MCGA
收藏Hugging Face2026-01-16 更新2026-01-17 收录
下载链接:
https://huggingface.co/datasets/yxdu/MCGA
下载链接
链接失效反馈官方服务:
资源简介:
MCGA(多任务古典中国文学体裁音频语料库)是第一个专注于古典中国文学研究的大规模、开源、完全版权的音频语料库,包含119小时(22,000个样本)的标准普通话录音,涵盖了五个主要文学体裁(赋、诗、文、词、曲)和11个历史时期。该数据集旨在支持六个核心语音相关任务,包括自动语音识别(ASR)、语音到文本翻译(S2TT)、语音情感标注(SEC)、口语问答(SQA)、语音理解(SU)和语音推理(SR),以弥补领域特定音频资源的不足,并提升多模态大语言模型的多维能力。
创建时间:
2026-01-14
原始信息汇总
MCGA 数据集概述
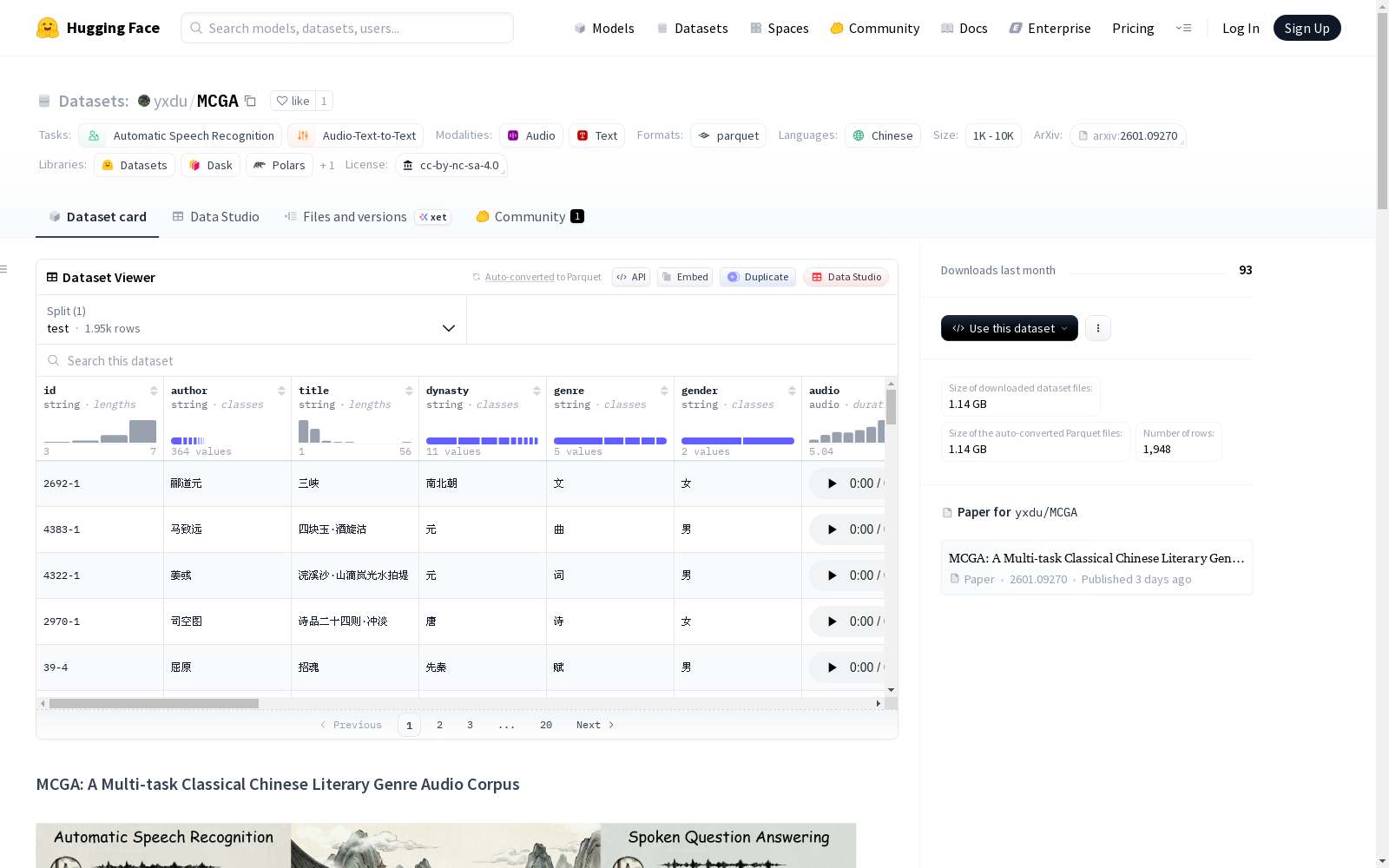
数据集基本信息
- 数据集名称:MCGA (Multi-task Classical Chinese Literary Genre Audio Corpus)
- 语言:中文
- 数据规模:包含 22,000 个音频样本,总时长约 119 小时。
- 数据划分:包含训练集、验证集和测试集。当前仅公开发布测试集用于公平基准测试。
- 音频来源:由母语者录制(13 位男性和 15 位女性)。
- 领域:中国古典文学研究。
- 文学体裁:涵盖赋 (Fu)、诗 (Shi)、文 (Wen)、词 (Ci)、曲 (Qu) 五种主要体裁。
- 支持任务:自动语音识别 (ASR)、语音到文本翻译 (S2TT)、语音情感描述 (SEC)、口语问答 (SQA)、语音理解 (SU)、语音推理 (SR)。
- 许可证:CC BY-NC-SA-4.0。
数据集结构
- 当前可用分片:
test - 测试集样本数:1948 个示例。
- 下载大小:约 1,138,130,667 字节。
- 数据集大小:约 1,272,025,700.996 字节。
数据特征
数据集包含以下字段:
id:样本标识符。author:作者。title:作品标题。dynasty:朝代。genre:文学体裁。gender:朗读者性别。audio:音频数据。asr:自动语音识别相关文本。s2tt:语音到文本翻译相关文本。sec_1,sec_2,sec_3:语音情感描述相关文本。sqa,sqa_a:口语问答相关文本。su,su_a:语音理解相关文本。sr,sr_a:语音推理相关文本。time:时间信息。asr_split,s2tt_split,sec_split,sqa_split,su_split,sr_split:各任务对应的数据划分标识。
