Burmese-Classics-OCR-RAW
收藏Hugging Face2025-09-04 更新2025-09-05 收录
下载链接:
https://huggingface.co/datasets/minthanthtoo-cs/Burmese-Classics-OCR-RAW
下载链接
链接失效反馈官方服务:
资源简介:
缅甸(缅甸语)书籍数据集 - 缅甸经典OCR(每日滚动项目),为AI、OCR和NLP研究提供日常滚动数据集。每个条目包含OCR文本及其元数据,如标题、作者、页码索引和缅甸字符比例。
创建时间:
2025-08-31
原始信息汇总
Burmese-Classics-OCR-RAW 数据集概述
数据集基本信息
- 语言:缅甸语(my)
- 主要用途:OCR、缅甸语NLP、文本研究
- 许可证:Apache 2.0
- 数据格式:Parquet分片(约200MB每个)
数据内容
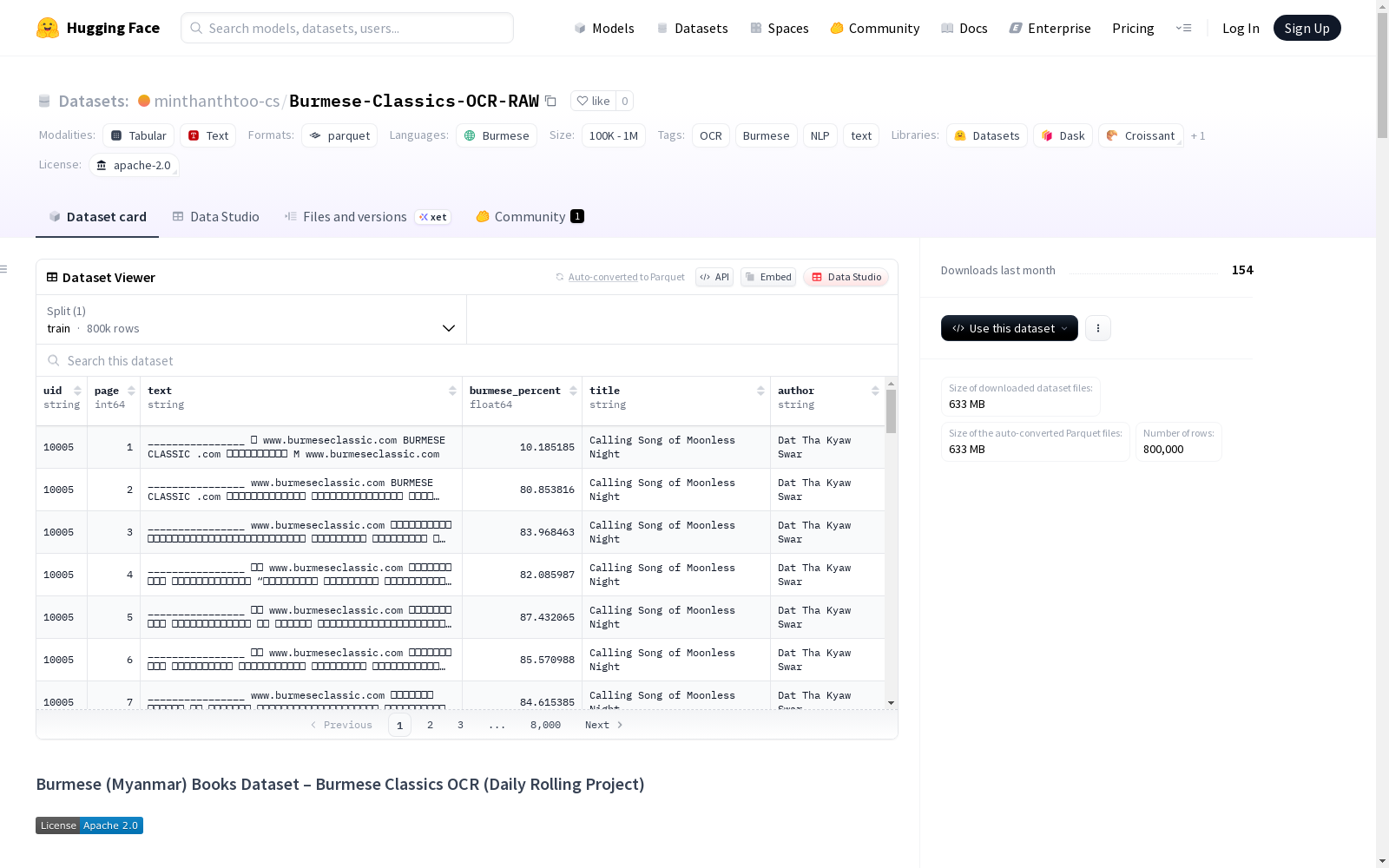
每个数据记录包含以下字段:
uid:唯一标识符(由Burmese Classics Online网站分配)title:书籍标题author:书籍作者page:页码索引(从1开始)burmese_percent:页面中缅甸字符的比例text:页面的OCR文本内容
数据规模(截至第3个Parquet文件)
- 书籍数量:4,516本
- 总页数:733,080页
- 缅甸字符数量:882,472,245个
- 估计词元数量:约552M个
类别统计
数据集包含23个书籍类别,主要类别包括:
- Technical:1,891本书
- Language:4,165本书
- Novel:3,770本书
- Religion:2,725本书
- Newspaper/Journal:14,472本书
总计24,240本书,2,903,645页,估计词元约1.63B个
数据访问方式
可通过Hugging Face的datasets库访问: python from datasets import load_dataset dataset = load_dataset("minthanthtoo-cs/Burmese-Classics-OCR-RAW")
处理说明
- 每本书包含约3k–100k个缅甸字符
- 仅包含达到最低缅甸语内容阈值的书籍
- 数据集每日滚动更新,新增书籍
许可证信息
使用Apache 2.0许可证,允许使用、修改和重新分发,但需要署名。
数据来源
数据来源于Burmese Classics Online网站,是该网站最大的自由访问缅甸书籍档案的衍生作品。
搜集汇总
数据集介绍
构建方式
