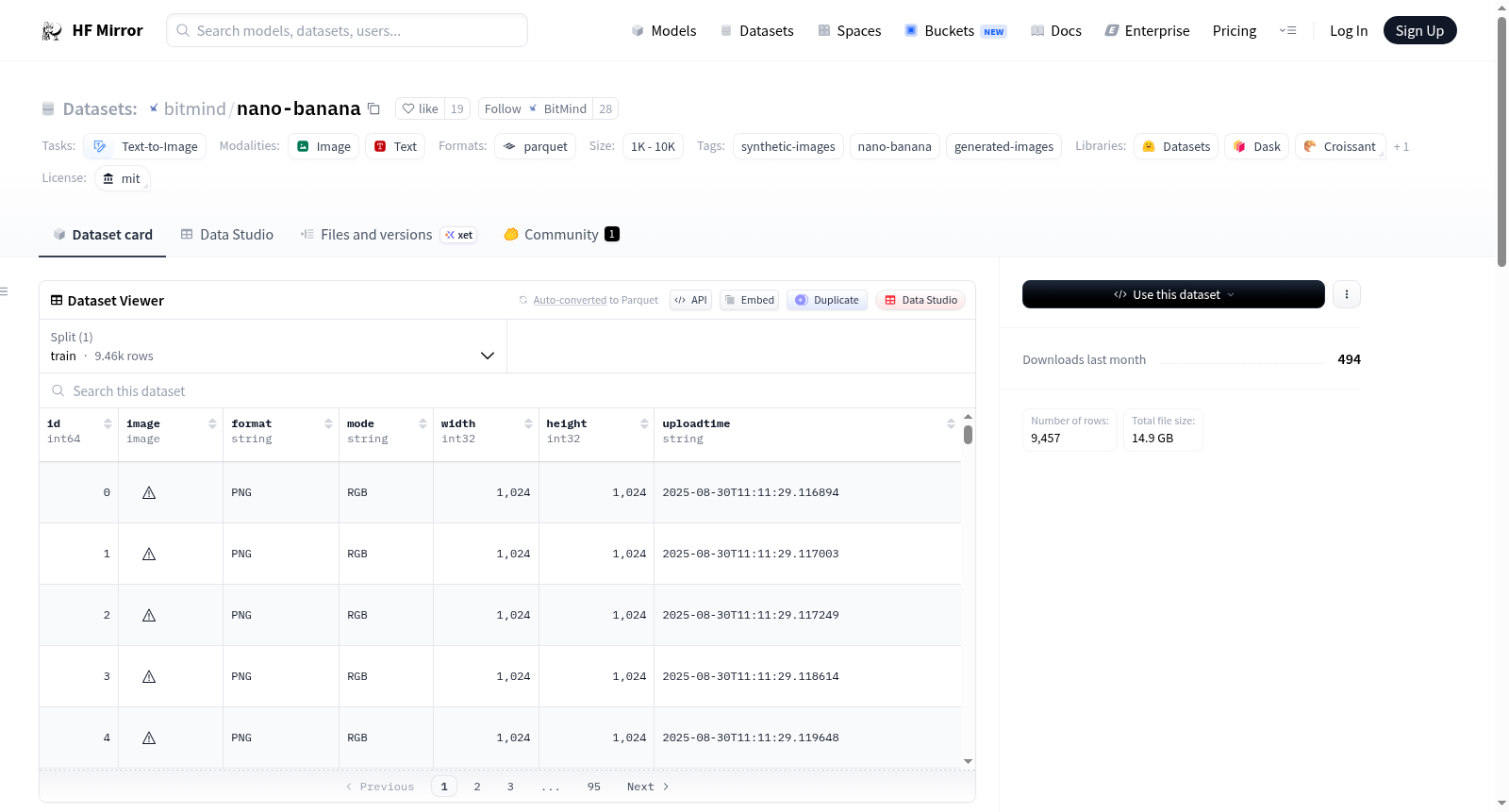
Nano-Banana生成图像数据集包含9457张通过Nano-Banana模型(Google Gemini 2.5 Flash Image Preview)生成的高质量图像。这些图像以优化的二进制格式存储,并采用非分块的Parquet文件组织方式。数据集的存储格式遵循MIT许可。
The Nano-Banana Generated Images dataset consists of 9,457 high-quality images produced using the Nano-Banana model (Google Gemini 2.5 Flash Image Preview). These images are stored in an optimized binary format and organized in normal non-chunked Parquet files. The dataset is licensed under MIT.