相关资源
- Hugging Face 数据集页面:https://huggingface.co/datasets/yxdu/MCGA
- 论文地址:https://arxiv.org/abs/2601.09270
- GitHub 仓库:https://github.com/yxduir/MCGA
引用信息
如需引用,请使用提供的 BibTeX 条目。
搜集汇总
数据集介绍
构建方式
在古典文学与语音技术交叉领域,MCGA数据集的构建体现了严谨的学术方法。其核心内容源自中国古典文学经典,涵盖赋、诗、文、词、曲五大文类,横跨十一个历史时期。为确保语音质量与版权清晰,数据集由二十八位以标准普通话为母语的发音人(十三位男性与十五位女性)进行专业录制,最终形成包含两万两千个样本、总计一百一十九小时的音频语料。构建过程特别设计了针对自动语音识别、语音到文本翻译、语音情感描述、口语问答、语音理解与语音推理六项核心任务的标注体系,为多模态大语言模型在专业领域的应用奠定了高质量的数据基础。
特点
MCGA数据集在古典中文语音资源领域具有鲜明的特色。其首要特征在于领域专精性,它是首个大规模、开源且版权完备的古典文学研究专用音频语料库。数据覆盖了从先秦至清代的主要文学体裁与历史分期,提供了丰富的时空与文体维度。技术层面,数据集为每段音频配备了精细的多任务标注,包括自动语音识别文本、翻译文本、情感描述、问题与答案、理解与推理内容等,形成了一个支持六项语音中心任务的统一评估基准。这种多任务、多模态的设计结构,使其能够全面评估模型在复杂语境下的综合认知与推理能力。
使用方法
该数据集为研究者提供了标准化的使用流程。用户首先需克隆项目仓库并配置指定的Python虚拟环境与依赖。数据集的核心用途在于对支持音频的多模态大语言模型进行多任务评估。通过执行提供的推理脚本,用户可以指定模型、任务列表、输入模态及数据划分等参数,在本地或远程服务器上启动评估流程。目前公开的测试集主要用于公平的基准评测,支持自动语音识别、语音到文本翻译、语音情感描述、口语问答、语音理解与语音推理全部六项任务。完整的训练与验证集将在后续发布,以支持更广泛的模型训练与微调研究。
背景与挑战
背景概述