在缅甸语自然语言处理资源稀缺的背景下,该数据集通过系统化采集缅甸古典在线档案馆的公开领域文献构建而成。采用光学字符识别技术逐页提取文本内容,并保留原始文档结构信息。每一条记录均包含唯一标识符、书名、作者、页码及缅文字符占比等元数据,以JSONL格式存储后转换为Parquet分片,确保数据的高效访问与扩展性。
特点
数据集涵盖小说、宗教、历史等23个主题类别,包含约24000本书籍、290万页文本及16亿预估词汇量。其突出特点在于每页均标注缅文字符比例,便于筛选高质量语言数据。采用滚动更新机制,每日新增文献内容,且通过排除技术类、报刊类等英文主导类别,显著提升了缅语文本的纯净度与实用性。
使用方法
研究者可通过Hugging Face的datasets库直接加载该数据集,支持按分片自动划分训练集。利用Parquet列式存储特性可实现快速元数据过滤与文本检索。典型应用场景包括缅语OCR模型优化、语言模型训练及文献数字化研究,使用时需注意数据滚动更新特性,建议结合缅文字符比例阈值进行样本质量控制。
背景与挑战
背景概述
缅甸古典光学字符识别原始数据集由minthanthtoo-cs团队构建,旨在应对缅甸语自然语言处理资源匮乏的现状。该数据集源于缅甸古典在线图书馆这一最大开放缅文文献库,通过系统化采集与处理,形成了包含约18,000册书籍、200万页面及30亿字符的大规模语料库。其核心价值在于为低资源语言的人工智能研究提供了首个可公开获取的高质量缅文文本基准,显著推动了东南亚语言信息处理技术的发展。
当前挑战
该数据集主要面临双重挑战:在领域问题层面,需解决缅甸语复杂文字结构导致的字符分割误差、传统印刷体与手写体混合识别、以及方言词汇与古缅文并存的语言学难题;在构建过程中,克服了原始文献数字化质量参差不齐、多源异构数据标准化处理、以及持续增量更新带来的版本一致性维护等工程技术障碍。
常用场景
经典使用场景
在缅甸语自然语言处理研究中,该数据集为光学字符识别技术提供了关键训练资源。研究者利用其包含的百万级页面文本,构建高精度缅文字符识别模型,特别适用于处理传统印刷书籍的数字化转换。数据集的结构化元数据支持针对特定文献类型或作者的专项研究,为低资源语言处理树立了典范。
解决学术问题
该数据集有效解决了缅甸语学术资源稀缺的核心问题,为计算语言学提供了大规模标注语料。其包含的882百万字符文本填补了东南亚语言模型训练的空白,支持词汇统计、语法分析和语义建模等基础研究。通过提供开放获取的公共领域文本,降低了缅甸语NLP研究的门槛,促进了跨语言信息处理技术的发展。
衍生相关工作
基于该数据集衍生了多项重要研究,包括缅甸语神经机器翻译系统的开发、跨语言预训练模型的构建以及低资源语言OCR优化算法。这些工作显著提升了东南亚语言处理的技术水平,其中部分成果已应用于商业文本处理平台,形成了从学术研究到产业应用的完整创新链。
以上内容由遇见数据集搜集并总结生成