提供机构:
bitmind
搜集汇总
数据集介绍
构建方式
在生成式人工智能蓬勃发展的背景下,Nano-Banana数据集通过Google Gemini 2.5 Flash Image Preview模型,系统性地生成了9,457张高质量图像。其构建过程依托于前沿的文本到图像合成技术,将抽象的文本描述转化为具体的视觉内容。所有生成结果均以优化的二进制格式存储于大型Parquet文件中,确保了数据组织的规范性与存储的高效性,为视觉内容生成研究提供了结构化的资源基础。
特点
该数据集的核心特点在于其纯粹由先进生成模型合成的图像构成,规避了传统数据采集涉及的版权与隐私问题。每张图像均附带详尽的元数据,包括唯一标识符、图像格式、色彩模式及像素尺寸,形成了完整的数据描述体系。其采用的高效二进制存储方案,避免了Base64编码带来的额外开销,使得图像能够被快速加载为可直接操作的PIL对象,极大提升了数据访问与处理的便捷性。
使用方法
利用Hugging Face的`datasets`库,研究者可以便捷地加载此数据集。加载后,图像数据无需手动解码即可作为PIL Image对象直接访问,支持即时预览与操作。通过迭代数据集,研究者能够轻松获取每一张图像及其对应的格式、尺寸等元信息。这种无缝集成的工作流程,使得该数据集能够直接服务于图像生成模型的评估、下游视觉任务的微调,或作为高质量合成图像的基准分析资源。
背景与挑战
背景概述
在生成式人工智能迅猛发展的浪潮中,高质量合成图像数据集的构建成为推动模型评估与创新的关键基石。Nano-Banana Generated Images数据集由bitmind团队于近期创建,其核心依托于Google Gemini 2.5 Flash Image Preview模型,旨在生成并汇集近万张高保真图像。该数据集聚焦于文本到图像生成领域,为研究者提供了由前沿多模态大模型直接产出的标准化视觉素材,其MIT开源许可进一步促进了生成式AI,特别是图像合成技术在公平性、可控性及质量评估等方面的探索与应用。
当前挑战
该数据集致力于应对文本到图像生成领域中,模型输出结果的真实性、多样性与可控性评估等核心挑战。具体而言,如何量化生成图像与自然图像的分布差异,以及如何确保生成内容在复杂语义下的忠实度,是亟待解决的学术问题。在构建层面,挑战主要源于大规模合成数据的高效存储与无损管理。数据集采用优化的二进制格式与Parquet文件组织,旨在克服传统Base64编码带来的存储膨胀与加载延迟,实现从压缩存储到可直接使用的PIL图像对象的无缝、快速解码,这对大规模生成数据的工程化处理提出了精细的技术要求。
常用场景
经典使用场景
在生成式人工智能领域,高质量图像数据集是评估和比较不同文本到图像模型性能的基石。Nano-Banana数据集凭借其近万张由Google Gemini 2.5 Flash Image Preview模型生成的图像,为研究者提供了一个标准化的基准测试平台。该数据集常被用于定量分析生成模型的保真度、多样性与创造性,通过计算如FID、IS等指标,客观衡量模型在视觉内容合成方面的能力。
实际应用
在实际应用层面,Nano-Banana数据集可作为训练数据增强的来源,或用于开发下游视觉任务的原型系统。例如,在创意设计、广告素材生成或教育内容制作中,该数据集能辅助构建更鲁棒的图像生成流水线。其优化的二进制存储格式与即用的PIL图像对象,极大提升了工程部署效率,使得快速集成与测试成为可能。
衍生相关工作
围绕该数据集,已衍生出若干聚焦于生成模型微调、跨模态检索以及图像质量评估的经典研究工作。这些工作通常以Nano-Banana作为基准或辅助数据集,探索提示词工程对生成结果的影响、研究不同模型架构的迁移学习效果,或开发新的无参考图像质量评估指标,共同推动了文本到图像合成技术的生态发展。
以上内容由遇见数据集搜集并总结生成