在古典文学与计算语言学交叉领域,长期以来缺乏高质量、多任务导向的音频数据集,制约了语音技术在文化遗产数字化中的应用。MCGA数据集由Yexing Du等研究人员于2026年构建,作为首个大规模、开源且版权完备的古典中文文学体裁音频语料库,其核心研究问题在于如何通过多模态数据推动古典文学研究的智能化进程。该数据集涵盖赋、诗、文、词、曲五种主要文学体裁,跨越十一个历史时期,包含119小时由母语者录制的标准普通话音频,旨在支持自动语音识别、语音到文本翻译、语音情感标注、口语问答、语音理解与推理等六项核心任务,为多模态大语言模型在特定领域的多维能力提升奠定了数据基础。
当前挑战
MCGA数据集致力于解决古典中文文学音频多任务处理的复杂挑战,其首要难题在于古典文学语言的深奥性与语音表达的多样性,要求模型不仅能准确识别语音内容,还需理解文学体裁特有的韵律、情感及文化内涵。构建过程中,研究人员面临数据采集与标注的双重困难:一方面,需招募专业朗读者以确保发音的准确性与文学风格的忠实呈现;另一方面,针对六项不同任务设计精细的标注体系,如情感标注需捕捉古典诗文中的微妙情绪,而推理任务则要求对文学背景与逻辑关系进行深度解析,这些过程均需耗费大量人力与专业知识,并需保证标注的一致性与学术严谨性。
常用场景
经典使用场景
在古典文学与计算语言学交叉领域,MCGA数据集为多模态大语言模型提供了关键资源,其经典使用场景集中于对古典汉语文学音频的全面分析。该数据集通过涵盖赋、诗、文、词、曲五种文体及十一个历史时期的标准化录音,支持自动语音识别、语音到文本翻译、语音情感标注、口语问答、语音理解与推理等六项核心任务,使研究者能够系统评估模型在复杂声学与语义环境下的表现,为古典文献的数字化保存与智能处理奠定基础。
解决学术问题
MCGA数据集有效解决了古典汉语研究领域长期存在的音频资源匮乏问题,填补了专业语音语料库的空白。它通过提供大规模、多任务标注的音频数据,促进了跨模态学习在古典文学中的应用,使得自动化的文本转录、情感分析与内容理解成为可能,从而推动了计算人文领域的方法创新,并为文化遗产的数字化传承提供了可靠的技术支撑。
衍生相关工作
基于MCGA数据集,学术界已衍生出一系列经典研究工作,主要集中在多模态大语言模型的性能优化与领域适应方面。例如,研究者利用其多任务标注特性,开发了针对古典汉语语音的端到端识别与翻译模型;同时,该数据集也激发了在语音情感分析、跨模态推理等子任务上的算法创新,为后续在计算语言学与数字人文领域的交叉研究提供了重要的基准与灵感来源。
以上内容由遇见数据集搜集并总结生成


